 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the relevance of language in speaker recognition
Mar 04, 2022
This paper presents a new database collected from a bilingual speakers set (49), in two different languages: Spanish and Catalan. Phonetically there are significative differences between both languages. These differences have let us to establish several conclusions on the relevance of language in speaker recognition, using two methods: vector quantization and covariance matrices
Nonlinear predictive models computation in ADPCM schemes
Mar 03, 2022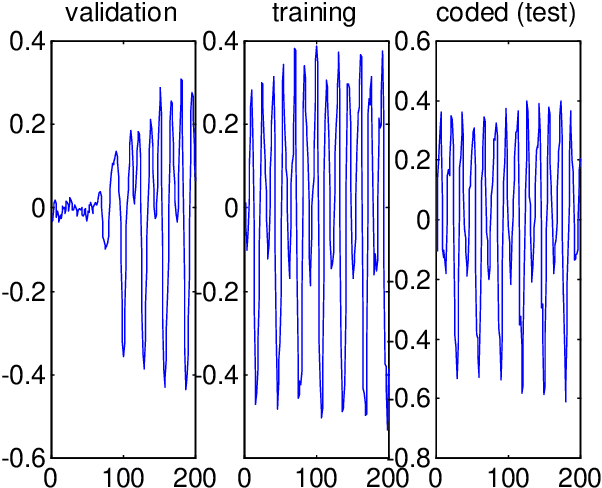
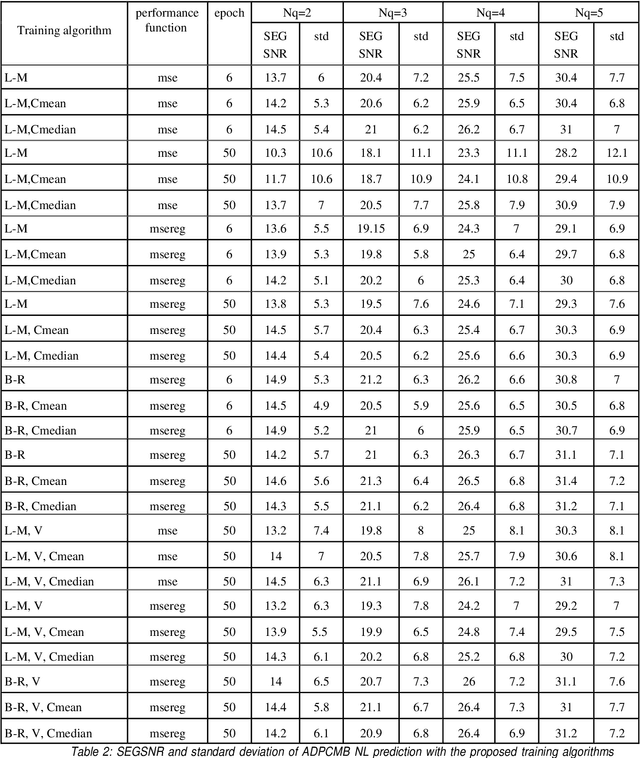
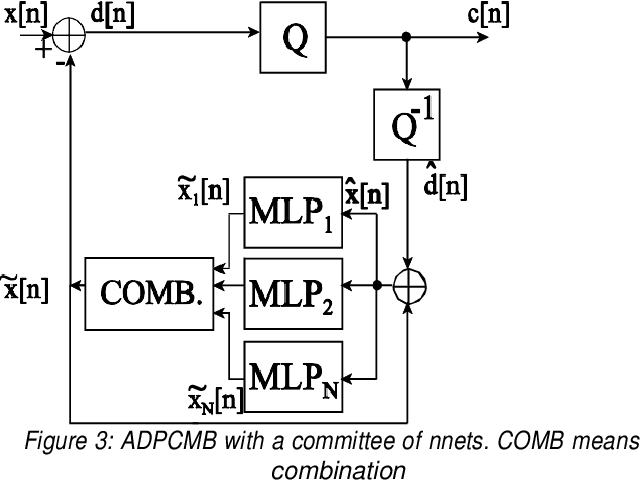
Recently several papers have been published on nonlinear prediction applied to speech coding. At ICASSP98 we presented a system based on an ADPCM scheme with a nonlinear predictor based on a neural net. The most critical parameter was the training procedure in order to achieve good generalization capability and robustness against mismatch between training and testing conditions. In this paper, we propose several new approaches that improve the performance of the original system in up to 1.2dB of SEGSNR (using bayesian regularization). The variance of the SEGSNR between frames is also minimized, so the new scheme produces a more stable quality of the output.
