 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Hidden Physics Behind Transport Dynamics
Nov 24, 2020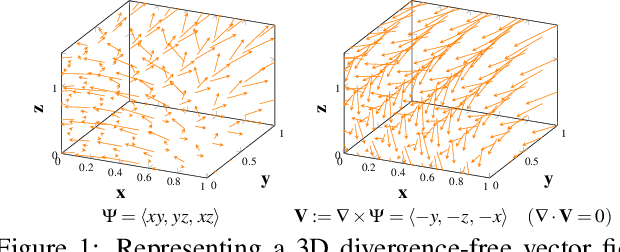
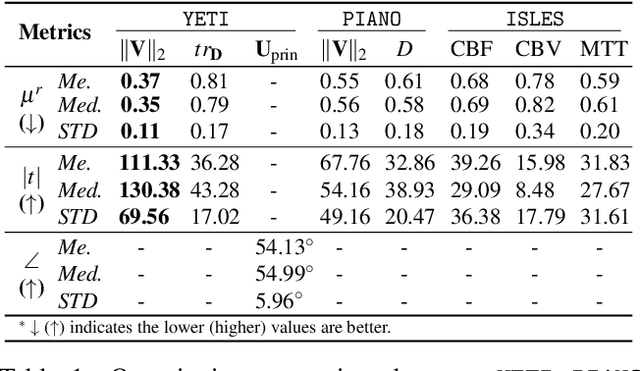

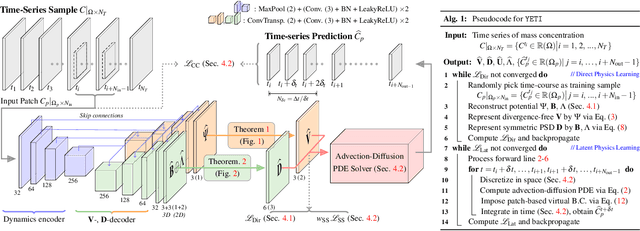
Transport processes are ubiquitous. They are, for example, at the heart of optical flow approaches; or of perfusion imaging, where blood transport is assessed, most commonly by injecting a tracer. An advection-diffusion equation is widely used to describe these transport phenomena. Our goal is estimating the underlying physics of advection-diffusion equations, expressed as velocity and diffusion tensor fields. We propose a learning framework (YETI) building on an auto-encoder structure between 2D and 3D image time-series, which incorporates the advection-diffusion model. To help with identifiability, we develop an advection-diffusion simulator which allows pre-training of our model by supervised learning using the velocity and diffusion tensor fields. Instead of directly learning these velocity and diffusion tensor fields, we introduce representations that assure incompressible flow and symmetric positive semi-definite diffusion fields and demonstrate the additional benefits of these representations on improving estimation accuracy. We further use transfer learning to apply YETI on a public brain magnetic resonance (MR) perfusion dataset of stroke patients and show its ability to successfully distinguish stroke lesions from normal brain regions via the estimated velocity and diffusion tensor fields.
