 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cell Must Go On: Agar.io for Continual Reinforcement Learning
May 23, 2025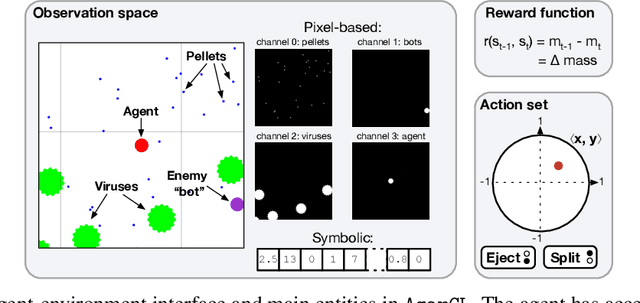
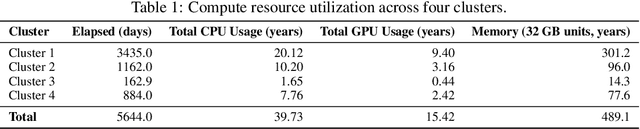
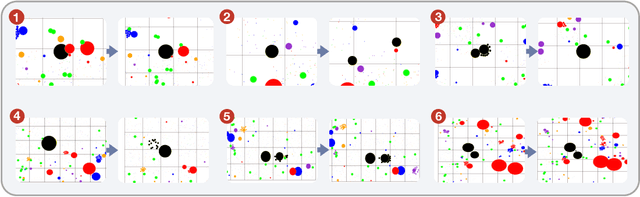

Continual reinforcement learning (RL) concerns agents that are expected to learn continually, rather than converge to a policy that is then fixed for evaluation. Such an approach is well suited to environments the agent perceives as changing, which renders any static policy ineffective over time. The few simulators explicitly designed for empirical research in continual RL are often limited in scope or complexity, and it is now common for researchers to modify episodic RL environments by artificially incorporating abrupt task changes during interaction. In this paper, we introduce AgarCL, a research platform for continual RL that allows for a progression of increasingly sophisticated behaviour. AgarCL is based on the game Agar.io, a non-episodic, high-dimensional problem featuring stochastic, ever-evolving dynamics, continuous actions, and partial observability. Additionally, we provide benchmark results reporting the performance of DQN, PPO, and SAC in both the primary, challenging continual RL problem, and across a suite of smaller tasks within AgarCL, each of which isolates aspects of the full environment and allow us to characterize the challenges posed by different aspects of the game.