 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Batch Active Learning via Bilevel Optimization
Oct 19, 2020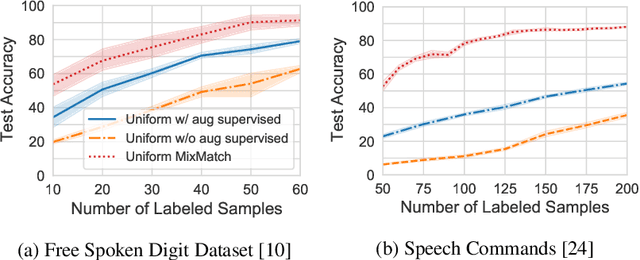
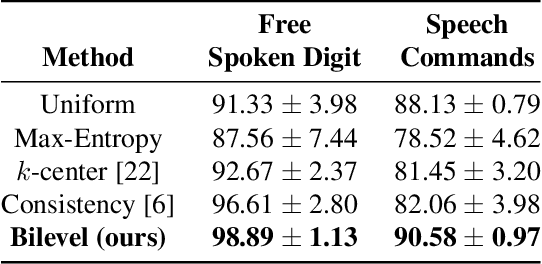
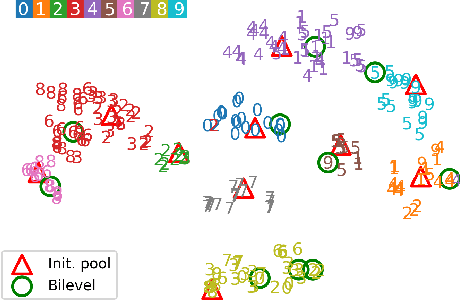
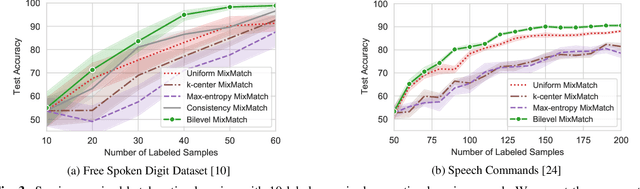
Active learning is an effective technique for reducing the labeling cost by improving data efficiency. In this work, we propose a novel batch acquisition strategy for active learning in the setting where the model training is performed in a semi-supervised manner. We formulate our approach as a data summarization problem via bilevel optimization, where the queried batch consists of the points that best summarize the unlabeled data pool. We show that our method is highly effective in keyword detection tasks in the regime when only few labeled samples are available.
SEANet: A Multi-modal Speech Enhancement Network
Oct 01, 2020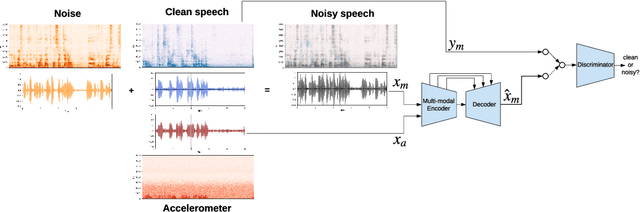
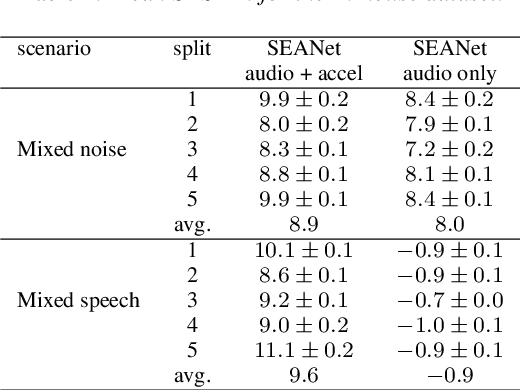
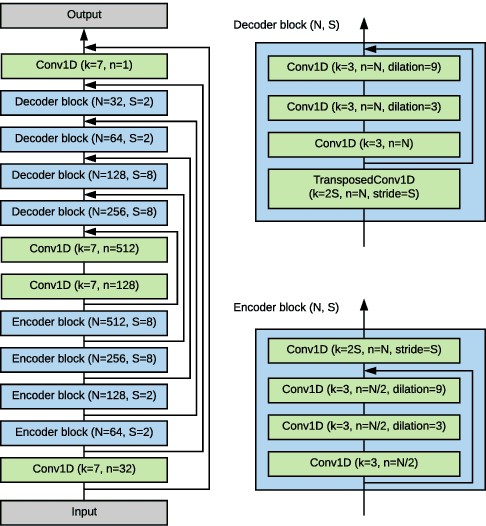

We explore the possibility of leveraging accelerometer data to perform speech enhancement in very noisy conditions. Although it is possible to only partially reconstruct user's speech from the accelerometer, the latter provides a strong conditioning signal that is not influenced from noise sources in the environment. Based on this observation, we feed a multi-modal input to SEANet (Sound EnhAncement Network), a wave-to-wave fully convolutional model, which adopts a combination of feature losses and adversarial losses