Online handwriting, signature and touch dynamics: tasks and potential applications in the field of security and health
Feb 24, 2022

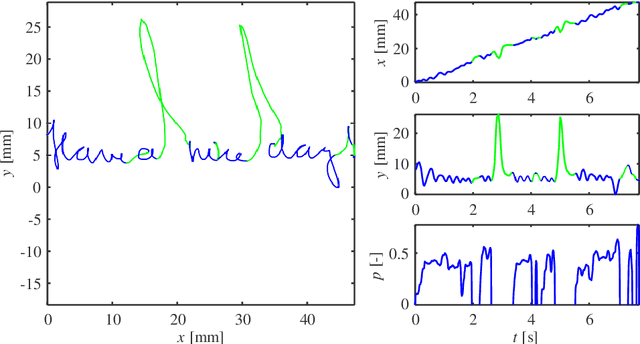
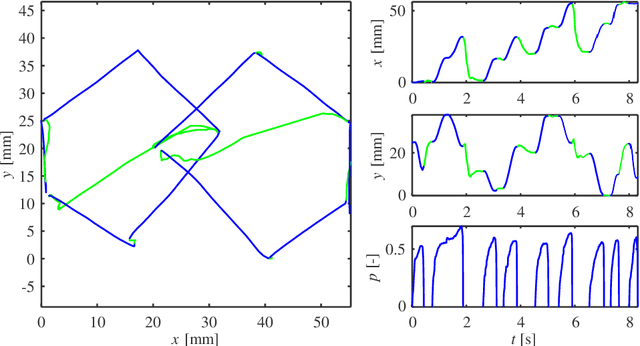
Background: An advantageous property of behavioural signals ,e.g. handwriting, in contrast to morphological ones, such as iris, fingerprint, hand geometry, etc., is the possibility to ask a user for a very rich amount of different tasks. Methods: This article summarises recent findings and applications of different handwriting and drawing tasks in the field of security and health. More specifically, it is focused on on-line handwriting and hand-based interaction, i.e. signals that utilise a digitizing device (specific devoted or general-purpose tablet/smartphone) during the realization of the tasks. Such devices permit the acquisition of on-surface dynamics as well as in-air movements in time, thus providing complex and richer information when compared to the conventional pen and paper method. Conclusions: Although the scientific literature reports a wide range of tasks and applications, in this paper, we summarize only those providing competitive results (e.g. in terms of discrimination power) and having a significant impact in the field.
* 27 pages
The effect of fatigue on the performance of online writer recognition
Feb 24, 2022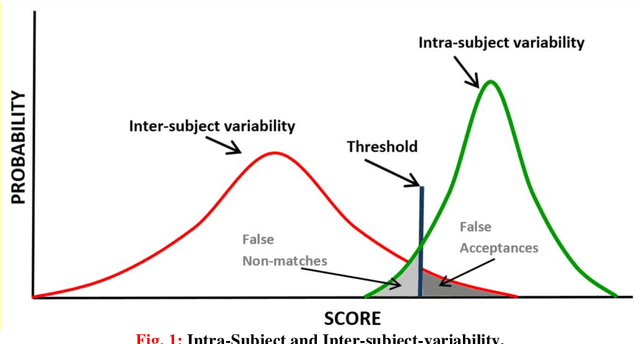



Background: The performance of biometric modalities based on things done by the subject, like signature and text-based recognition, may be affected by the subject state. Fatigue is one of the conditions that can significantly affect the outcome of handwriting tasks. Recent research has already shown that physical fatigue produces measurable differences in some features extracted from common writing and drawing tasks. It is important to establish to which extent physical fatigue contributes to the intra-person variability observed in these biometric modalities and also to know whether the performance of recognition methods is affected by fatigue. Goal: In this paper we assess the impact of fatigue on intra-user variability and on the performance of signature-based and text-based writer recognition approaches encompassing both identification and verification. Methods: Several signature and text recognition methods are considered and applied to samples gathered after different levels of induced fatigue, measured by metabolic and mechanical assessment and, also by subjective perception. The recognition methods are Dynamic Time Warping and Multi Section Vector Quantization, for signatures, and Allographic Text-Dependent Recognition for text in capital letters. For each fatigue level, the identification and verification performance of these methods is measured. Results: Signature shows no statistically significant intra-user impact, but text does. On the other hand, performance of signature-based recognition approaches is negatively impacted by fatigue whereas the impact is not noticeable in text-based recognition, provided long enough sequences are considered.