VoteNet++: Registration Refinement for Multi-Atlas Segmentation
Oct 26, 2020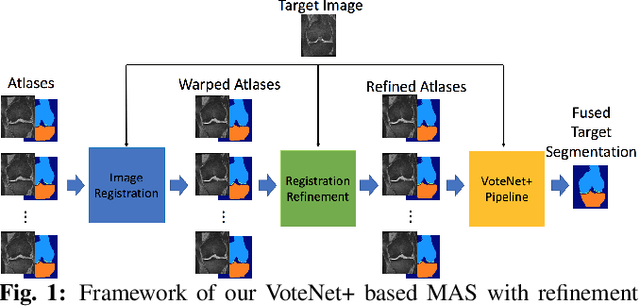
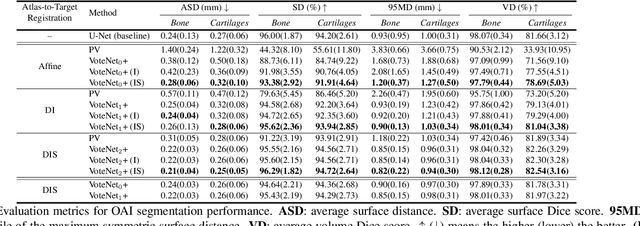
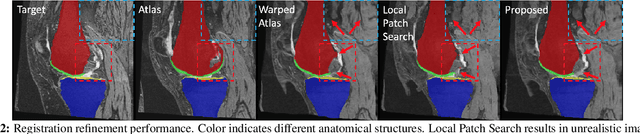
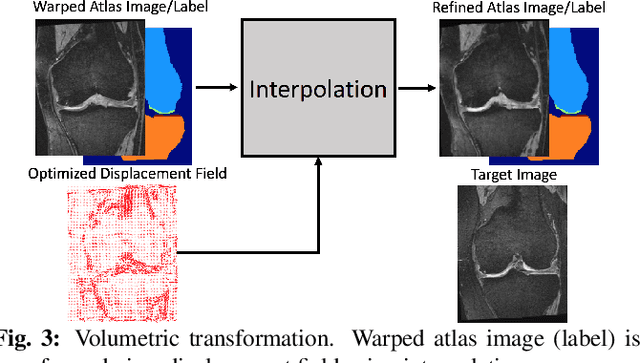
Multi-atlas segmentation (MAS) is a popular image segmentation technique for medical images. In this work, we improve the performance of MAS by correcting registration errors before label fusion. Specifically, we use a volumetric displacement field to refine registrations based on image anatomical appearance and predicted labels. We show the influence of the initial spatial alignment as well as the beneficial effect of using label information for MAS performance. Experiments demonstrate that the proposed refinement approach improves MAS performance on a 3D magnetic resonance dataset of the knee.
Perfusion Imaging: A Data Assimilation Approach
Sep 06, 2020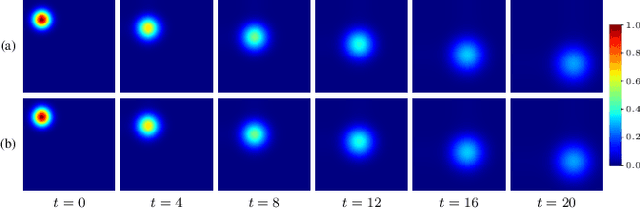
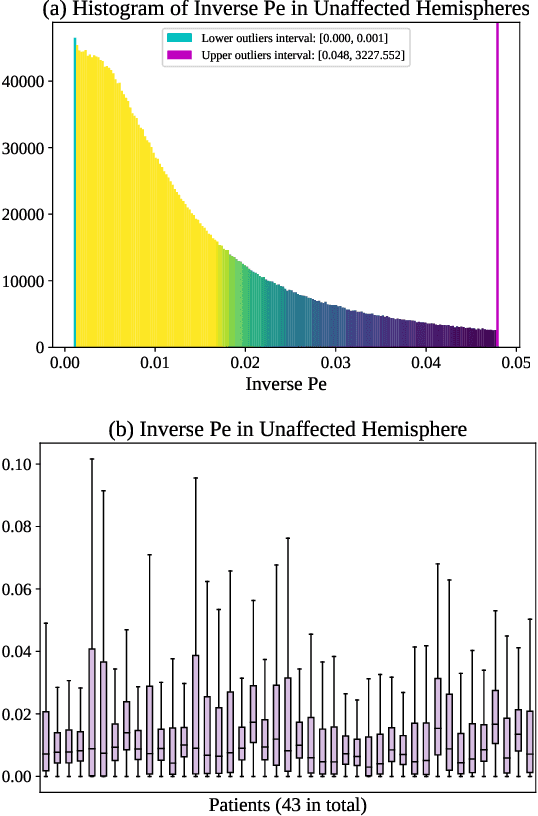
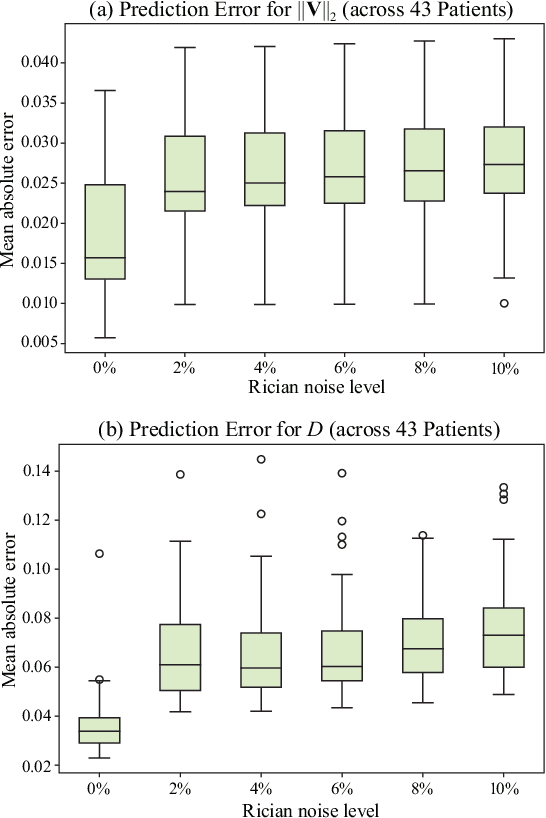
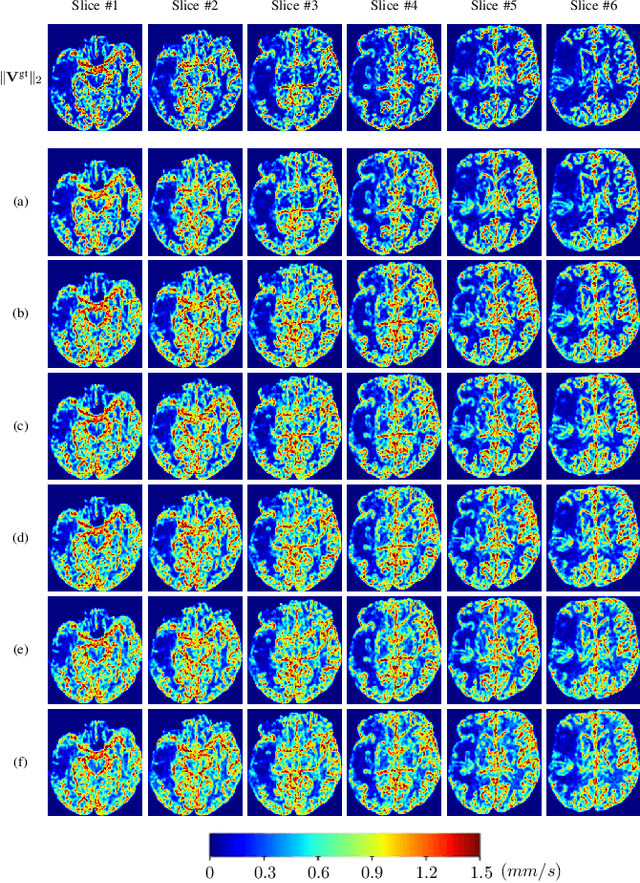
Perfusion imaging (PI) is clinically used to assess strokes and brain tumors. Commonly used PI approaches based on magnetic resonance imaging (MRI) or computed tomography (CT) measure the effect of a contrast agent moving through blood vessels and into tissue. Contrast-agent free approaches, for example, based on intravoxel incoherent motion, also exist, but are so far not routinely used clinically. These methods rely on estimating on the arterial input function (AIF) to approximately model tissue perfusion, neglecting spatial dependencies, and reliably estimating the AIF is also non-trivial, leading to difficulties with standardizing perfusion measures. In this work we therefore propose a data-assimilation approach (PIANO) which estimates the velocity and diffusion fields of an advection-diffusion model that best explains the contrast dynamics. PIANO accounts for spatial dependencies and neither requires estimating the AIF nor relies on a particular contrast agent bolus shape. Specifically, we propose a convenient parameterization of the estimation problem, a numerical estimation approach, and extensively evaluate PIANO. We demonstrate that PIANO can successfully resolve velocity and diffusion field ambiguities and results in sensitive measures for the assessment of stroke, comparing favorably to conventional measures of perfusion.
