 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining First Impressions: Modeling, Recognizing, and Explaining Apparent Personality from Videos
Oct 15, 2018
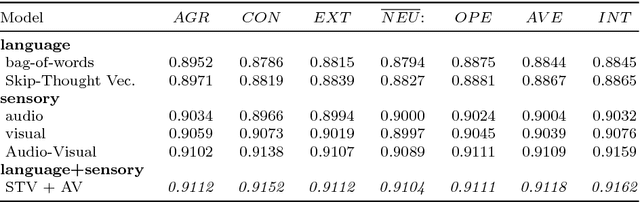
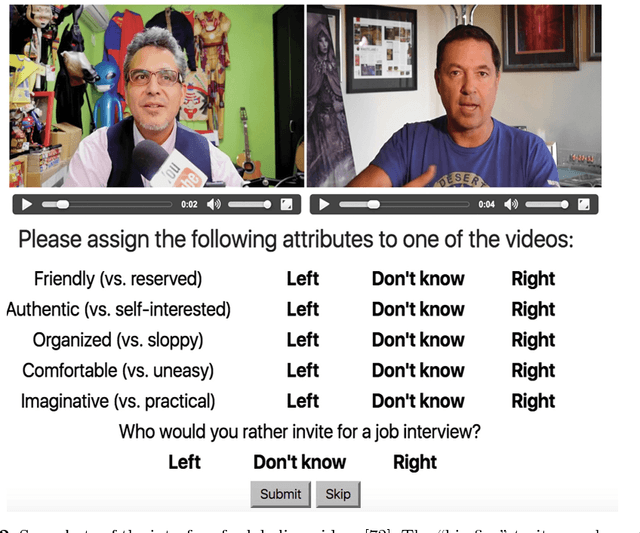
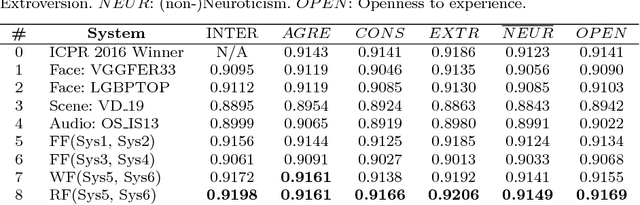
Explainability and interpretability are two critical aspects of decision support systems. Within computer vision, they are critical in certain tasks related to human behavior analysis such as in health care applications. Despite their importance, it is only recently that researchers are starting to explore these aspects. This paper provides an introduction to explainability and interpretability in the context of computer vision with an emphasis on looking at people tasks. Specifically, we review and study those mechanisms in the context of first impressions analysis. To the best of our knowledge, this is the first effort in this direction. Additionally, we describe a challenge we organized on explainability in first impressions analysis from video. We analyze in detail the newly introduced data set, the evaluation protocol, and summarize the results of the challenge. Finally, derived from our study, we outline research opportunities that we foresee will be decisive in the near future for the development of the explainable computer vision field.
Wasserstein Variational Inference
Jun 04, 2018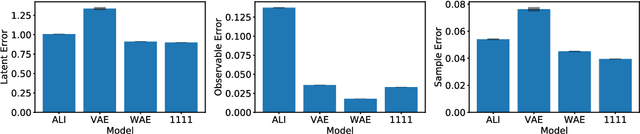
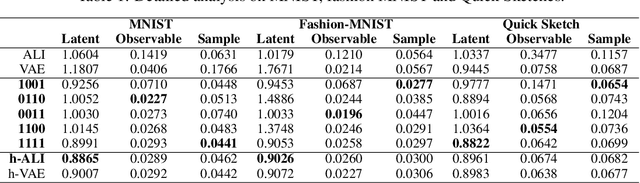

This paper introduces Wasserstein variational inference, a new form of approximate Bayesian inference based on optimal transport theory. Wasserstein variational inference uses a new family of divergences that includes both f-divergences and the Wasserstein distance as special cases. The gradients of the Wasserstein variational loss are obtained by backpropagating through the Sinkhorn iterations. This technique results in a very stable likelihood-free training method that can be used with implicit distributions and probabilistic programs. Using the Wasserstein variational inference framework, we introduce several new forms of autoencoders and test their robustness and performance against existing variational autoencoding techniques.