Handwriting Biometrics: Applications and Future Trends in e-Security and e-Health
Feb 24, 2022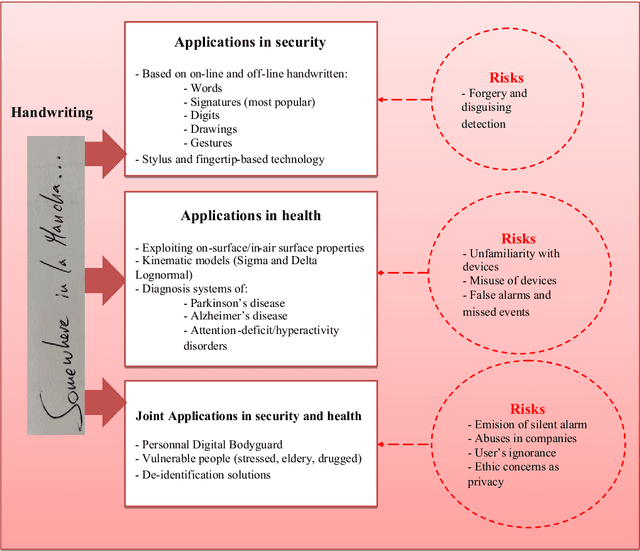

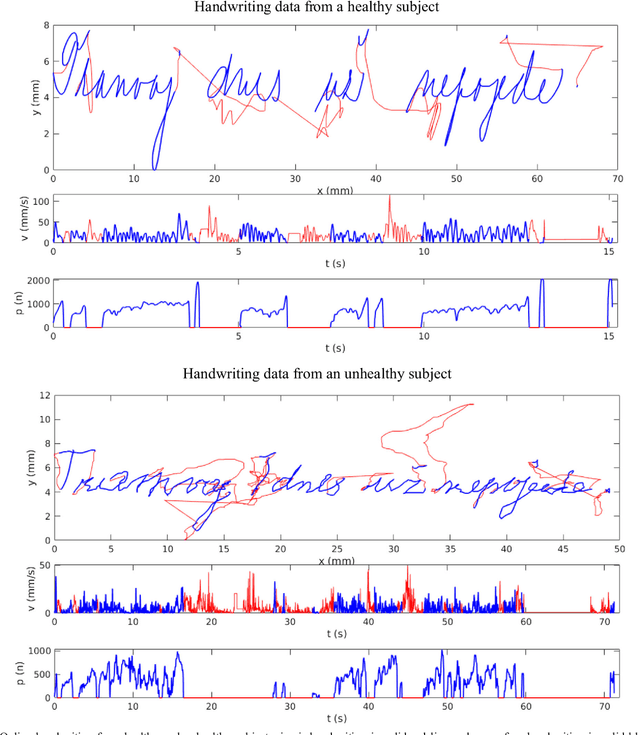
Background- This paper summarizes the state-of-the-art and applications based on online handwritting signals with special emphasis on e-security and e-health fields. Methods- In particular, we focus on the main achievements and challenges that should be addressed by the scientific community, providing a guide document for future research. Conclusions- Among all the points discussed in this article, we remark the importance of considering security, health, and metadata from a joint perspective. This is especially critical due to the double use possibilities of these behavioral signals.