The Fairness-Accuracy Pareto Front
Aug 25, 2020
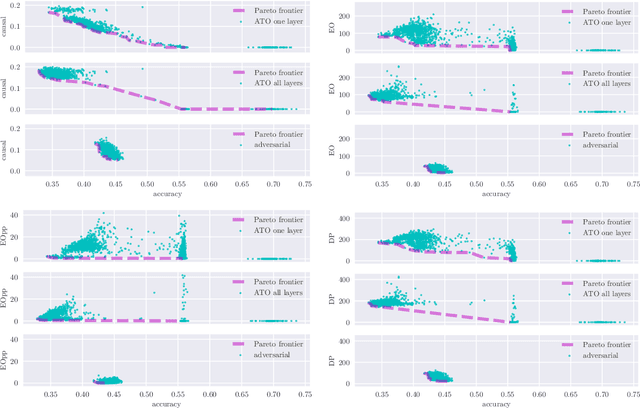

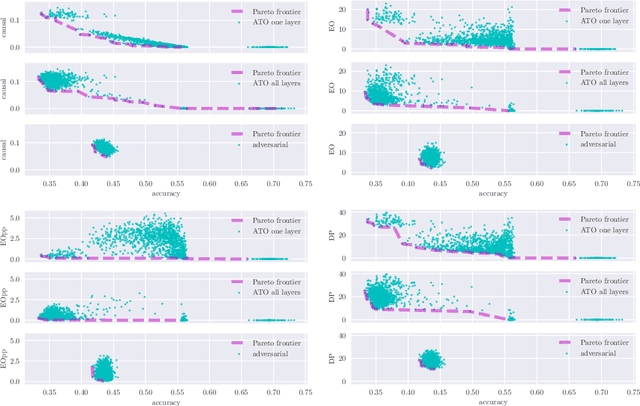
Mitigating bias in machine learning is a challenging task, due in large part to the presence of competing objectives. Namely, a fair algorithm often comes at the cost of lower predictive accuracy, and vice versa, a highly predictive algorithm may be one that incurs high bias. This work presents a methodology for estimating the fairness-accuracy Pareto front of a fully-connected feedforward neural network, for any accuracy measure and any fairness measure. Our experiments firstly reveal that for training data already exhibiting disparities, a newly introduced causal notion of fairness may be capable of traversing a greater part of the fairness-accuracy space, relative to more standard measures such as demographic parity and conditional parity. The experiments also reveal that tools from multi-objective optimisation are crucial in efficiently estimating the Pareto front (i.e., by finding more non-dominated points), relative to other sensible but ad-hoc approaches. Finally, the work serves to highlight possible synergy between deep learning and multi-objective optimisation. Given that deep learning is increasingly deployed in real-world decision making, the Pareto front can provide a formal way to reason about inherent conflicts.
