 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Landmark Learning with Deformation Reconstruction and Cross-subject Consistency Objectives
Aug 09, 2023A Point Distribution Model (PDM) is the basis of a Statistical Shape Model (SSM) that relies on a set of landmark points to represent a shape and characterize the shape variation. In this work, we present a self-supervised approach to extract landmark points from a given registration model for the PDMs. Based on the assumption that the landmarks are the points that have the most influence on registration, existing works learn a point-based registration model with a small number of points to estimate the landmark points that influence the deformation the most. However, such approaches assume that the deformation can be captured by point-based registration and quality landmarks can be learned solely with the deformation capturing objective. We argue that data with complicated deformations can not easily be modeled with point-based registration when only a limited number of points is used to extract influential landmark points. Further, landmark consistency is not assured in existing approaches In contrast, we propose to extract landmarks based on a given registration model, which is tailored for the target data, so we can obtain more accurate correspondences. Secondly, to establish the anatomical consistency of the predicted landmarks, we introduce a landmark discovery loss to explicitly encourage the model to predict the landmarks that are anatomically consistent across subjects. We conduct experiments on an osteoarthritis progression prediction task and show our method outperforms existing image-based and point-based approaches.
Multimodal Understanding Through Correlation Maximization and Minimization
May 04, 2023Multimodal learning has mainly focused on learning large models on, and fusing feature representations from, different modalities for better performances on downstream tasks. In this work, we take a detour from this trend and study the intrinsic nature of multimodal data by asking the following questions: 1) Can we learn more structured latent representations of general multimodal data?; and 2) can we intuitively understand, both mathematically and visually, what the latent representations capture? To answer 1), we propose a general and lightweight framework, Multimodal Understanding Through Correlation Maximization and Minimization (MUCMM), that can be incorporated into any large pre-trained network. MUCMM learns both the common and individual representations. The common representations capture what is common between the modalities; the individual representations capture the unique aspect of the modalities. To answer 2), we propose novel scores that summarize the learned common and individual structures and visualize the score gradients with respect to the input, visually discerning what the different representations capture. We further provide mathematical intuitions of the computed gradients in a linear setting, and demonstrate the effectiveness of our approach through a variety of experiments.
Inverse Consistency by Construction for Multistep Deep Registration
Apr 28, 2023Inverse consistency is a desirable property for image registration. We propose a simple technique to make a neural registration network inverse consistent by construction, as a consequence of its structure, as long as it parameterizes its output transform by a Lie group. We extend this technique to multi-step neural registration by composing many such networks in a way that preserves inverse consistency. This multi-step approach also allows for inverse-consistent coarse to fine registration. We evaluate our technique on synthetic 2-D data and four 3-D medical image registration tasks and obtain excellent registration accuracy while assuring inverse consistency.
Unsupervised Discovery of 3D Hierarchical Structure with Generative Diffusion Features
Apr 28, 2023



Inspired by recent findings that generative diffusion models learn semantically meaningful representations, we use them to discover the intrinsic hierarchical structure in biomedical 3D images using unsupervised segmentation. We show that features of diffusion models from different stages of a U-Net-based ladder-like architecture capture different hierarchy levels in 3D biomedical images. We design three losses to train a predictive unsupervised segmentation network that encourages the decomposition of 3D volumes into meaningful nested subvolumes that represent a hierarchy. First, we pretrain 3D diffusion models and use the consistency of their features across subvolumes. Second, we use the visual consistency between subvolumes. Third, we use the invariance to photometric augmentations as a regularizer. Our models achieve better performance than prior unsupervised structure discovery approaches on challenging biologically-inspired synthetic datasets and on a real-world brain tumor MRI dataset.
NAISR: A 3D Neural Additive Model for Interpretable Shape Representation
Mar 28, 2023