* 24 pages
A new face database simultaneously acquired in visible, near infrared and thermal spectrum
Feb 24, 2022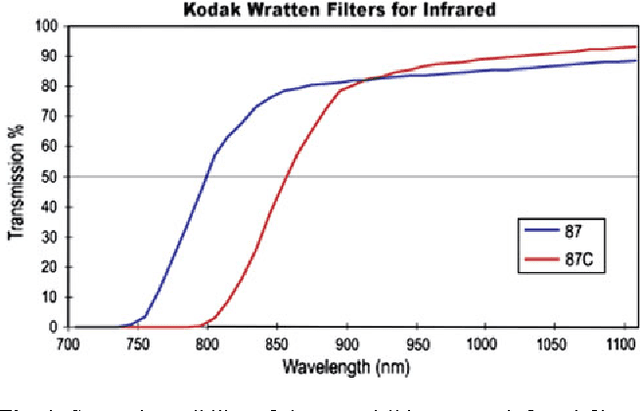

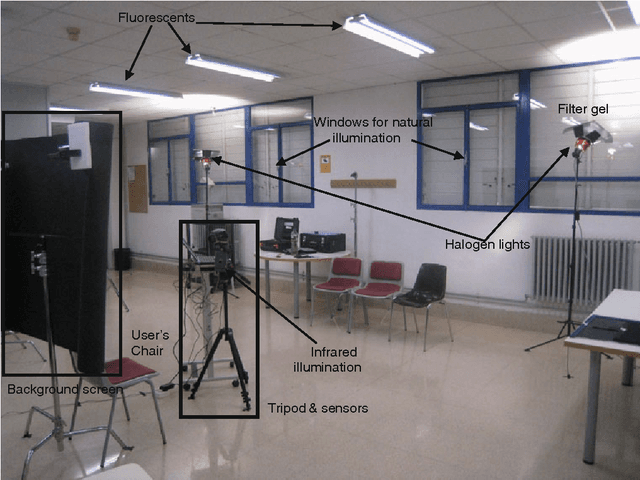

In this paper we present a new database acquired with three different sensors (visible, near infrared and thermal) under different illumination conditions. This database consists of 41 people acquired in four different acquisition sessions, five images per session and three different illumination conditions. The total amount of pictures is 7.380 pictures. Experimental results are obtained through single sensor experiments as well as the combination of two and three sensors under different illumination conditions (natural, infrared and artificial illumination). We have found that the three spectral bands studied contribute in a nearly equal proportion