Forward Amortized Inference for Likelihood-Free Variational Marginalization
May 29, 2018
In this paper, we introduce a new form of amortized variational inference by using the forward KL divergence in a joint-contrastive variational loss. The resulting forward amortized variational inference is a likelihood-free method as its gradient can be sampled without bias and without requiring any evaluation of either the model joint distribution or its derivatives. We prove that our new variational loss is optimized by the exact posterior marginals in the fully factorized mean-field approximation, a property that is not shared with the more conventional reverse KL inference. Furthermore, we show that forward amortized inference can be easily marginalized over large families of latent variables in order to obtain a marginalized variational posterior. We consider two examples of variational marginalization. In our first example we train a Bayesian forecaster for predicting a simplified chaotic model of atmospheric convection. In the second example we train an amortized variational approximation of a Bayesian optimal classifier by marginalizing over the model space. The result is a powerful meta-classification network that can solve arbitrary classification problems without further training.
First Impressions: A Survey on Computer Vision-Based Apparent Personality Trait Analysis
Apr 21, 2018
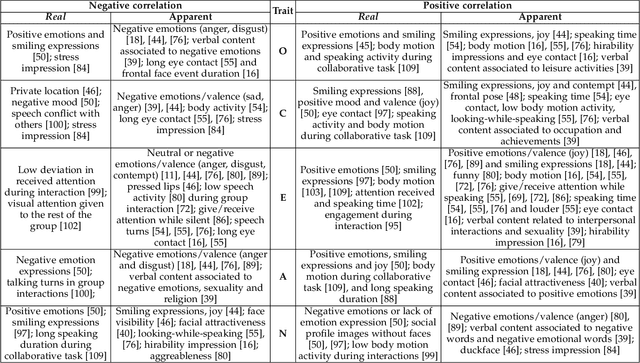
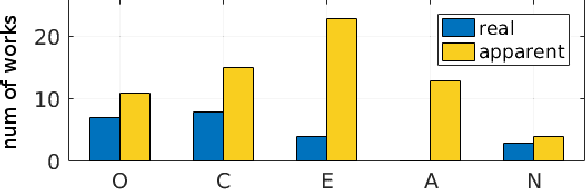
Personality analysis has been widely studied in psychology, neuropsychology, signal processing fields, among others. From the computing point of view, by far speech and text have been the most analyzed cues of information for analyzing personality. However, recently there has been an increasing interest form the computer vision community in analyzing personality starting from visual information. Recent computer vision approaches are able to accurately analyze human faces, body postures and behaviors, and use these information to infer apparent personality traits. Because of the overwhelming research interest in this topic, and of the potential impact that this sort of methods could have in society, we present in this paper an up-to-date review of existing computer vision-based visual and multimodal approaches for apparent personality trait recognition. We describe seminal and cutting edge works on the subject, discussing and comparing their distinctive features. More importantly, future venues of research in the field are identified and discussed. Furthermore, aspects on the subjectivity in data labeling/evaluation, as well as current datasets and challenges organized to push the research on the field are reviewed. Hence, the survey provides an up-to-date review of research progress in a wide range of aspects of this research theme.
