 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiBERT -- Classifying Online Conversations Messages with BERT as a Feature
Sep 09, 2024Recent developments in online communication and their usage in everyday life have caused an explosion in the amount of a new genre of text data, short text. Thus, the need to classify this type of text based on its content has a significant implication in many areas. Online debates are no exception, once these provide access to information about opinions, positions and preferences of its users. This paper aims to use data obtained from online social conversations in Portuguese schools (short text) to observe behavioural trends and to see if students remain engaged in the discussion when stimulated. This project used the state of the art (SoA) Machine Learning (ML) algorithms and methods, through BERT based models to classify if utterances are in or out of the debate subject. Using SBERT embeddings as a feature, with supervised learning, the proposed model achieved results above 0.95 average accuracy for classifying online messages. Such improvements can help social scientists better understand human communication, behaviour, discussion and persuasion.
PTPARL-D: Annotated Corpus of 44 years of Portuguese Parliament debates
Apr 26, 2020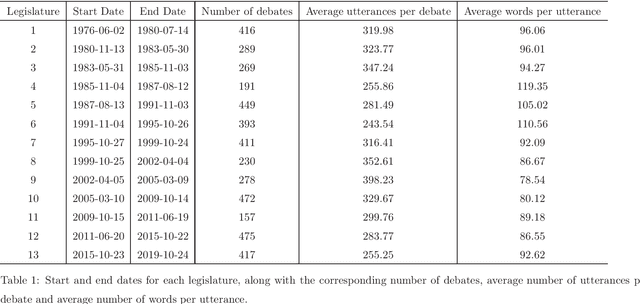