to a combined system. Experimental results show a significant improvement combining the three spectrums, even when using a simple classifier and feature extractor. In six of the nine scenarios studied we obtained identification rates higher or equal to 98%, when using a trained combination rule, and two cases of nine when using a fixed rule.
* 19 pages
On the relevance of bandwidth extension for speaker identification
Feb 24, 2022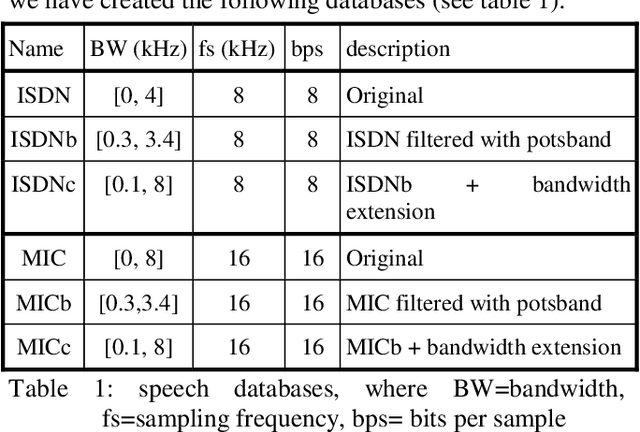
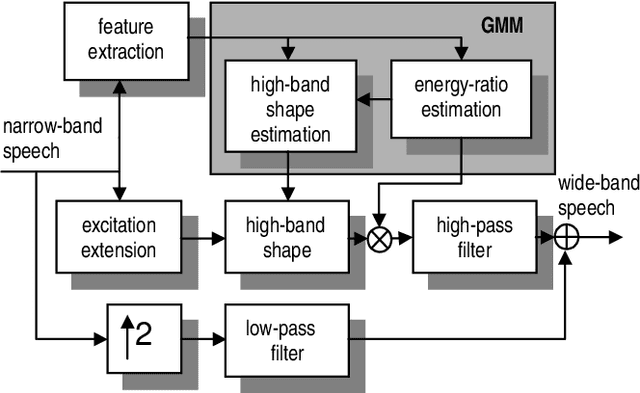
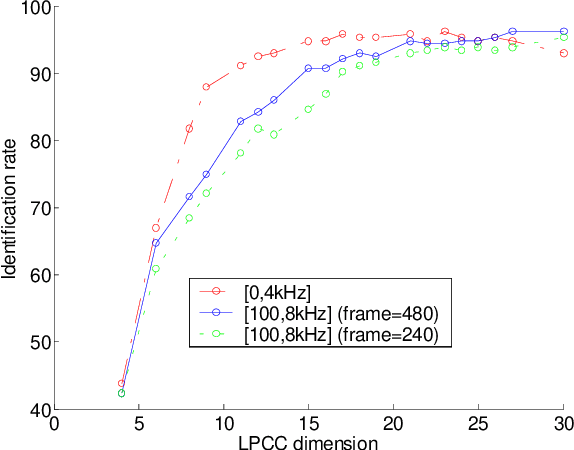
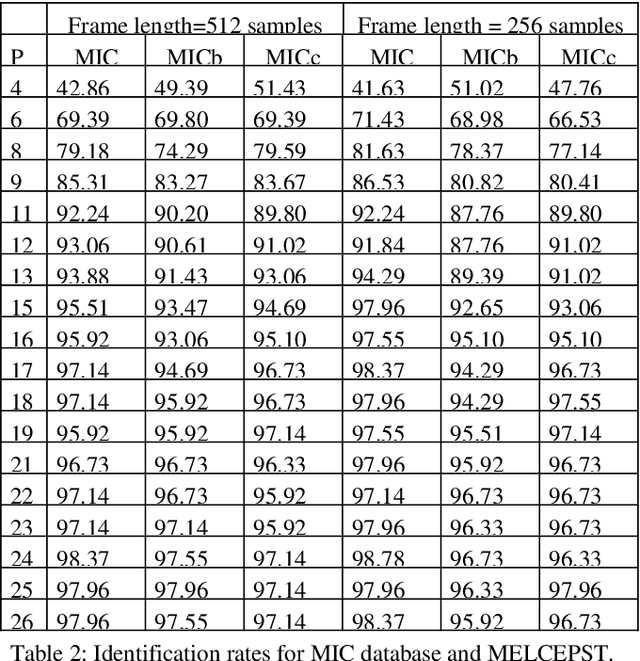
In this paper we discuss the relevance of bandwidth extension for speaker identification tasks. Mainly we want to study if it is possible to recognize voices that have been bandwith extended. For this purpose, we created two different databases (microphonic