The Kernel Mixture Network: A Nonparametric Method for Conditional Density Estimation of Continuous Random Variables
May 19, 2017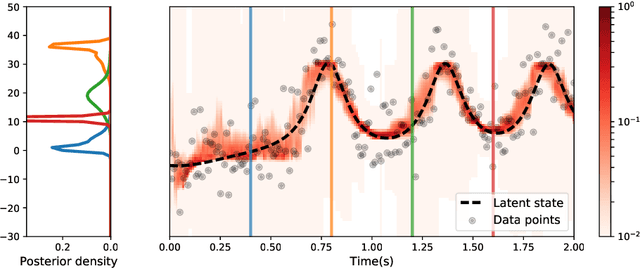
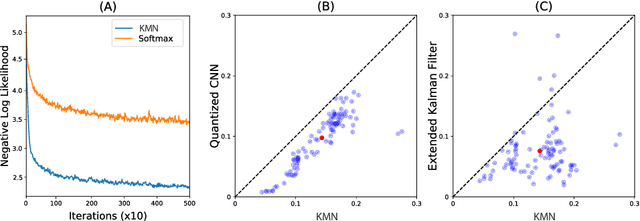
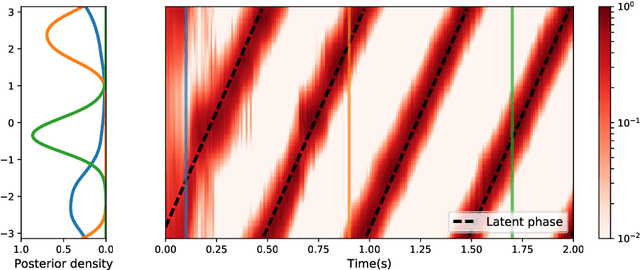
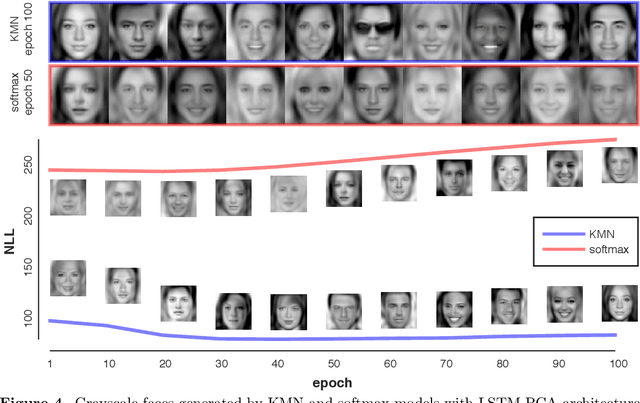
This paper introduces the kernel mixture network, a new method for nonparametric estimation of conditional probability densities using neural networks. We model arbitrarily complex conditional densities as linear combinations of a family of kernel functions centered at a subset of training points. The weights are determined by the outer layer of a deep neural network, trained by minimizing the negative log likelihood. This generalizes the popular quantized softmax approach, which can be seen as a kernel mixture network with square and non-overlapping kernels. We test the performance of our method on two important applications, namely Bayesian filtering and generative modeling. In the Bayesian filtering example, we show that the method can be used to filter complex nonlinear and non-Gaussian signals defined on manifolds. The resulting kernel mixture network filter outperforms both the quantized softmax filter and the extended Kalman filter in terms of model likelihood. Finally, our experiments on generative models show that, given the same architecture, the kernel mixture network leads to higher test set likelihood, less overfitting and more diversified and realistic generated samples than the quantized softmax approach.
End-to-end semantic face segmentation with conditional random fields as convolutional, recurrent and adversarial networks
Mar 09, 2017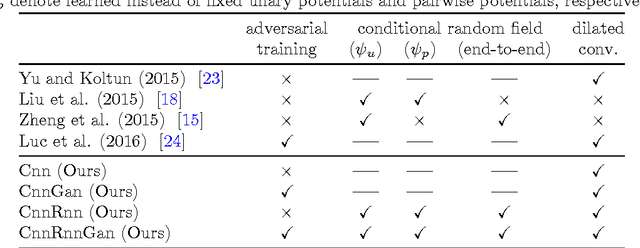
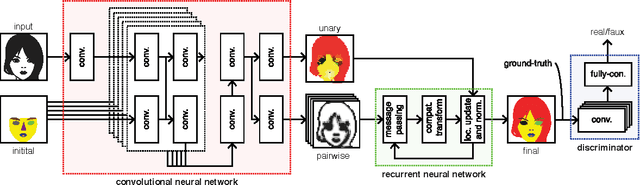
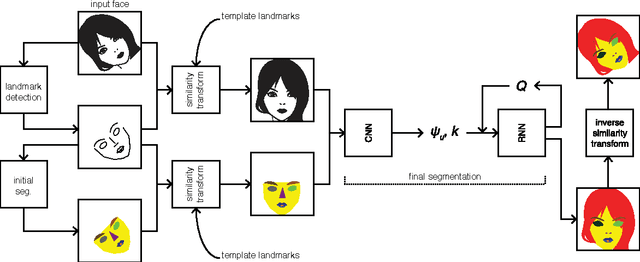
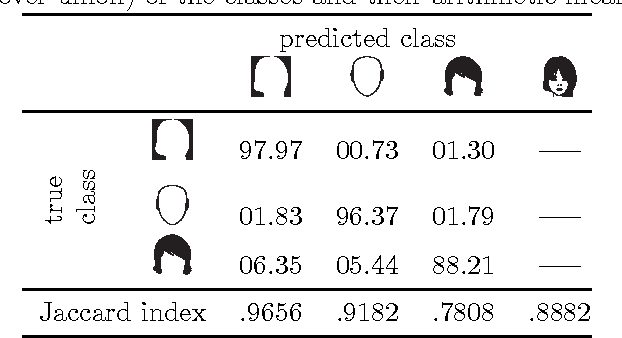
Recent years have seen a sharp increase in the number of related yet distinct advances in semantic segmentation. Here, we tackle this problem by leveraging the respective strengths of these advances. That is, we formulate a conditional random field over a four-connected graph as end-to-end trainable convolutional and recurrent networks, and estimate them via an adversarial process. Importantly, our model learns not only unary potentials but also pairwise potentials, while aggregating multi-scale contexts and controlling higher-order inconsistencies. We evaluate our model on two standard benchmark datasets for semantic face segmentation, achieving state-of-the-art results on both of them.