Deep implicit functions (DIFs) have emerged as a powerful paradigm for many computer vision tasks such as 3D shape reconstruction, generation, registration, completion, editing, and understanding. However, given a set of 3D shapes with associated covariates there is at present no shape representation method which allows to precisely represent the shapes while capturing the individual dependencies on each covariate. Such a method would be of high utility to researchers to discover knowledge hidden in a population of shapes. We propose a 3D Neural Additive Model for Interpretable Shape Representation (NAISR) which describes individual shapes by deforming a shape atlas in accordance to the effect of disentangled covariates. Our approach captures shape population trends and allows for patient-specific predictions through shape transfer. NAISR is the first approach to combine the benefits of deep implicit shape representations with an atlas deforming according to specified covariates. Although our driving problem is the construction of an airway atlas, NAISR is a general approach for modeling, representing, and investigating shape populations. We evaluate NAISR with respect to shape reconstruction, shape disentanglement, shape evolution, and shape transfer for the pediatric upper airway. Our experiments demonstrate that NAISR achieves competitive shape reconstruction performance while retaining interpretability.
MRIS: A Multi-modal Retrieval Approach for Image Synthesis on Diverse Modalities
Mar 17, 2023Multiple imaging modalities are often used for disease diagnosis, prediction, or population-based analyses. However, not all modalities might be available due to cost, different study designs, or changes in imaging technology. If the differences between the types of imaging are small, data harmonization approaches can be used; for larger changes, direct image synthesis approaches have been explored. In this paper, we develop an approach based on multi-modal metric learning to synthesize images of diverse modalities. We use metric learning via multi-modal image retrieval, resulting in embeddings that can relate images of different modalities. Given a large image database, the learned image embeddings allow us to use k-nearest neighbor (k-NN) regression for image synthesis. Our driving medical problem is knee osteoarthritis (KOA), but our developed method is general after proper image alignment. We test our approach by synthesizing cartilage thickness maps obtained from 3D magnetic resonance (MR) images using 2D radiographs. Our experiments show that the proposed method outperforms direct image synthesis and that the synthesized thickness maps retain information relevant to downstream tasks such as progression prediction and Kellgren-Lawrence grading (KLG). Our results suggest that retrieval approaches can be used to obtain high-quality and meaningful image synthesis results given large image databases.
Exploring Cycle Consistency Learning in Interactive Volume Segmentation
Mar 11, 2023Interactive volume segmentation can be approached via two decoupled modules: interaction-to-segmentation and segmentation propagation. Given a medical volume, a user first segments a slice (or several slices) via the interaction module and then propagates the segmentation(s) to the remaining slices. The user may repeat this process multiple times until a sufficiently high volume segmentation quality is achieved. However, due to the lack of human correction during propagation, segmentation errors are prone to accumulate in the intermediate slices and may lead to sub-optimal performance. To alleviate this issue, we propose a simple yet effective cycle consistency loss that regularizes an intermediate segmentation by referencing the accurate segmentation in the starting slice. To this end, we introduce a backward segmentation path that propagates the intermediate segmentation back to the starting slice using the same propagation network. With cycle consistency training, the propagation network is better regularized than in standard forward-only training approaches. Evaluation results on challenging benchmarks such as AbdomenCT-1k and OAI-ZIB demonstrate the effectiveness of our method. To the best of our knowledge, we are the first to explore cycle consistency learning in interactive volume segmentation.
Harmonization Benchmarking Tool for Neuroimaging Datasets
Nov 15, 2022



A major data pre-processing step for large, multi-site studies is to handle site effects by harmonizing data, generating a dataset that enables more powerful analyses and more robust algorithms. There is a wide variety of data harmonization techniques, but there are few tools that streamline the process of harmonizing data, comparing across techniques, and benchmarking new techniques. In this paper, we introduce HArmonization BEnchmarking Tool (HABET), an open source tool for generating harmonized images and evaluating the performance of different harmonization algorithms. To demonstrate the capabilities of HABET, we harmonize diffusion MRI images from the Adolescent Brain and Cognitive Development (ABCD) study using two different approaches, and we compare their performance.
Compositional Generalization in Unsupervised Compositional Representation Learning: A Study on Disentanglement and Emergent Language
Oct 05, 2022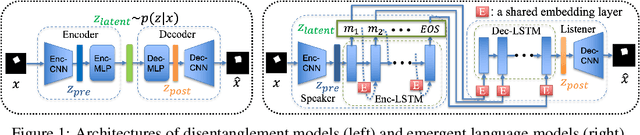