and ISDN) of speech signals that were bandwidth extended from telephone bandwidth ([300, 3400] Hz) to full bandwidth ([100, 8000] Hz). We have evaluated different parameterizations, and we have found that the MELCEPST parameterization can take advantage of the bandwidth extension algorithms in several situations.
* 4 pages
N-dimensional nonlinear prediction with MLP
Feb 24, 2022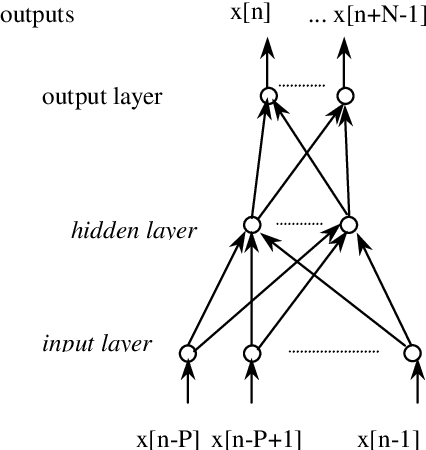
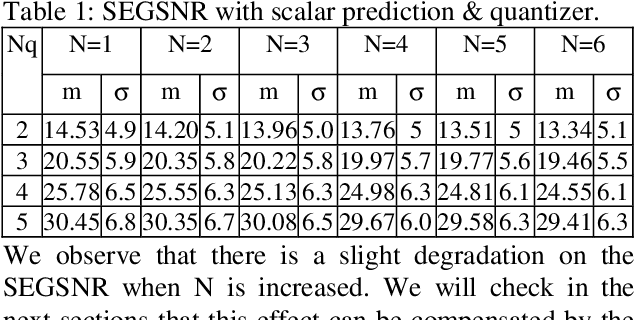
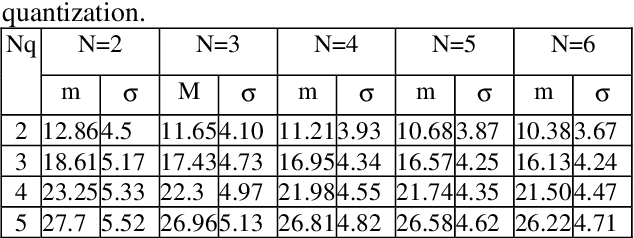
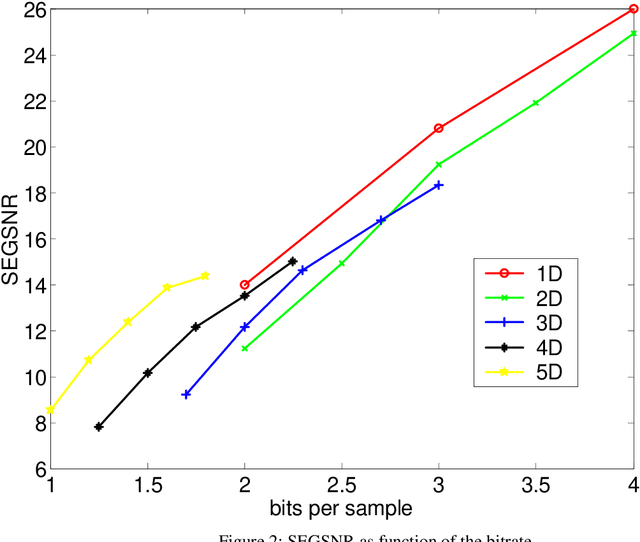
In this paper we propose a Non-Linear Predictive Vector quantizer (PVQ) for speech coding, based on Multi-Layer Perceptrons. With this scheme we have improved the results of our previous ADPCM coder with nonlinear prediction, and we have reduced the bit rate up to 1 bit per sample.
* 4 pages