Deep Impression: Audiovisual Deep Residual Networks for Multimodal Apparent Personality Trait Recognition
Sep 16, 2016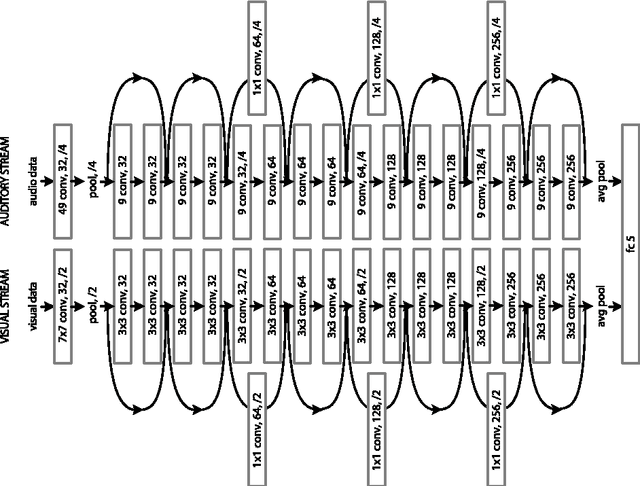
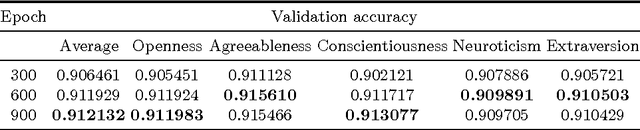
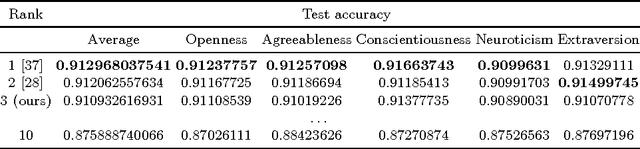

Here, we develop an audiovisual deep residual network for multimodal apparent personality trait recognition. The network is trained end-to-end for predicting the Big Five personality traits of people from their videos. That is, the network does not require any feature engineering or visual analysis such as face detection, face landmark alignment or facial expression recognition. Recently, the network won the third place in the ChaLearn First Impressions Challenge with a test accuracy of 0.9109.
Convolutional Sketch Inversion
Jun 09, 2016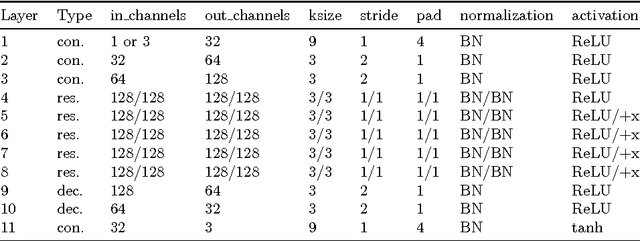



In this paper, we use deep neural networks for inverting face sketches to synthesize photorealistic face images. We first construct a semi-simulated dataset containing a very large number of computer-generated face sketches with different styles and corresponding face images by expanding existing unconstrained face data sets. We then train models achieving state-of-the-art results on both computer-generated sketches and hand-drawn sketches by leveraging recent advances in deep learning such as batch normalization, deep residual learning, perceptual losses and stochastic optimization in combination with our new dataset. We finally demonstrate potential applications of our models in fine arts and forensic arts. In contrast to existing patch-based approaches, our deep-neural-network-based approach can be used for synthesizing photorealistic face images by inverting face sketches in the wild.