A Deep Network for Joint Registration and Reconstruction of Images with Pathologies
Aug 17, 2020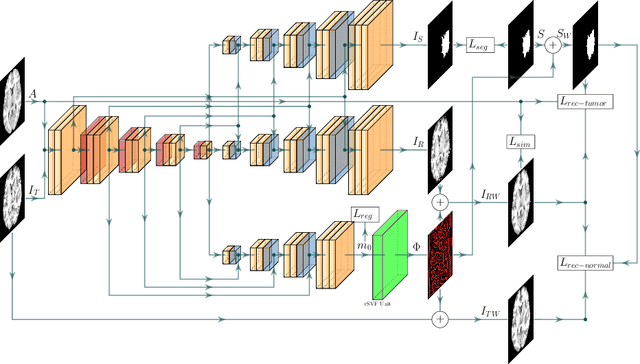
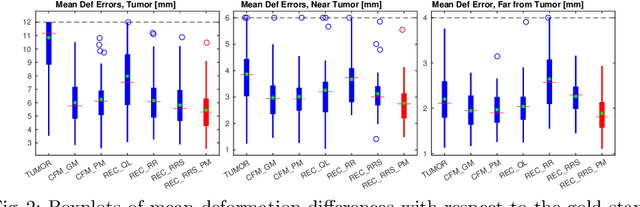
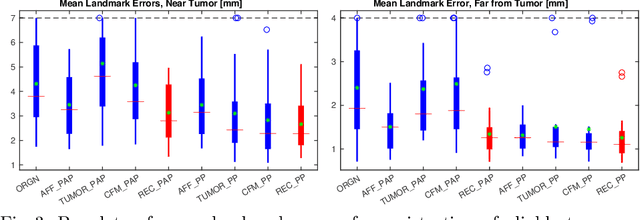
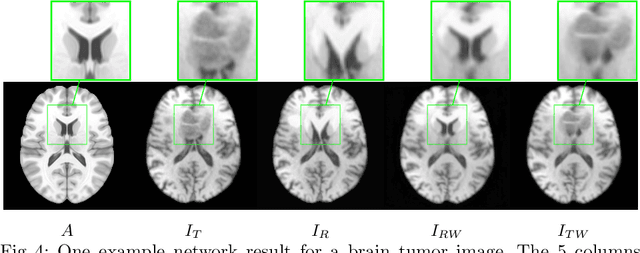
Registration of images with pathologies is challenging due to tissue appearance changes and missing correspondences caused by the pathologies. Moreover, mass effects as observed for brain tumors may displace tissue, creating larger deformations over time than what is observed in a healthy brain. Deep learning models have successfully been applied to image registration to offer dramatic speed up and to use surrogate information (e.g., segmentations) during training. However, existing approaches focus on learning registration models using images from healthy patients. They are therefore not designed for the registration of images with strong pathologies for example in the context of brain tumors, and traumatic brain injuries. In this work, we explore a deep learning approach to register images with brain tumors to an atlas. Our model learns an appearance mapping from images with tumors to the atlas, while simultaneously predicting the transformation to atlas space. Using separate decoders, the network disentangles the tumor mass effect from the reconstruction of quasi-normal images. Results on both synthetic and real brain tumor scans show that our approach outperforms cost function masking for registration to the atlas and that reconstructed quasi-normal images can be used for better longitudinal registrations.
Local Temperature Scaling for Probability Calibration
Aug 12, 2020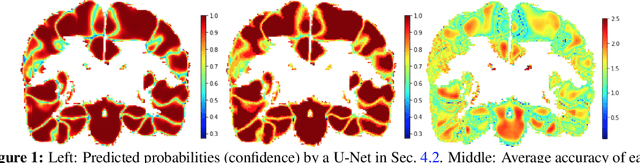
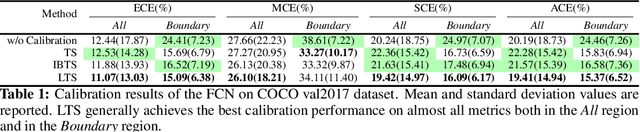


For semantic segmentation, label probabilities are often uncalibrated as they are typically only the by-product of a segmentation task. Intersection over Union (IoU) and Dice score are often used as criteria for segmentation success, while metrics related to label probabilities are rarely explored. On the other hand, probability calibration approaches have been studied, which aim at matching probability outputs with experimentally observed errors, but they mainly focus on classification tasks, not on semantic segmentation. Thus, we propose a learning-based calibration method that focuses on multi-label semantic segmentation. Specifically, we adopt a tree-like convolution neural network to predict local temperature values for probability calibration. One advantage of our approach is that it does not change prediction accuracy, hence allowing for calibration as a post-processing step. Experiments on the COCO and LPBA40 datasets demonstrate improved calibration performance over different metrics. We also demonstrate the performance of our method for multi-atlas brain segmentation from magnetic resonance images.