A comparative study of several parameterizations for speaker recognition
Feb 24, 2022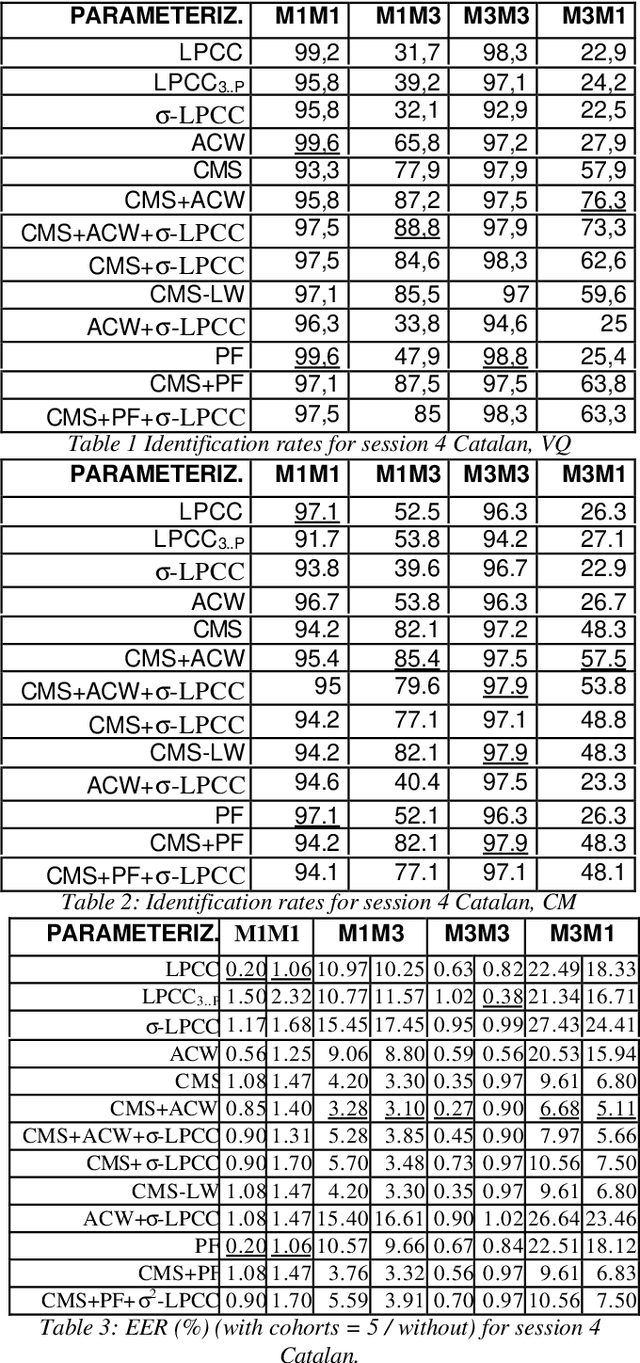
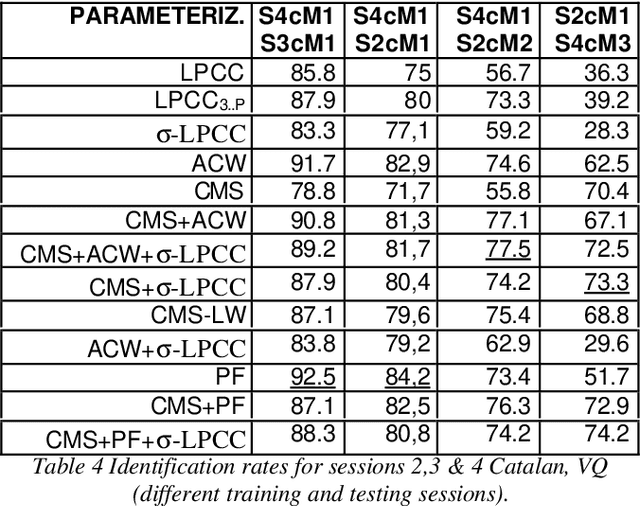
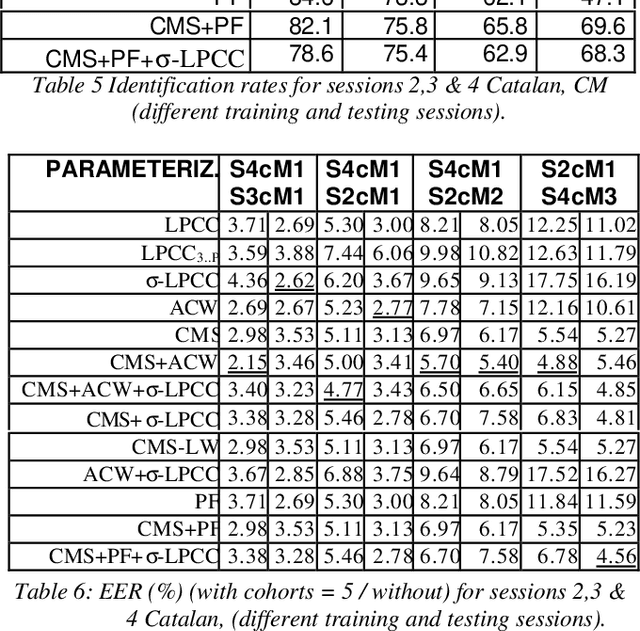
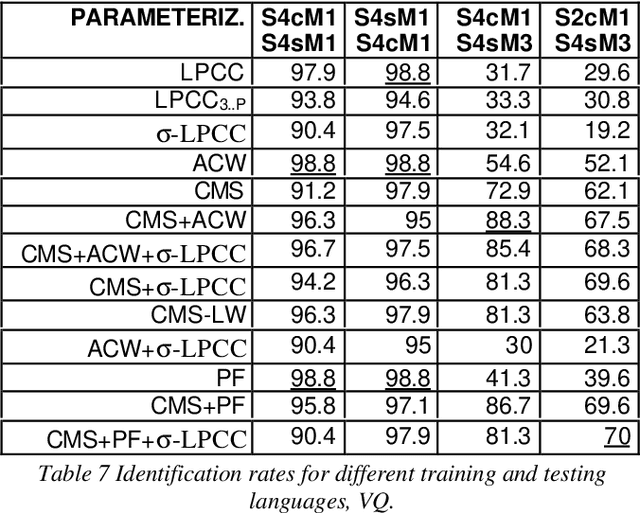
This paper presents an exhaustive study about the robustness of several parameterizations, in speaker verification and identification tasks. We have studied several mismatch conditions: different recording sessions, microphones, and different languages (it has been obtained from a bilingual set of speakers). This study reveals that the combination of several parameterizations can improve the robustness in all the scenarios for both tasks, identification and verification. In addition, two different methods have been evaluated: vector quantization, and covariance matrices with an arithmetic-harmonic sphericity measure.
