 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
Investigating Language Impact in Bilingual Approaches for Computational Language Documentation
Mar 30, 2020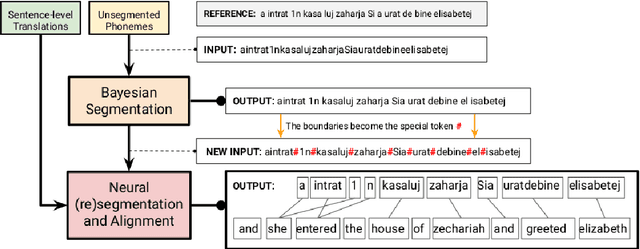
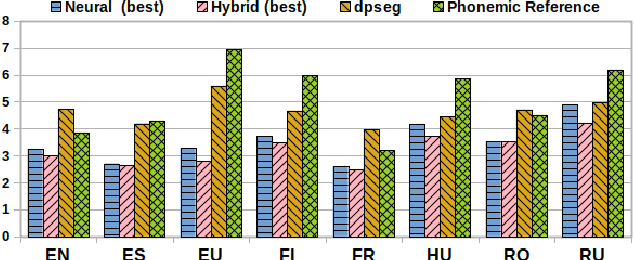
For endangered languages, data collection campaigns have to accommodate the challenge that many of them are from oral tradition, and producing transcriptions is costly. Therefore, it is fundamental to translate them into a widely spoken language to ensure interpretability of the recordings. In this paper we investigate how the choice of translation language affects the posterior documentation work and potential automatic approaches which will work on top of the produced bilingual corpus. For answering this question, we use the MaSS multilingual speech corpus (Boito et al., 2020) for creating 56 bilingual pairs that we apply to the task of low-resource unsupervised word segmentation and alignment. Our results highlight that the choice of language for translation influences the word segmentation performance, and that different lexicons are learned by using different aligned translations. Lastly, this paper proposes a hybrid approach for bilingual word segmentation, combining boundary clues extracted from a non-parametric Bayesian model (Goldwater et al., 2009a) with the attentional word segmentation neural model from Godard et al. (2018). Our results suggest that incorporating these clues into the neural models' input representation increases their translation and alignment quality, specially for challenging language pairs.
ON-TRAC Consortium End-to-End Speech Translation Systems for the IWSLT 2019 Shared Task
Oct 30, 2019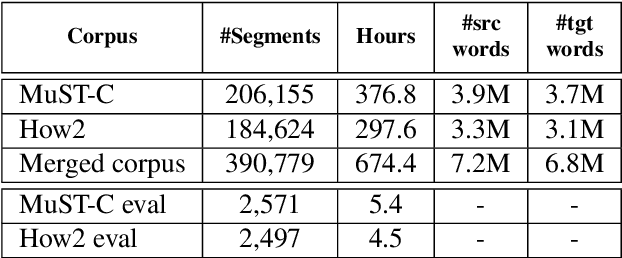
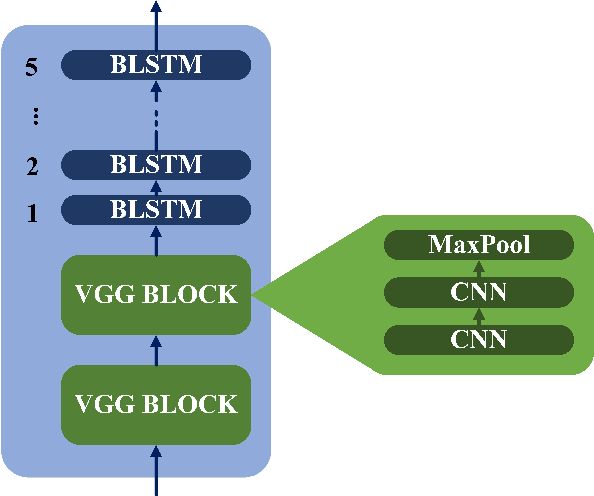
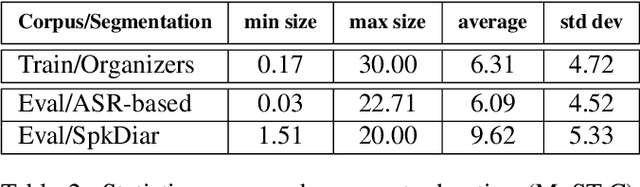
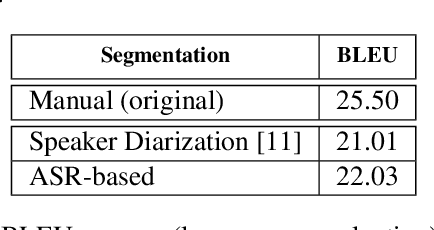
This paper describes the ON-TRAC Consortium translation systems developed for the end-to-end model task of IWSLT Evaluation 2019 for the English-to-Portuguese language pair. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). A single end-to-end model built as a neural encoder-decoder architecture with attention mechanism was used for two primary submissions corresponding to the two EN-PT evaluations sets: (1) TED (MuST-C) and (2) How2. In this paper, we notably investigate impact of pooling heterogeneous corpora for training, impact of target tokenization (characters or BPEs), impact of speech input segmentation and we also compare our best end-to-end model (BLEU of 26.91 on MuST-C and 43.82 on How2 validation sets) to a pipeline (ASR+MT) approach.
