 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Graph Neural Processes: A Functional Autoencoder Approach
Dec 13, 2018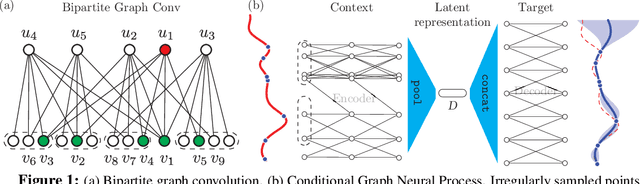
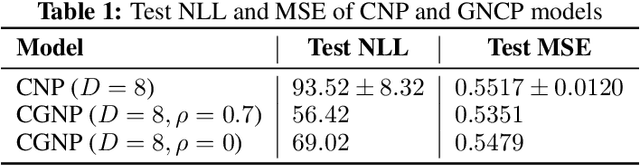
We introduce a novel encoder-decoder architecture to embed functional processes into latent vector spaces. This embedding can then be decoded to sample the encoded functions over any arbitrary domain. This autoencoder generalizes the recently introduced Conditional Neural Process (CNP) model of random processes. Our architecture employs the latest advances in graph neural networks to process irregularly sampled functions. Thus, we refer to our model as Conditional Graph Neural Process (CGNP). Graph neural networks can effectively exploit `local' structures of the metric spaces over which the functions/processes are defined. The contributions of this paper are twofold: (i) a novel graph-based encoder-decoder architecture for functional and process embeddings, and (ii) a demonstration of the importance of using the structure of metric spaces for this type of representations.
Flexpoint: An Adaptive Numerical Format for Efficient Training of Deep Neural Networks
Dec 02, 2017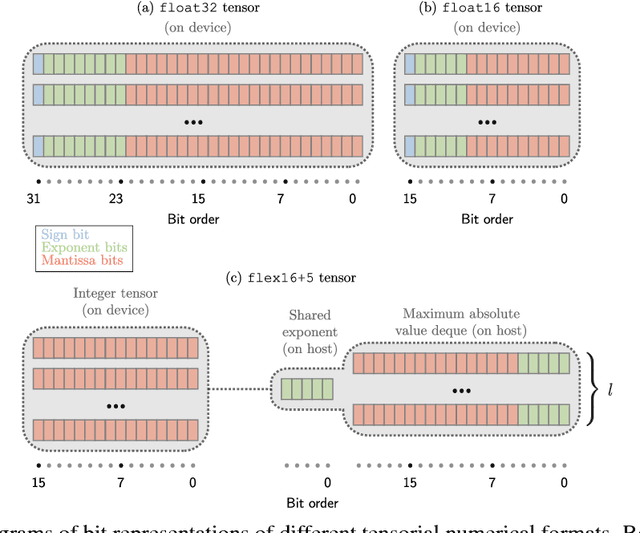
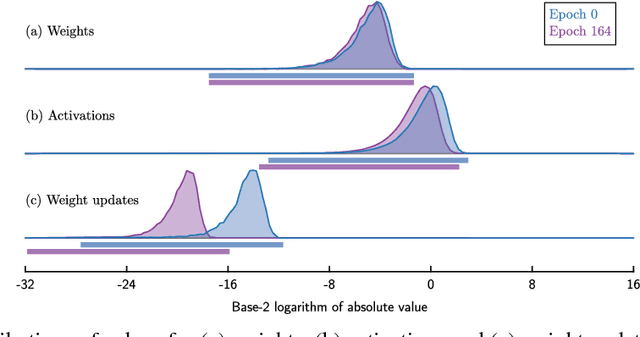
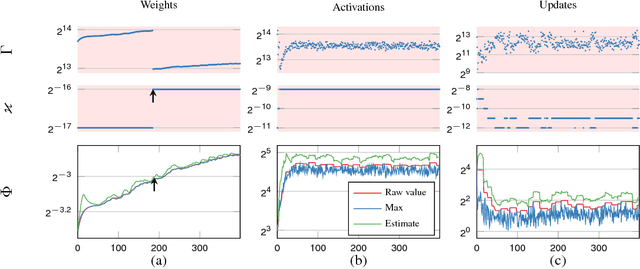
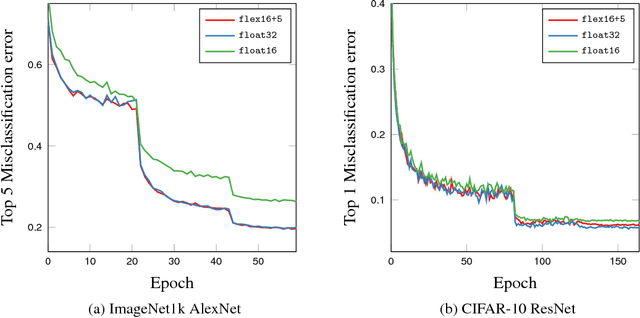
Deep neural networks are commonly developed and trained in 32-bit floating point format. Significant gains in performance and energy efficiency could be realized by training and inference in numerical formats optimized for deep learning. Despite advances in limited precision inference in recent years, training of neural networks in low bit-width remains a challenging problem. Here we present the Flexpoint data format, aiming at a complete replacement of 32-bit floating point format training and inference, designed to support modern deep network topologies without modifications. Flexpoint tensors have a shared exponent that is dynamically adjusted to minimize overflows and maximize available dynamic range. We validate Flexpoint by training AlexNet, a deep residual network and a generative adversarial network, using a simulator implemented with the neon deep learning framework. We demonstrate that 16-bit Flexpoint closely matches 32-bit floating point in training all three models, without any need for tuning of model hyperparameters. Our results suggest Flexpoint as a promising numerical format for future hardware for training and inference.