Dynamic Decomposition of Spatiotemporal Neural Signals
May 09, 2016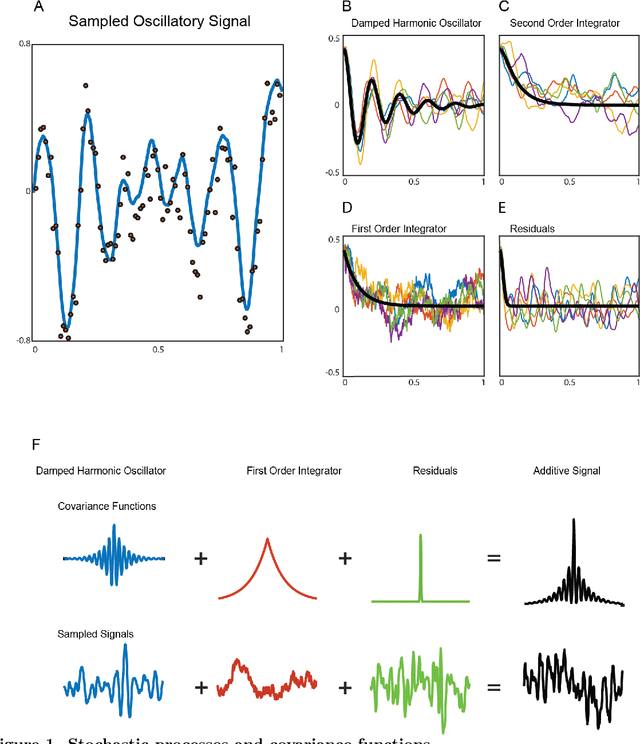
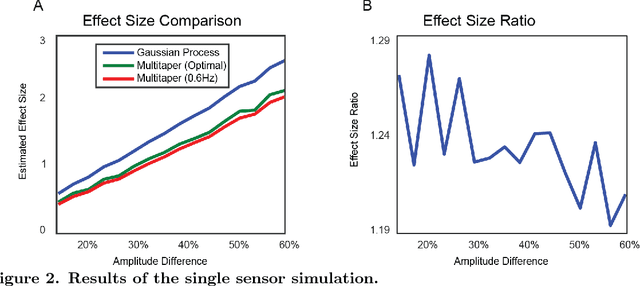
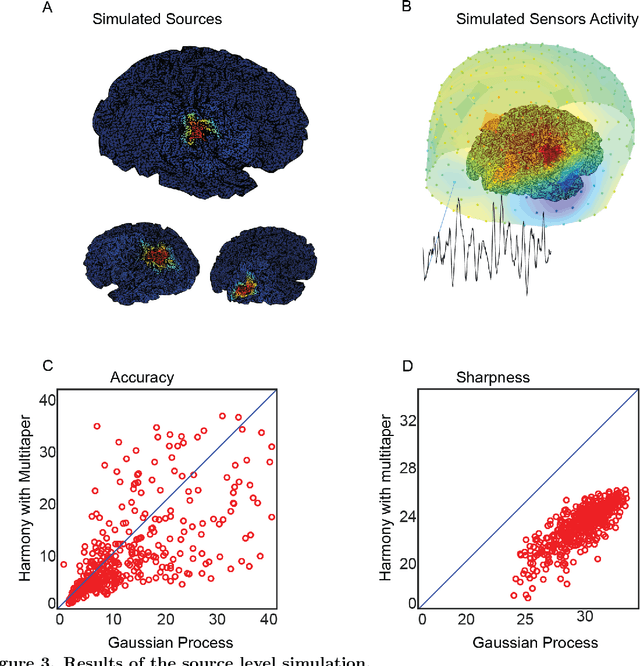
Neural signals are characterized by rich temporal and spatiotemporal dynamics that reflect the organization of cortical networks. Theoretical research has shown how neural networks can operate at different dynamic ranges that correspond to specific types of information processing. Here we present a data analysis framework that uses a linearized model of these dynamic states in order to decompose the measured neural signal into a series of components that capture both rhythmic and non-rhythmic neural activity. The method is based on stochastic differential equations and Gaussian process regression. Through computer simulations and analysis of magnetoencephalographic data, we demonstrate the efficacy of the method in identifying meaningful modulations of oscillatory signals corrupted by structured temporal and spatiotemporal noise. These results suggest that the method is particularly suitable for the analysis and interpretation of complex temporal and spatiotemporal neural signals.