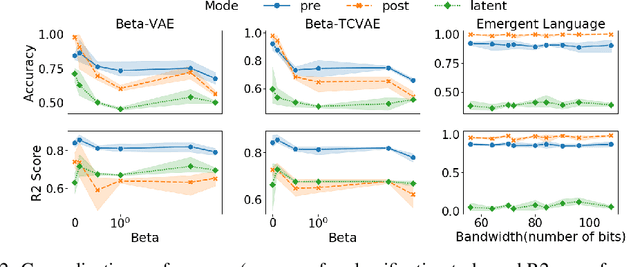

Deep learning models struggle with compositional generalization, i.e. the ability to recognize or generate novel combinations of observed elementary concepts. In hopes of enabling compositional generalization, various unsupervised learning algorithms have been proposed with inductive biases that aim to induce compositional structure in learned representations (e.g. disentangled representation and emergent language learning). In this work, we evaluate these unsupervised learning algorithms in terms of how well they enable compositional generalization. Specifically, our evaluation protocol focuses on whether or not it is easy to train a simple model on top of the learned representation that generalizes to new combinations of compositional factors. We systematically study three unsupervised representation learning algorithms - $\beta$-VAE, $\beta$-TCVAE, and emergent language (EL) autoencoders - on two datasets that allow directly testing compositional generalization. We find that directly using the bottleneck representation with simple models and few labels may lead to worse generalization than using representations from layers before or after the learned representation itself. In addition, we find that the previously proposed metrics for evaluating the levels of compositionality are not correlated with actual compositional generalization in our framework. Surprisingly, we find that increasing pressure to produce a disentangled representation produces representations with worse generalization, while representations from EL models show strong compositional generalization. Taken together, our results shed new light on the compositional generalization behavior of different unsupervised learning algorithms with a new setting to rigorously test this behavior, and suggest the potential benefits of delevoping EL learning algorithms for more generalizable representations.
Optimal Transport Features for Morphometric Population Analysis
Aug 11, 2022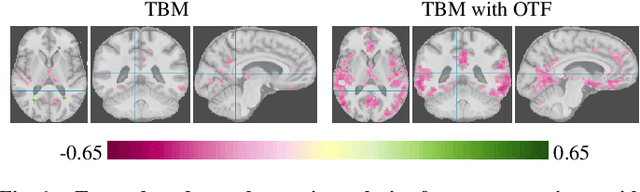
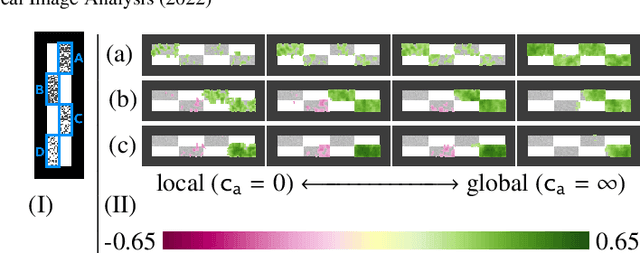
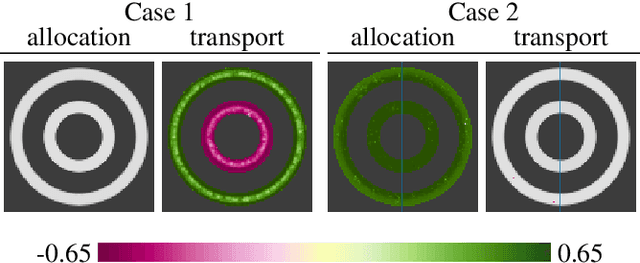
Brain pathologies often manifest as partial or complete loss of tissue. The goal of many neuroimaging studies is to capture the location and amount of tissue changes with respect to a clinical variable of interest, such as disease progression. Morphometric analysis approaches capture local differences in the distribution of tissue or other quantities of interest in relation to a clinical variable. We propose to augment morphometric analysis with an additional feature extraction step based on unbalanced optimal transport. The optimal transport feature extraction step increases statistical power for pathologies that cause spatially dispersed tissue loss, minimizes sensitivity to shifts due to spatial misalignment or differences in brain topology, and separates changes due to volume differences from changes due to tissue location. We demonstrate the proposed optimal transport feature extraction step in the context of a volumetric morphometric analysis of the OASIS-1 study for Alzheimer's disease. The results demonstrate that the proposed approach can identify tissue changes and differences that are not otherwise measurable.