Robust and Generalizable Visual Representation Learning via Random Convolutions
Jul 25, 2020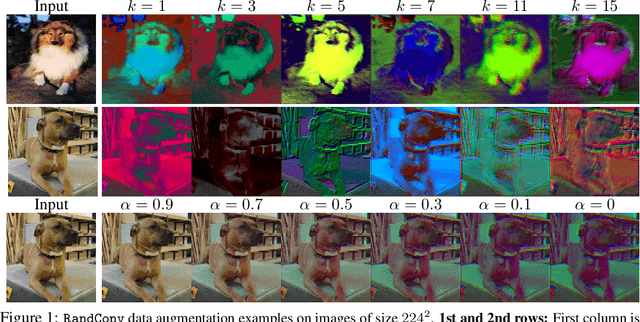
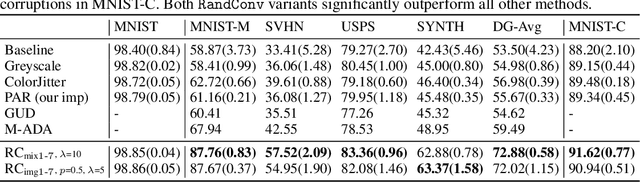
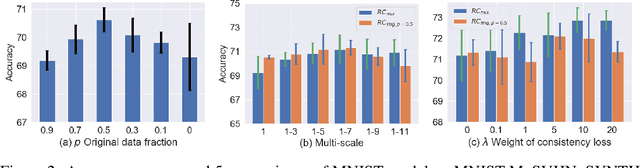
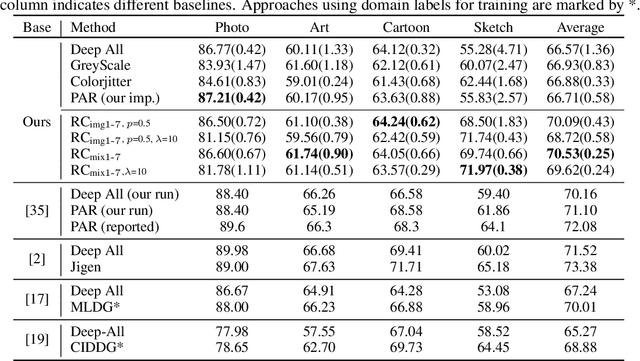
While successful for various computer vision tasks, deep neural networks have shown to be vulnerable to texture style shifts and small perturbations to which humans are robust. Hence, our goal is to train models in such a way that improves their robustness to these perturbations. We are motivated by the approximately shape-preserving property of randomized convolutions, which is due to distance preservation under random linear transforms. Intuitively, randomized convolutions create an infinite number of new domains with similar object shapes but random local texture. Therefore, we explore using outputs of multi-scale random convolutions as new images or mixing them with the original images during training. When applying a network trained with our approach to unseen domains, our method consistently improves the performance on domain generalization benchmarks and is scalable to ImageNet. Especially for the challenging scenario of generalizing to the sketch domain in PACS and to ImageNet-Sketch, our method outperforms state-of-art methods by a large margin. More interestingly, our method can benefit downstream tasks by providing a more robust pretrained visual representation.