to reconstruct an enhanced version of user's speech. We trained our model with data collected by sensors mounted on an earbud and synthetically corrupted by adding different kinds of noise sources to the audio signal. Our experimental results demonstrate that it is possible to achieve very high quality results, even in the case of interfering speech at the same level of loudness. A sample of the output produced by our model is available at https://google-research.github.io/seanet/multimodal/speech.
Learning to Denoise Historical Music
Aug 05, 2020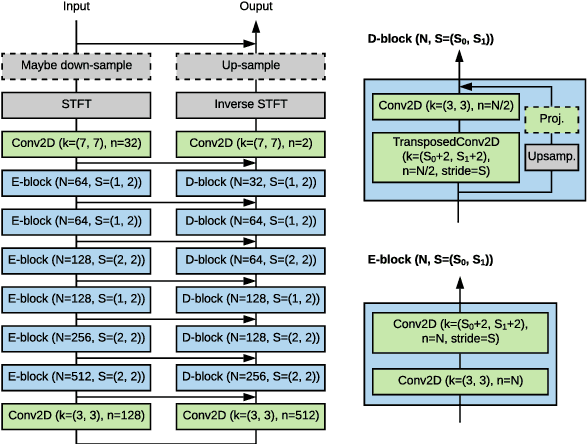
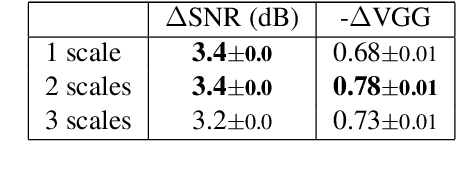
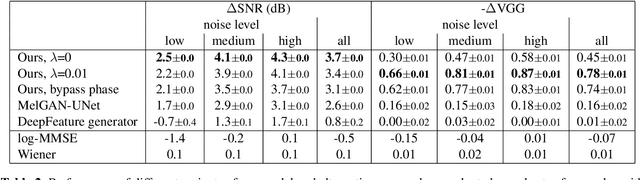
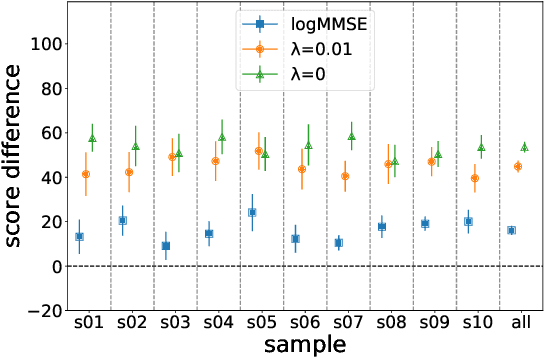
We propose an audio-to-audio neural network model that learns to denoise old music recordings. Our model internally converts its input into a time-frequency representation by means of a short-time Fourier transform (STFT), and processes the resulting complex spectrogram using a convolutional neural network. The network is trained with both reconstruction and adversarial objectives on a synthetic noisy music dataset, which is created by mixing clean music with real noise samples extracted from quiet segments of old recordings. We evaluate our method quantitatively on held-out test examples of the synthetic dataset, and qualitatively by human rating on samples of actual historical recordings. Our results show that the proposed method is effective in removing noise, while preserving the quality and details of the original music.