Regularizing Solutions to the MEG Inverse Problem Using Space-Time Separable Covariance Functions
Apr 17, 2016
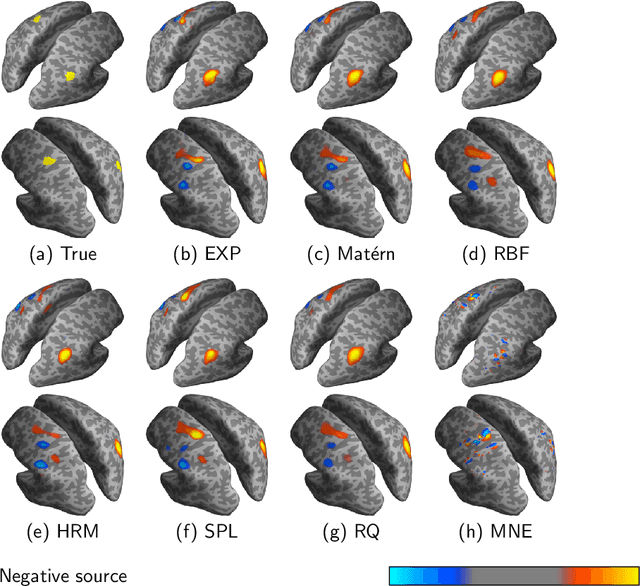
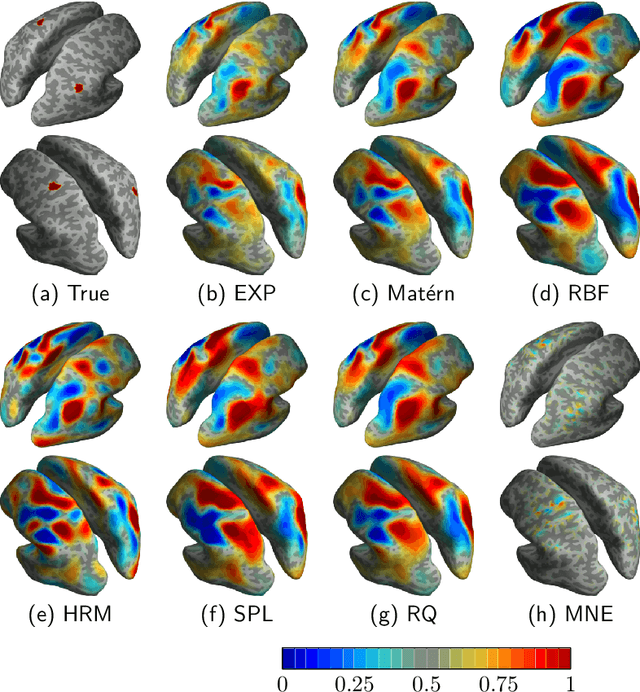

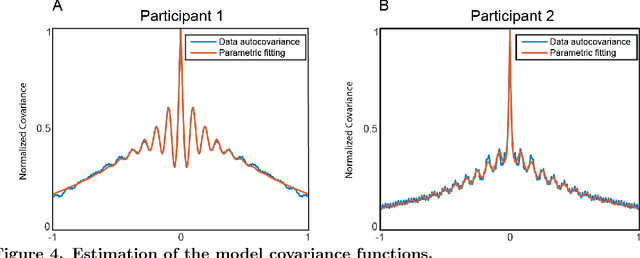
In magnetoencephalography (MEG) the conventional approach to source reconstruction is to solve the underdetermined inverse problem independently over time and space. Here we present how the conventional approach can be extended by regularizing the solution in space and time by a Gaussian process (Gaussian random field) model. Assuming a separable covariance function in space and time, the computational complexity of the proposed model becomes (without any further assumptions or restrictions) $\mathcal{O}(t^3 + n^3 + m^2n)$, where $t$ is the number of time steps, $m$ is the number of sources, and $n$ is the number of sensors. We apply the method to both simulated and empirical data, and demonstrate the efficiency and generality of our Bayesian source reconstruction approach which subsumes various classical approaches in the literature.