Anatomical Data Augmentation via Fluid-based Image Registration
Jul 05, 2020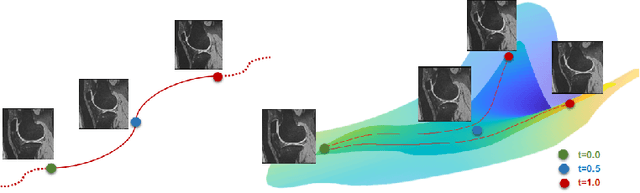
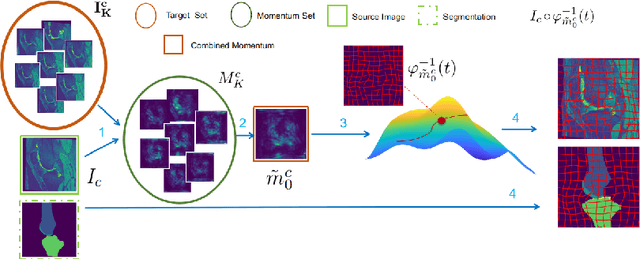
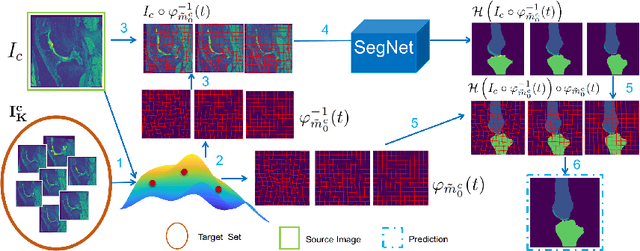
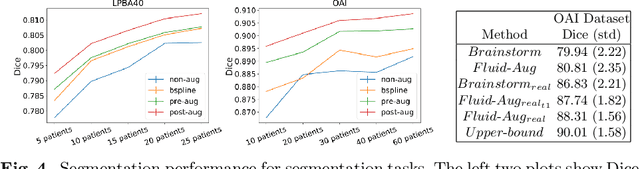
We introduce a fluid-based image augmentation method for medical image analysis. In contrast to existing methods, our framework generates anatomically meaningful images via interpolation from the geodesic subspace underlying given samples. Our approach consists of three steps: 1) given a source image and a set of target images, we construct a geodesic subspace using the Large Deformation Diffeomorphic Metric Mapping (LDDMM) model; 2) we sample transformations from the resulting geodesic subspace; 3) we obtain deformed images and segmentations via interpolation. Experiments on brain (LPBA) and knee (OAI) data illustrate the performance of our approach on two tasks: 1) data augmentation during training and testing for image segmentation; 2) one-shot learning for single atlas image segmentation. We demonstrate that our approach generates anatomically meaningful data and improves performance on these tasks over competing approaches. Code is available at https://github.com/uncbiag/easyreg.
A Shooting Formulation of Deep Learning
Jun 18, 2020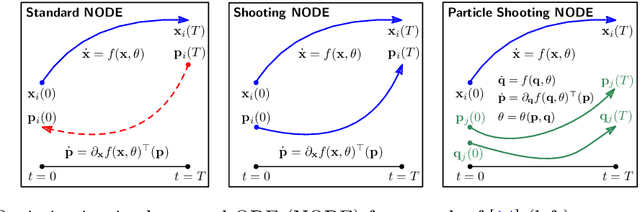
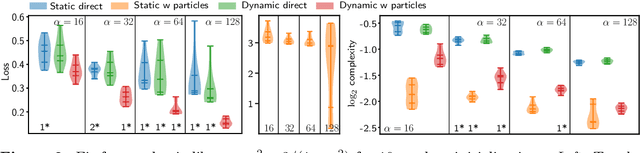
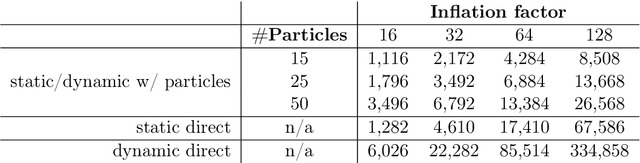
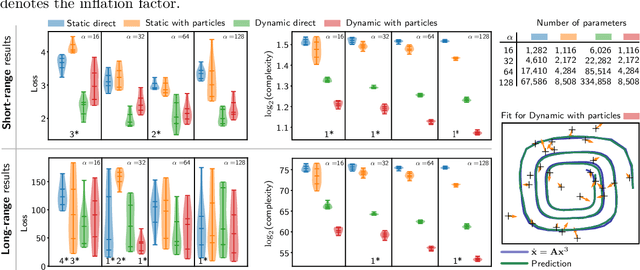
Continuous-depth neural networks can be viewed as deep limits of discrete neural networks whose dynamics resemble a discretization of an ordinary differential equation (ODE). Although important steps have been taken to realize the advantages of such continuous formulations, most current techniques are not truly continuous-depth as they assume identical layers. Indeed, existing works throw into relief the myriad difficulties presented by an infinite-dimensional parameter space in learning a continuous-depth neural ODE. To this end, we introduce a shooting formulation which shifts the perspective from parameterizing a network layer-by-layer to parameterizing over optimal networks described only by a set of initial conditions. For scalability, we propose a novel particle-ensemble parametrization which fully specifies the optimal weight trajectory of the continuous-depth neural network. Our experiments show that our particle-ensemble shooting formulation can achieve competitive performance, especially on long-range forecasting tasks. Finally, though the current work is inspired by continuous-depth neural networks, the particle-ensemble shooting formulation also applies to discrete-time networks and may lead to a new fertile area of research in deep learning parametrization.