Towards Learning a Universal Non-Semantic Representation of Speech
Mar 02, 2020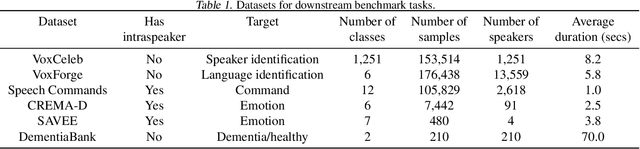
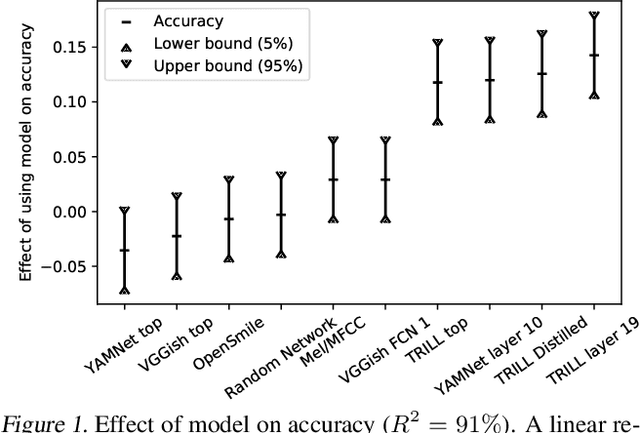
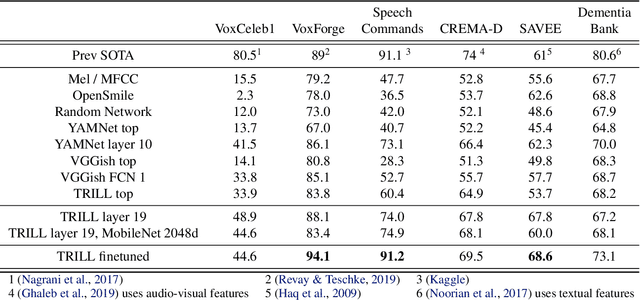
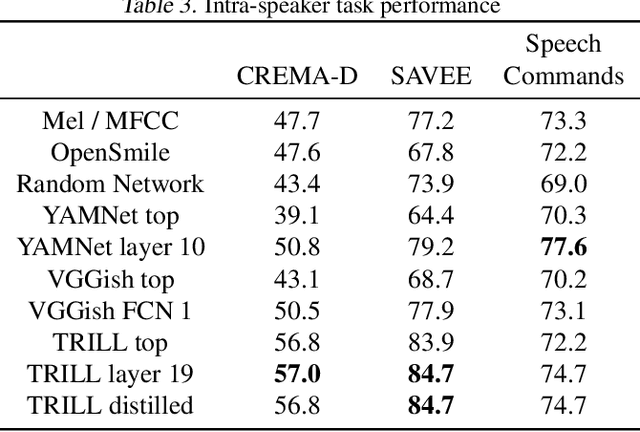
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.