How Does Language Influence Documentation Workflow? Unsupervised Word Discovery Using Translations in Multiple Languages
Oct 11, 2019

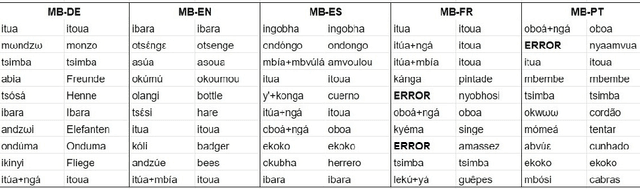
For language documentation initiatives, transcription is an expensive resource: one minute of audio is estimated to take one hour and a half on average of a linguist's work (Austin and Sallabank, 2013). Recently, collecting aligned translations in well-resourced languages became a popular solution for ensuring posterior interpretability of the recordings (Adda et al. 2016). In this paper we investigate language-related impact in automatic approaches for computational language documentation. We translate the bilingual Mboshi-French parallel corpus (Godard et al. 2017) into four other languages, and we perform bilingual-rooted unsupervised word discovery. Our results hint towards an impact of the well-resourced language in the quality of the output. However, by combining the information learned by different bilingual models, we are only able to marginally increase the quality of the segmentation.
MaSS: A Large and Clean Multilingual Corpus of Sentence-aligned Spoken Utterances Extracted from the Bible
Aug 01, 2019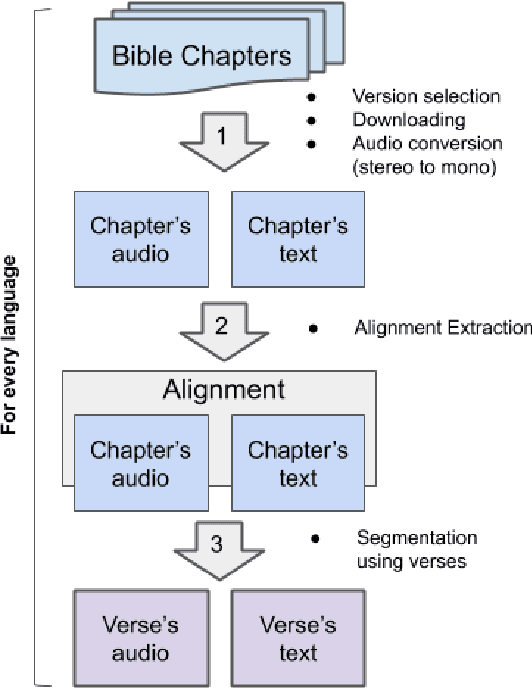

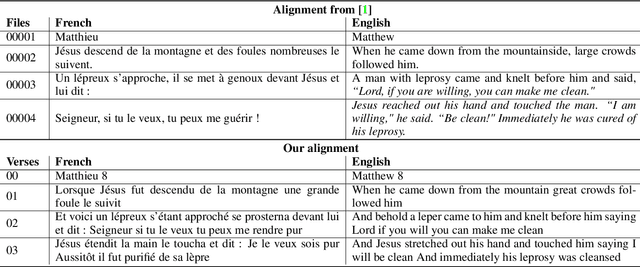
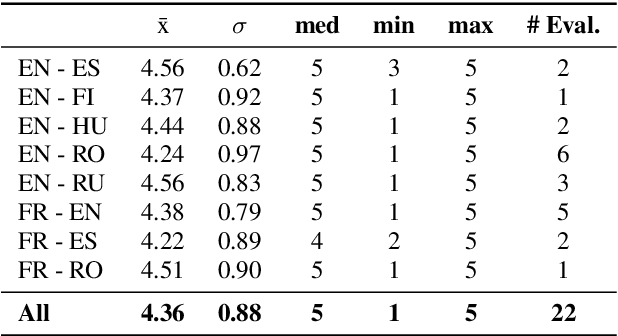
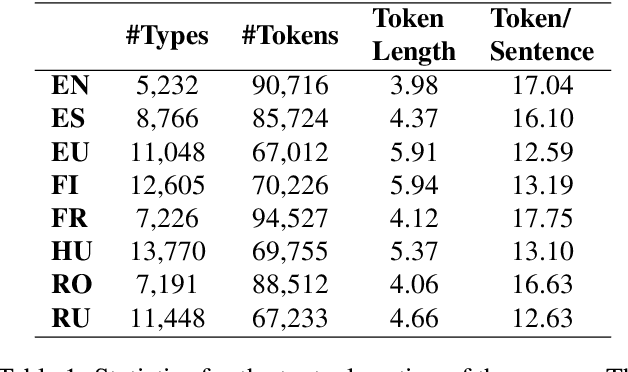
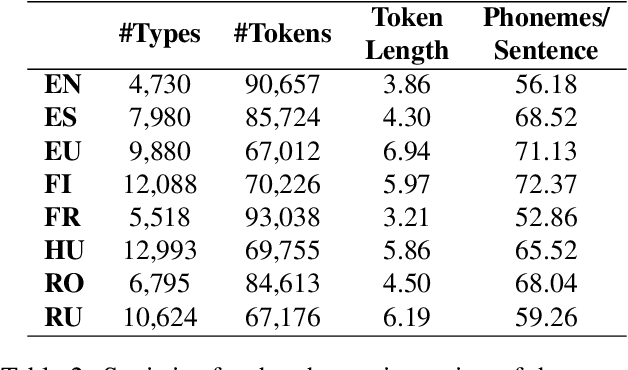
The CMU Wilderness Multilingual Speech Dataset is a newly published multilingual speech dataset based on recorded readings of the New Testament. It provides data to build Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models for potentially 700 languages. However, the fact that the source content (the Bible), is the same for all the languages is not exploited to date. Therefore, this article proposes to add multilingual links between speech segments in different languages, and shares a large and clean dataset of 8,130 para-lel spoken utterances across 8 languages (56 language pairs).We name this corpus MaSS (Multilingual corpus of