Deep Goal-Oriented Clustering
Jun 16, 2020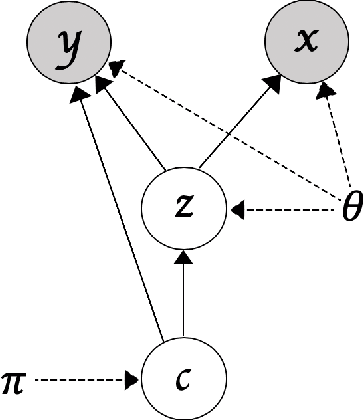
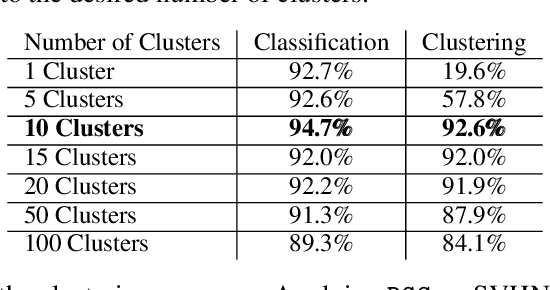
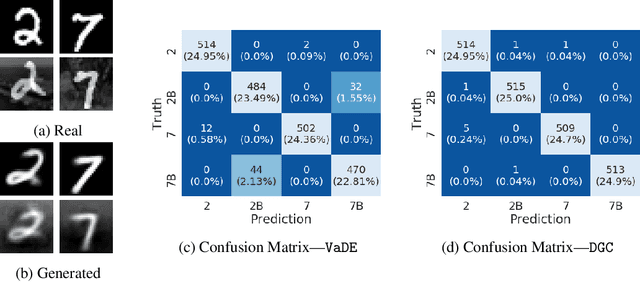
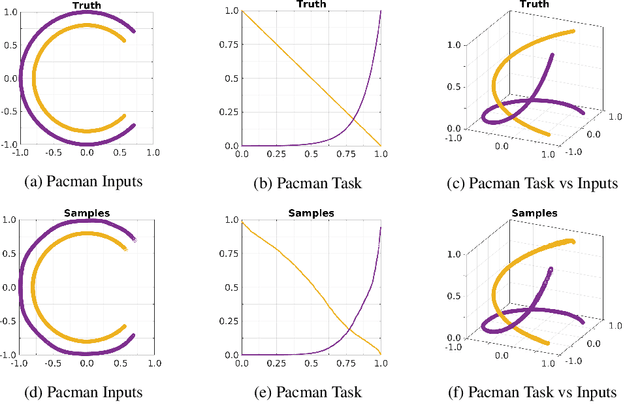
Clustering and prediction are two primary tasks in the fields of unsupervised and supervised learning, respectively. Although much of the recent advances in machine learning have been centered around those two tasks, the interdependent, mutually beneficial relationship between them is rarely explored. One could reasonably expect appropriately clustering the data would aid the downstream prediction task and, conversely, a better prediction performance for the downstream task could potentially inform a more appropriate clustering strategy. In this work, we focus on the latter part of this mutually beneficial relationship. To this end, we introduce Deep Goal-Oriented Clustering (DGC), a probabilistic framework that clusters the data by jointly using supervision via side-information and unsupervised modeling of the inherent data structure in an end-to-end fashion. We show the effectiveness of our model on a range of datasets by achieving prediction accuracies comparable to the state-of-the-art, while, more importantly in our setting, simultaneously learning congruent clustering strategies.