Learning audio representations via phase prediction
Oct 25, 2019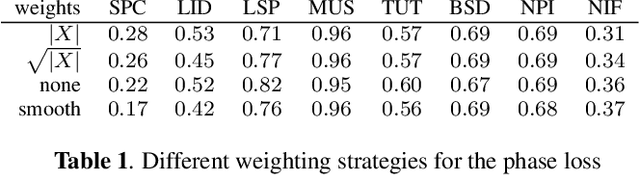
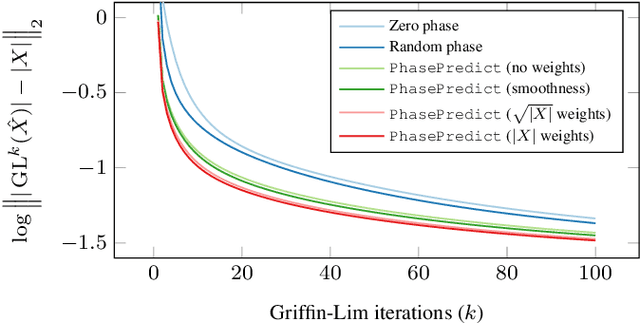
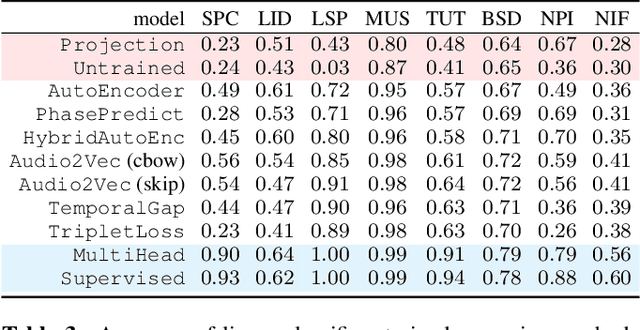
We learn audio representations by solving a novel self-supervised learning task, which consists of predicting the phase of the short-time Fourier transform from its magnitude. A convolutional encoder is used to map the magnitude spectrum of the input waveform to a lower dimensional embedding. A convolutional decoder is then used to predict the instantaneous frequency (i.e., the temporal rate of change of the phase) from such embedding. To evaluate the quality of the learned representations, we evaluate how they transfer to a wide variety of downstream audio tasks. Our experiments reveal that the phase prediction task leads to representations that generalize across different tasks, partially bridging the gap with fully-supervised models. In addition, we show that the predicted phase can be used as initialization of the Griffin-Lim algorithm, thus reducing the number of iterations needed to reconstruct the waveform in the time domain.
SPICE: Self-supervised Pitch Estimation
Oct 25, 2019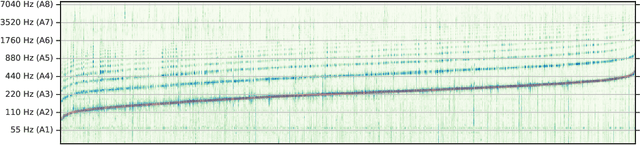
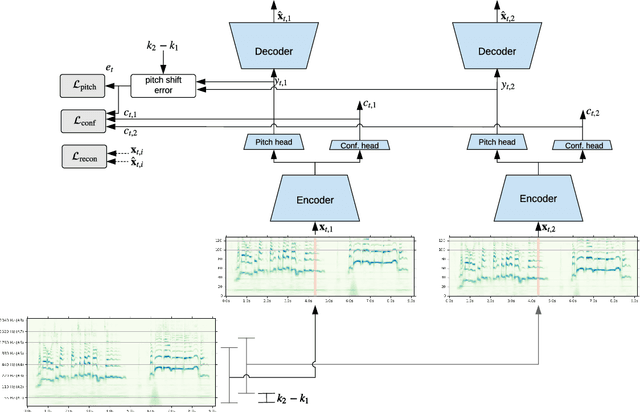
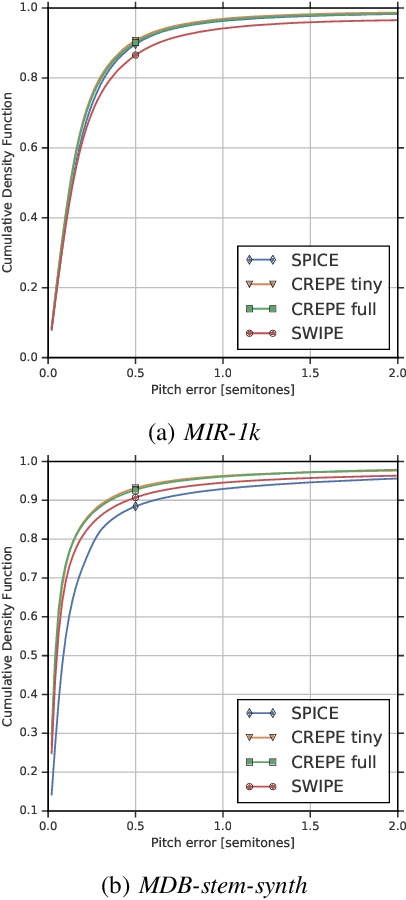
We propose a model to estimate the fundamental frequency in monophonic audio, often referred to as pitch estimation. We acknowledge the fact that obtaining ground truth annotations at the required temporal and frequency resolution is a particularly daunting task. Therefore, we propose to adopt a self-supervised learning technique, which is able to estimate (relative) pitch without any form of supervision. The key observation is that pitch shift maps to a simple translation when the audio signal is analysed through the lens of the constant-Q transform (CQT). We design a self-supervised task by feeding two shifted slices of the CQT to the same convolutional encoder, and require that the difference in the outputs is proportional to the corresponding difference in pitch. In addition, we introduce a small model head on top of the encoder, which is able to determine the confidence of the pitch estimate, so as to distinguish between voiced and unvoiced audio. Our results show that the proposed method is able to estimate pitch at a level of accuracy comparable to fully supervised models, both on clean and noisy audio samples, yet it does not require access to large labeled datasets
From Here to There: Video Inbetweening Using Direct 3D Convolutions
Jun 04, 2019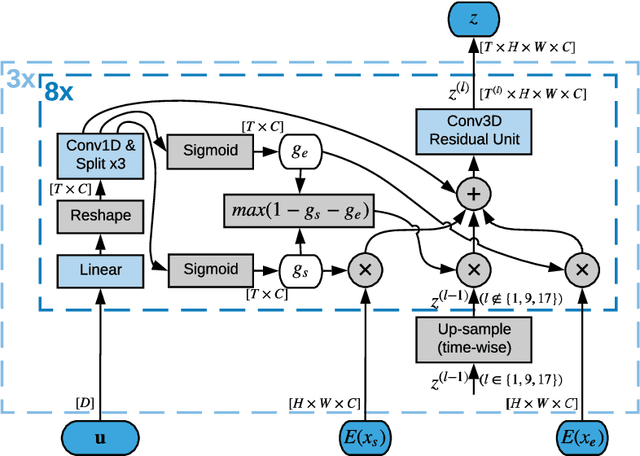

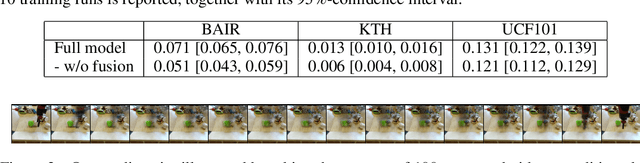
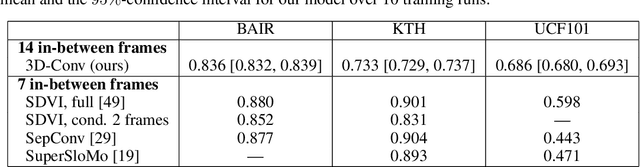
We consider the problem of generating plausible and diverse video sequences, when we are only given a start and an end frame. This task is also known as inbetweening, and it belongs to the broader area of stochastic video generation, which is generally approached by means of recurrent neural networks (RNN). In this paper, we propose instead a fully convolutional model to generate video sequences directly in the pixel domain. We first obtain a latent video representation using a stochastic fusion mechanism that learns how to incorporate information from the start and end frames. Our model learns to produce such latent representation by progressively increasing the temporal resolution, and then decode in the spatiotemporal domain using 3D convolutions. The model is trained end-to-end by minimizing an adversarial loss. Experiments on several widely-used benchmark datasets show that it is able to generate meaningful and diverse in-between video sequences, according to both quantitative and qualitative evaluations.