Sentence-aligned Spoken utterances). The covered languages (Basque, English, Finnish, French, Hungarian, Romanian, Russian and Spanish) allow researches on speech-to-speech alignment as well as on translation for syntactically divergent language pairs. The quality of the final corpus is attested by human evaluation performed on a corpus subset (100 utterances, 8 language pairs). Lastly, we showcase the usefulness of the final product on a bilingual speech retrieval task.
Empirical Evaluation of Sequence-to-Sequence Models for Word Discovery in Low-resource Settings
Jun 29, 2019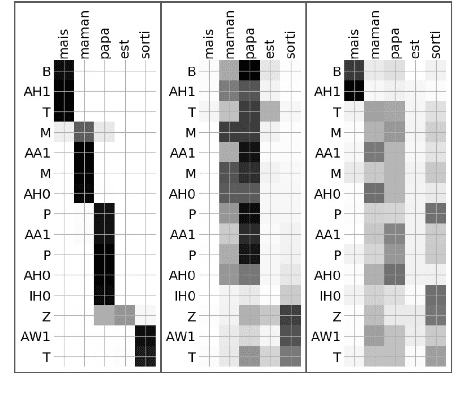

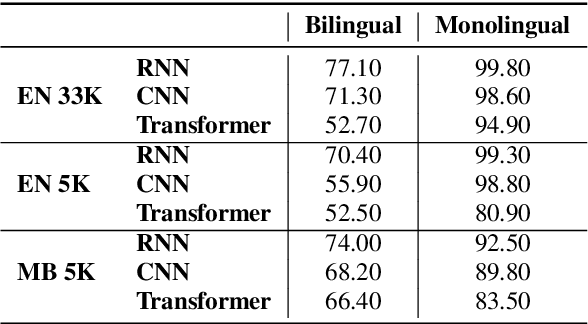
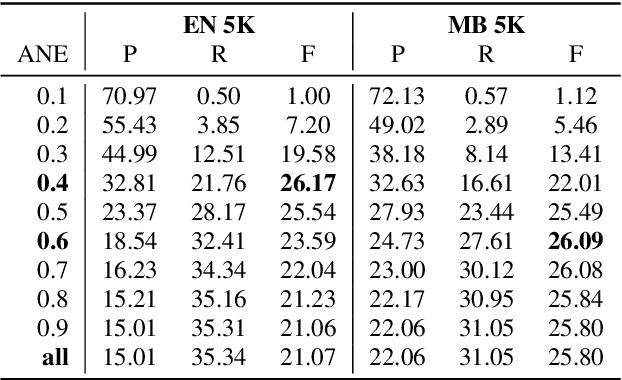
Since Bahdanau et al. [1] first introduced attention for neural machine translation, most sequence-to-sequence models made use of attention mechanisms [2, 3, 4]. While they produce soft-alignment matrices that could be interpreted as alignment between target and source languages, we lack metrics to quantify their quality, being unclear which approach produces the best alignments. This paper presents an empirical evaluation of 3 main sequence-to-sequence models (CNN, RNN and Transformer-based) for word discovery from unsegmented phoneme sequences. This task consists in aligning word sequences in a source language with phoneme sequences in a target language, inferring from it word segmentation on the target side [5]. Evaluating word segmentation quality can be seen as an extrinsic evaluation of the soft-alignment matrices produced during training. Our experiments in a low-resource scenario on Mboshi and English languages (both aligned to French) show that RNNs surprisingly outperform CNNs and Transformer for this task. Our results are confirmed by an intrinsic evaluation of alignment quality through the use of Average Normalized Entropy (ANE). Lastly, we improve our best word discovery model by using an alignment entropy confidence measure that accumulates ANE over all the occurrences of a given alignment pair in the collection.