* 4 pages
ADPCM with nonlinear prediction
Feb 24, 2022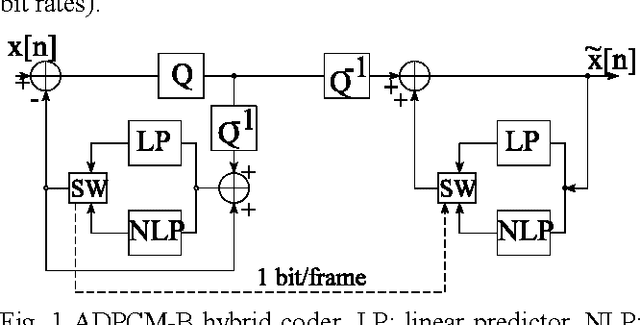
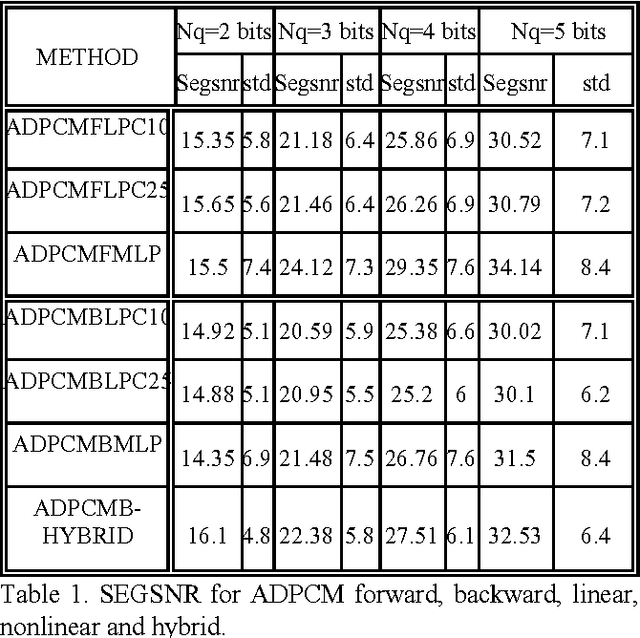
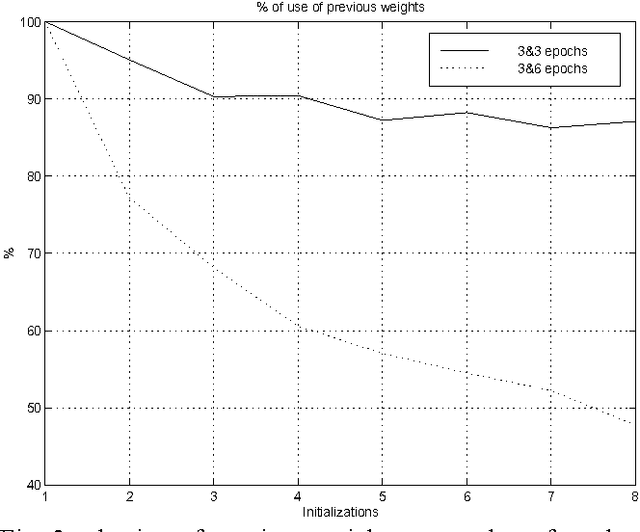
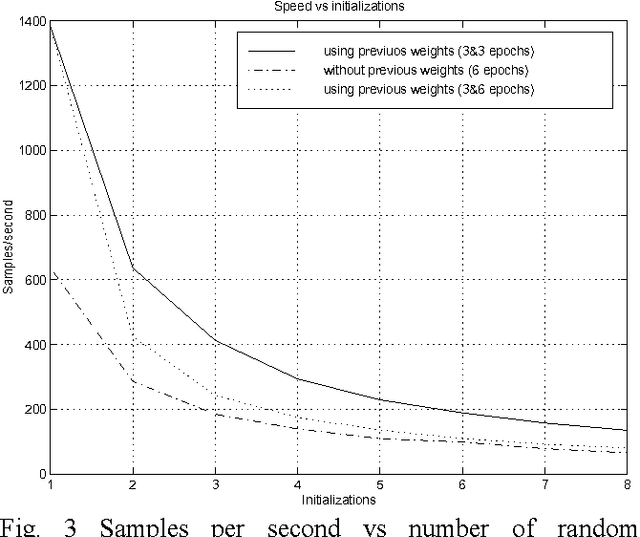
Many speech coders are based on linear prediction coding (LPC), nevertheless with LPC is not possible to model the nonlinearities present in the speech signal. Because of this there is a growing interest for nonlinear techniques. In this paper we discuss ADPCM schemes with a nonlinear predictor based on neural nets, which yields an increase of 1-2.5dB in the SEGSNR over classical methods. This paper will discuss the block-adaptive and sample-adaptive predictions.
* 4 pages