A Factor Graph Approach to Joint OFDM Channel Estimation and Decoding in Impulsive Noise Environments
Jun 07, 2013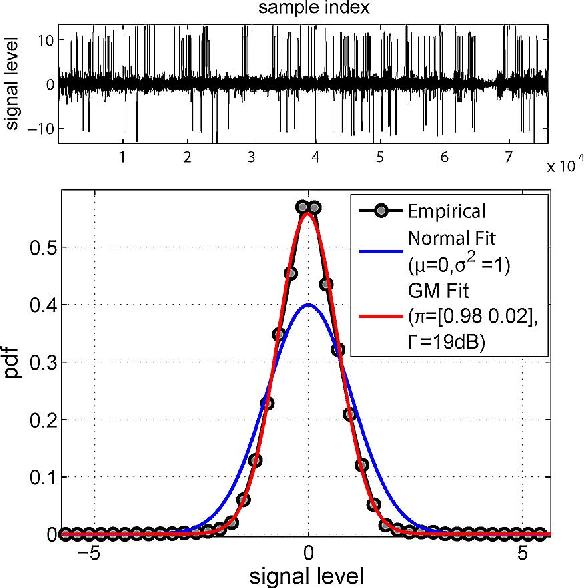
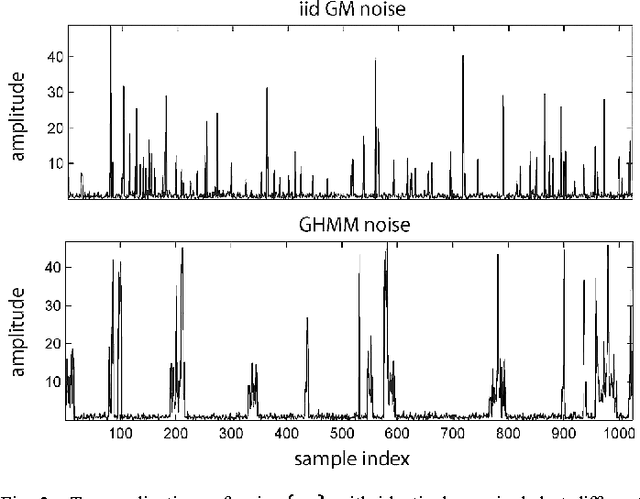
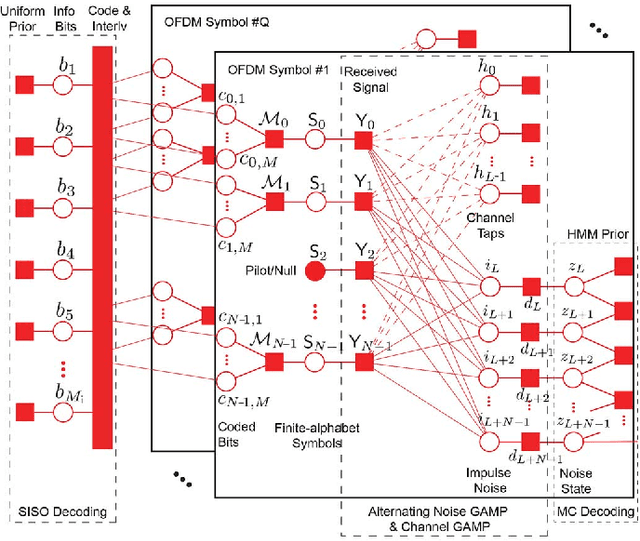
We propose a novel receiver for orthogonal frequency division multiplexing (OFDM) transmissions in impulsive noise environments. Impulsive noise arises in many modern wireless and wireline communication systems, such as Wi-Fi and powerline communications, due to uncoordinated interference that is much stronger than thermal noise. We first show that the bit-error-rate optimal receiver jointly estimates the propagation channel coefficients, the noise impulses, the finite-alphabet symbols, and the unknown bits. We then propose a near-optimal yet computationally tractable approach to this joint estimation problem using loopy belief propagation. In particular, we merge the recently proposed "generalized approximate message passing" (GAMP) algorithm with the forward-backward algorithm and soft-input soft-output decoding using a "turbo" approach. Numerical results indicate that the proposed receiver drastically outperforms existing receivers under impulsive noise and comes within 1 dB of the matched-filter bound. Meanwhile, with N tones, the proposed factor-graph-based receiver has only O(N log N) complexity, and it can be parallelized.