A small Griko-Italian speech translation corpus
Jul 27, 2018


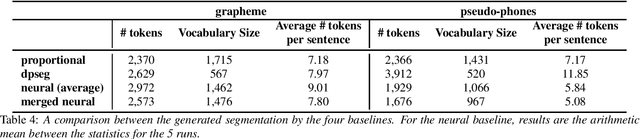
This paper presents an extension to a very low-resource parallel corpus collected in an endangered language, Griko, making it useful for computational research. The corpus consists of 330 utterances (about 20 minutes of speech) which have been transcribed and translated in Italian, with annotations for word-level speech-to-transcription and speech-to-translation alignments. The corpus also includes morphosyntactic tags and word-level glosses. Applying an automatic unit discovery method, pseudo-phones were also generated. We detail how the corpus was collected, cleaned and processed, and we illustrate its use on zero-resource tasks by presenting some baseline results for the task of speech-to-translation alignment and unsupervised word discovery. The dataset is available online, aiming to encourage replicability and diversity in computational language documentation experiments.
Unwritten Languages Demand Attention Too! Word Discovery with Encoder-Decoder Models
Sep 19, 2017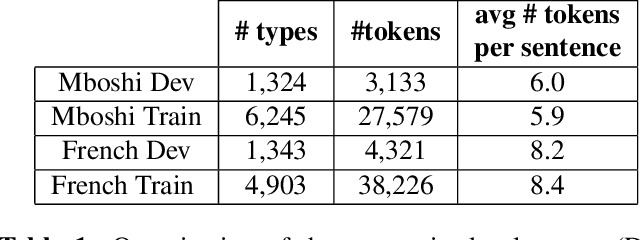
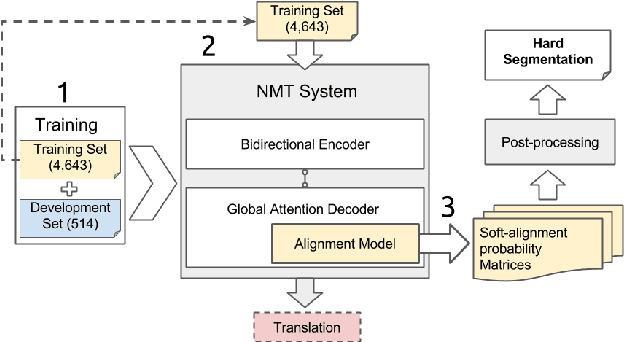
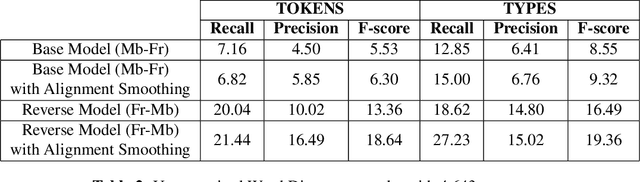
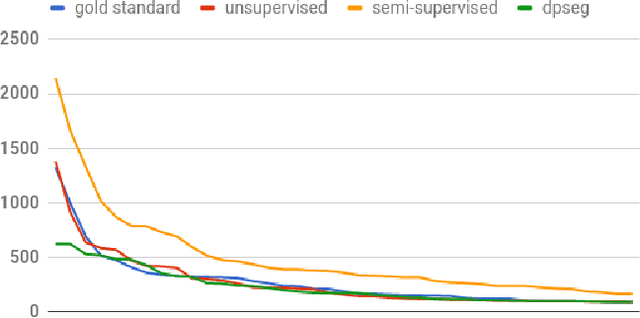
Word discovery is the task of extracting words from unsegmented text. In this paper we examine to what extent neural networks can be applied to this task in a realistic unwritten language scenario, where only small corpora and limited annotations are available. We investigate two scenarios: one with no supervision and another with limited supervision with access to the most frequent words. Obtained results show that it is possible to retrieve at least 27% of the gold standard vocabulary by training an encoder-decoder neural machine translation system with only 5,157 sentences. This result is close to those obtained with a task-specific Bayesian nonparametric model. Moreover, our approach has the advantage of generating translation alignments, which could be used to create a bilingual lexicon. As a future perspective, this approach is also well suited to work directly from speech.