Self-supervised audio representation learning for mobile devices
May 24, 2019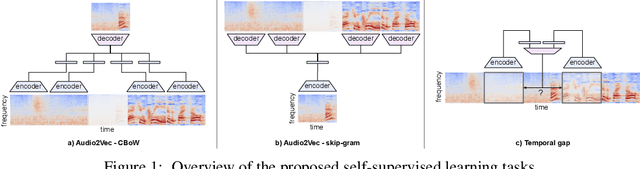
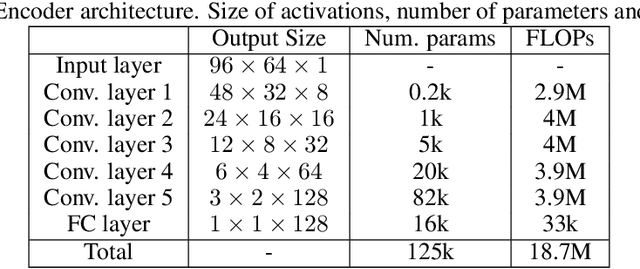
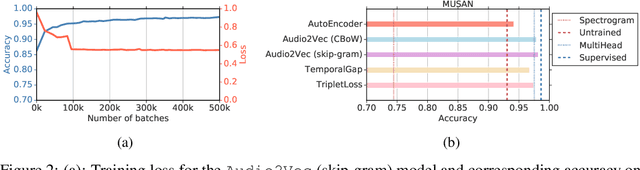
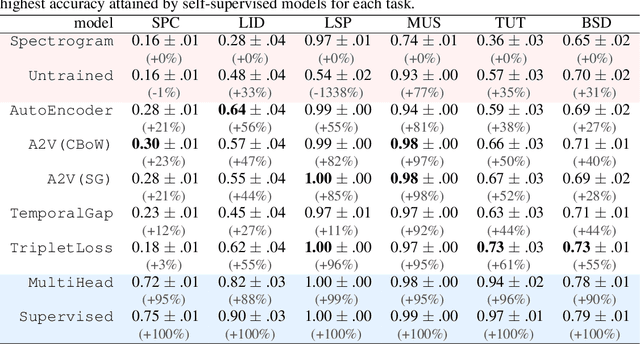
We explore self-supervised models that can be potentially deployed on mobile devices to learn general purpose audio representations. Specifically, we propose methods that exploit the temporal context in the spectrogram domain. One method estimates the temporal gap between two short audio segments extracted at random from the same audio clip. The other methods are inspired by Word2Vec, a popular technique used to learn word embeddings, and aim at reconstructing a temporal spectrogram slice from past and future slices or, alternatively, at reconstructing the context of surrounding slices from the current slice. We focus our evaluation on small encoder architectures, which can be potentially run on mobile devices during both inference (re-using a common learned representation across multiple downstream tasks) and training (capturing the true data distribution without compromising users' privacy when combined with federated learning). We evaluate the quality of the embeddings produced by the self-supervised learning models, and show that they can be re-used for a variety of downstream tasks, and for some tasks even approach the performance of fully supervised models of similar size.