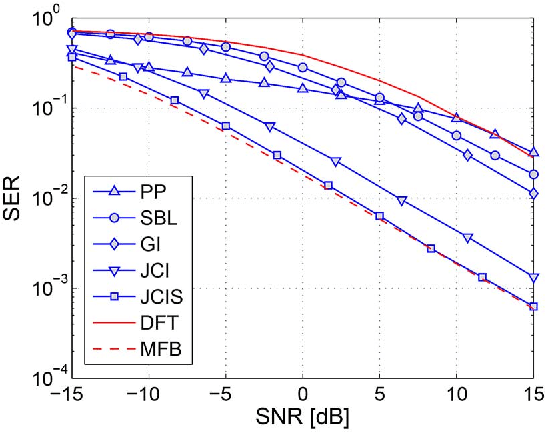
Impulsive Noise Mitigation in Powerline Communications Using Sparse Bayesian Learning
Mar 05, 2013
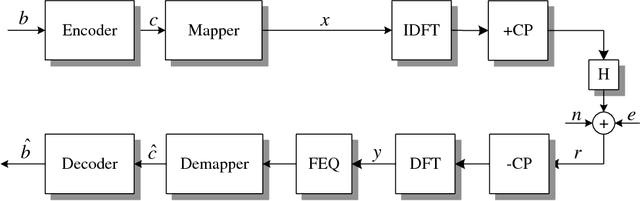
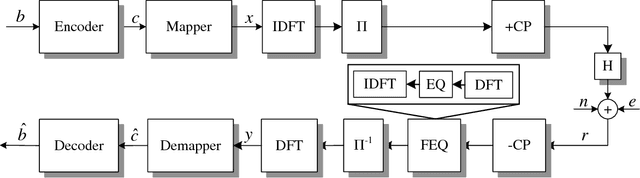
Additive asynchronous and cyclostationary impulsive noise limits communication performance in OFDM powerline communication (PLC) systems. Conventional OFDM receivers assume additive white Gaussian noise and hence experience degradation in communication performance in impulsive noise. Alternate designs assume a parametric statistical model of impulsive noise and use the model parameters in mitigating impulsive noise. These receivers require overhead in training and parameter estimation, and degrade due to model and parameter mismatch, especially in highly dynamic environments. In this paper, we model impulsive noise as a sparse vector in the time domain without any other assumptions, and apply sparse Bayesian learning methods for estimation and mitigation without training. We propose three iterative algorithms with different complexity vs. performance trade-offs: (1) we utilize the noise projection onto null and pilot tones to estimate and subtract the noise impulses; (2) we add the information in the data tones to perform joint noise estimation and OFDM detection; (3) we embed our algorithm into a decision feedback structure to further enhance the performance of coded systems. When compared to conventional OFDM PLC receivers, the proposed receivers achieve SNR gains of up to 9 dB in coded and 10 dB in uncoded systems in the presence of impulsive noise.
Active Bayesian Optimization: Minimizing Minimizer Entropy
Feb 09, 2012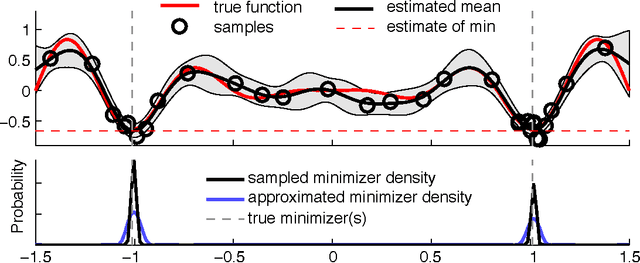
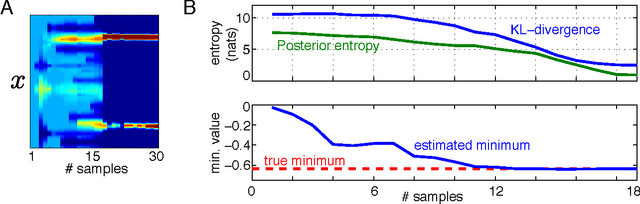
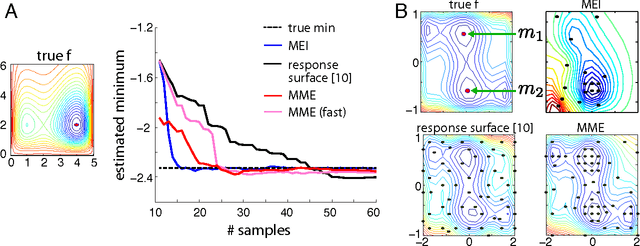
The ultimate goal of optimization is to find the minimizer of a target function.However, typical criteria for active optimization often ignore the uncertainty about the minimizer. We propose a novel criterion for global optimization and an associated sequential active learning strategy using Gaussian processes.Our criterion is the reduction of uncertainty in the posterior distribution of the function minimizer. It can also flexibly incorporate multiple global minimizers. We implement a tractable approximation of the criterion and demonstrate that it obtains the global minimizer accurately compared to conventional Bayesian optimization criteria.