 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartPaste: Learning to Adapt Source Code
May 22, 2017
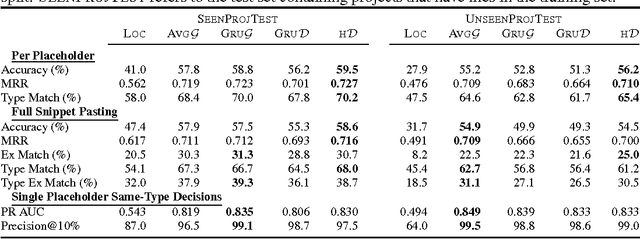

Deep Neural Networks have been shown to succeed at a range of natural language tasks such as machine translation and text summarization. While tasks on source code (ie, formal languages) have been considered recently, most work in this area does not attempt to capitalize on the unique opportunities offered by its known syntax and structure. In this work, we introduce SmartPaste, a first task that requires to use such information. The task is a variant of the program repair problem that requires to adapt a given (pasted) snippet of code to surrounding, existing source code. As first solutions, we design a set of deep neural models that learn to represent the context of each variable location and variable usage in a data flow-sensitive way. Our evaluation suggests that our models can learn to solve the SmartPaste task in many cases, achieving 58.6% accuracy, while learning meaningful representation of variable usages.
DeepCoder: Learning to Write Programs
Mar 08, 2017


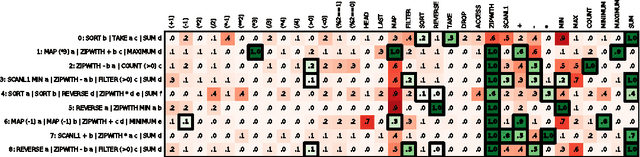
We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.
Differentiable Programs with Neural Libraries
Mar 02, 2017
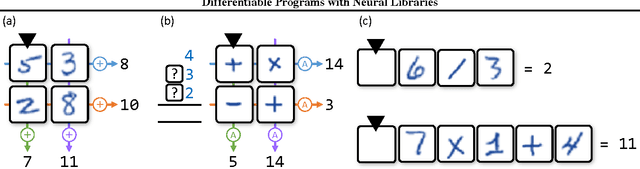

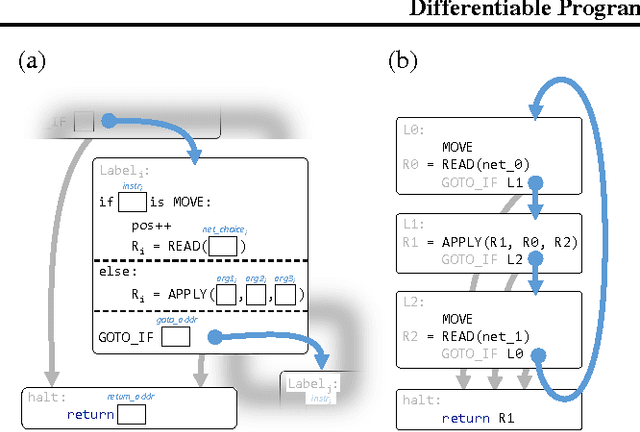
We develop a framework for combining differentiable programming languages with neural networks. Using this framework we create end-to-end trainable systems that learn to write interpretable algorithms with perceptual components. We explore the benefits of inductive biases for strong generalization and modularity that come from the program-like structure of our models. In particular, modularity allows us to learn a library of (neural) functions which grows and improves as more tasks are solved. Empirically, we show that this leads to lifelong learning systems that transfer knowledge to new tasks more effectively than baselines.
Differentiable Functional Program Interpreters
Mar 02, 2017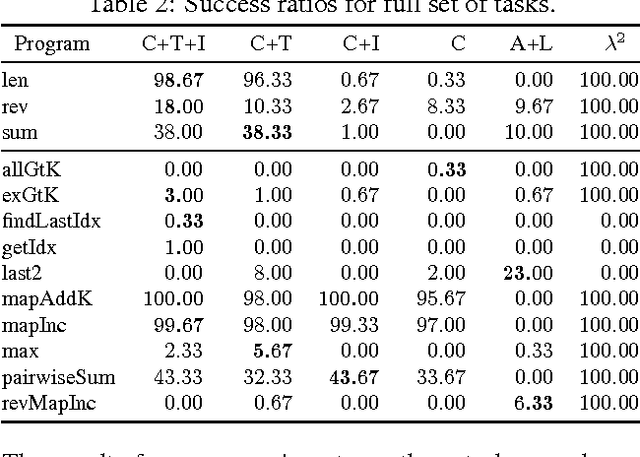
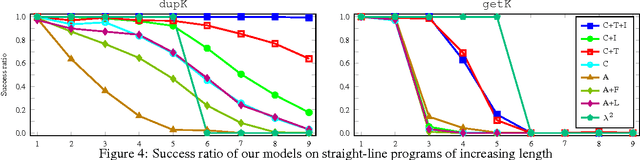
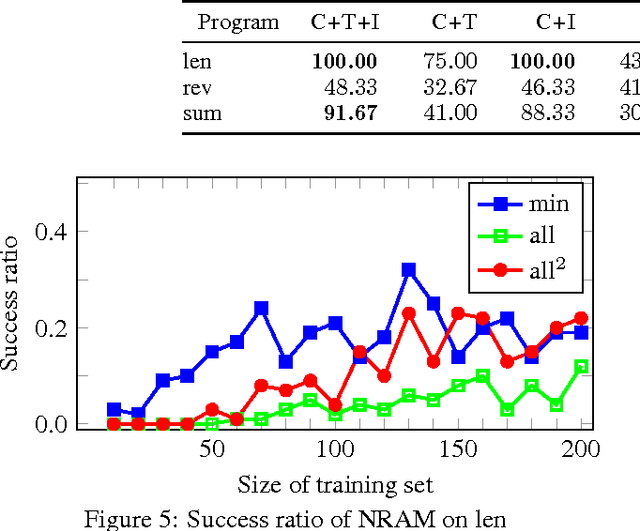