Deep convolutional neural networks for pedestrian detection
Mar 07, 2016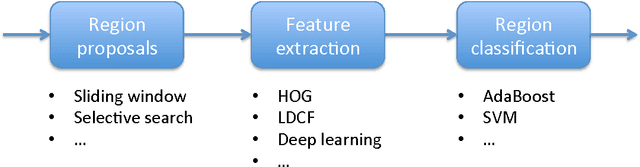
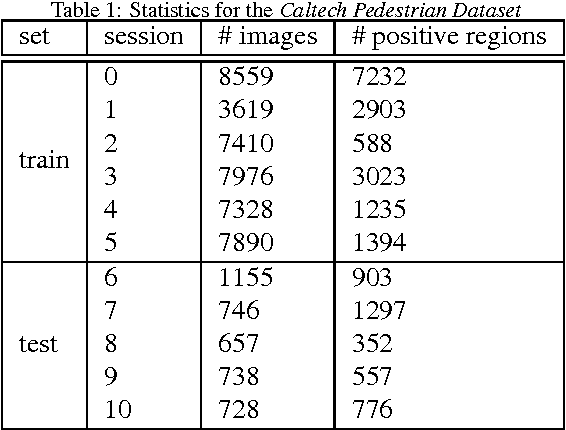


Pedestrian detection is a popular research topic due to its paramount importance for a number of applications, especially in the fields of automotive, surveillance and robotics. Despite the significant improvements, pedestrian detection is still an open challenge that calls for more and more accurate algorithms. In the last few years, deep learning and in particular convolutional neural networks emerged as the state of the art in terms of accuracy for a number of computer vision tasks such as image classification, object detection and segmentation, often outperforming the previous gold standards by a large margin. In this paper, we propose a pedestrian detection system based on deep learning, adapting a general-purpose convolutional network to the task at hand. By thoroughly analyzing and optimizing each step of the detection pipeline we propose an architecture that outperforms traditional methods, achieving a task accuracy close to that of state-of-the-art approaches, while requiring a low computational time. Finally, we tested the system on an NVIDIA Jetson TK1, a 192-core platform that is envisioned to be a forerunner computational brain of future self-driving cars.
Estimating snow cover from publicly available images
Aug 05, 2015
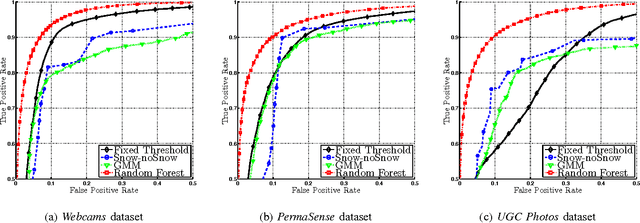
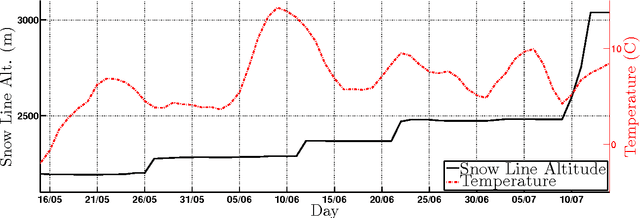
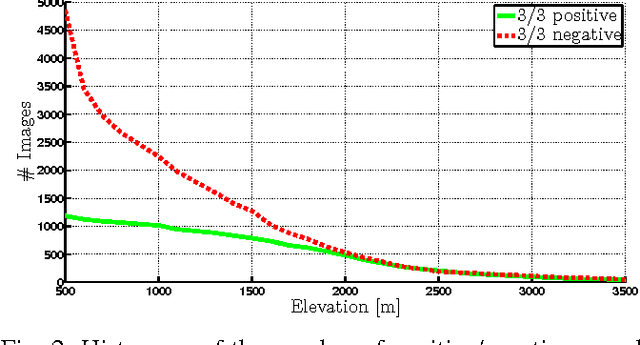
In this paper we study the problem of estimating snow cover in mountainous regions, that is, the spatial extent of the earth surface covered by snow. We argue that publicly available visual content, in the form of user generated photographs and image feeds from outdoor webcams, can both be leveraged as additional measurement sources, complementing existing ground, satellite and airborne sensor data. To this end, we describe two content acquisition and processing pipelines that are tailored to such sources, addressing the specific challenges posed by each of them, e.g., identifying the mountain peaks, filtering out images taken in bad weather conditions, handling varying illumination conditions. The final outcome is summarized in a snow cover index, which indicates for a specific mountain and day of the year, the fraction of visible area covered by snow, possibly at different elevations. We created a manually labelled dataset to assess the accuracy of the image snow covered area estimation, achieving 90.0% precision at 91.1% recall. In addition, we show that seasonal trends related to air temperature are captured by the snow cover index.