Programming by Example (PBE) is the task of inducing computer programs from input-output examples. It can be seen as a type of machine learning where the hypothesis space is the set of legal programs in some programming language. Recent work on differentiable interpreters relaxes the discrete space of programs into a continuous space so that search over programs can be performed using gradient-based optimization. While conceptually powerful, so far differentiable interpreter-based program synthesis has only been capable of solving very simple problems. In this work, we study modeling choices that arise when constructing a differentiable programming language and their impact on the success of synthesis. The main motivation for the modeling choices comes from functional programming: we study the effect of memory allocation schemes, immutable data, type systems, and built-in control-flow structures. Empirically we show that incorporating functional programming ideas into differentiable programming languages allows us to learn much more complex programs than is possible with existing differentiable languages.
Summary - TerpreT: A Probabilistic Programming Language for Program Induction
Dec 02, 2016
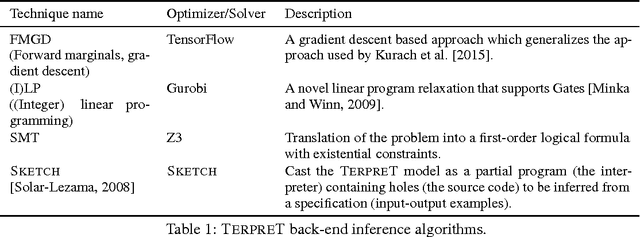
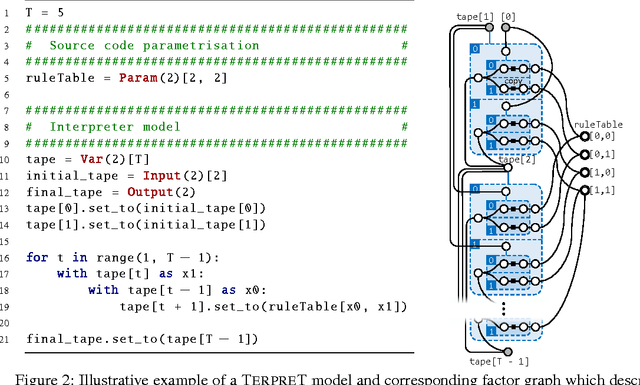
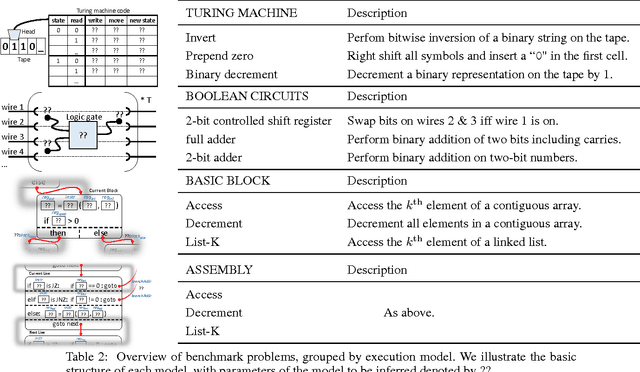
We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. This is a workshop summary of a longer report at arXiv:1608.04428
TerpreT: A Probabilistic Programming Language for Program Induction
Aug 15, 2016We study machine learning formulations of inductive program synthesis; given input-output examples, we try to synthesize source code that maps inputs to corresponding outputs. Our aims are to develop new machine learning approaches based on neural networks and graphical models, and to understand the capabilities of machine learning techniques relative to traditional alternatives, such as those based on constraint solving from the programming languages community. Our key contribution is the proposal of TerpreT, a domain-specific language for expressing program synthesis problems. TerpreT is similar to a probabilistic programming language: a model is composed of a specification of a program representation (declarations of random variables) and an interpreter describing how programs map inputs to outputs (a model connecting unknowns to observations). The inference task is to observe a set of input-output examples and infer the underlying program. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing like-to-like comparisons between different approaches to inference. From a single TerpreT specification we automatically perform inference using four different back-ends. These are based on gradient descent, linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. We illustrate the value of TerpreT by developing several interpreter models and performing an empirical comparison between alternative inference algorithms. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. We conclude with suggestions for the machine learning community to make progress on program synthesis.