In a representative democracy, some decide in the name of the rest, and these elected officials are commonly gathered in public assemblies, such as parliaments, where they discuss policies, legislate, and vote on fundamental initiatives. A core aspect of such democratic processes are the plenary debates, where important public discussions take place. Many parliaments around the world are increasingly keeping the transcripts of such debates, and other parliamentary data, in digital formats accessible to the public, increasing transparency and accountability. Furthermore, some parliaments are bringing old paper transcripts to semi-structured digital formats. However, these records are often only provided as raw text or even as images, with little to no annotation, and inconsistent formats, making them difficult to analyze and study, reducing both transparency and public reach. Here, we present PTPARL-D, an annotated corpus of debates in the Portuguese Parliament, from 1976 to 2019, covering the entire period of Portuguese democracy.
Schema Redescription in Cellular Automata: Revisiting Emergence in Complex Systems
Feb 09, 2011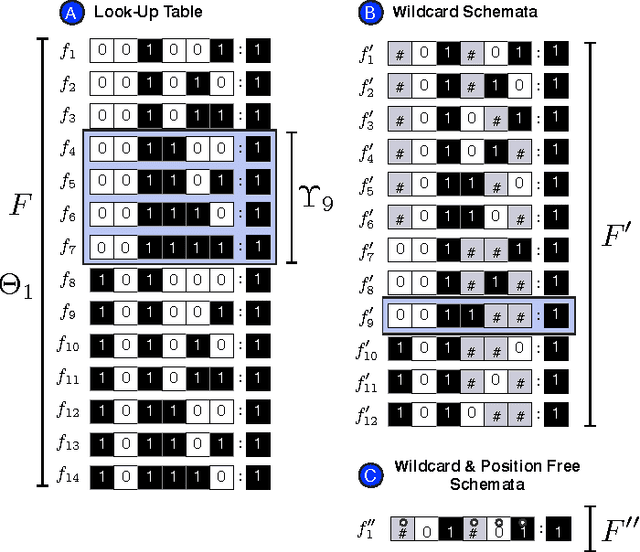

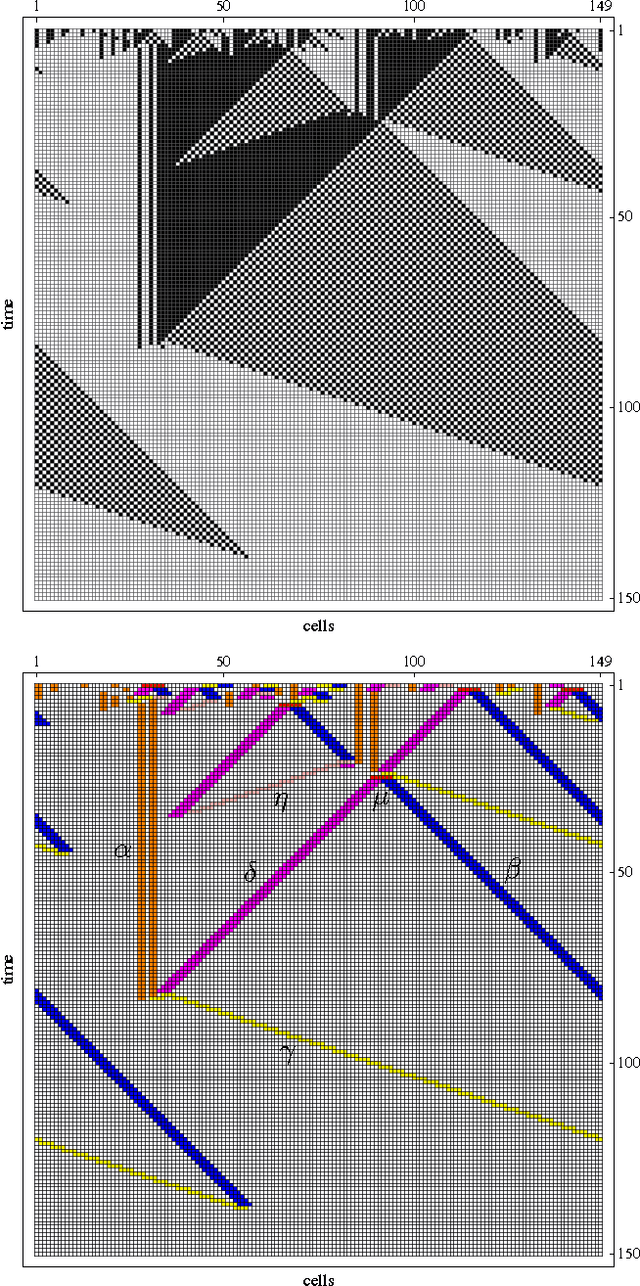
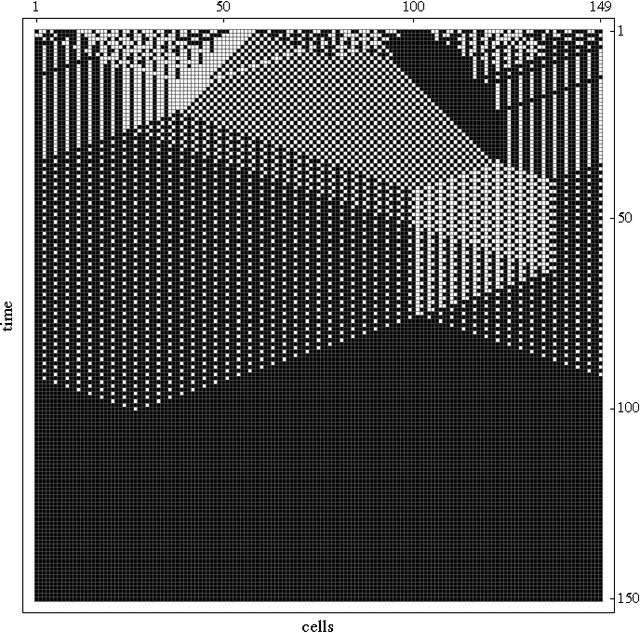
We present a method to eliminate redundancy in the transition tables of Boolean automata: schema redescription with two symbols. One symbol is used to capture redundancy of individual input variables, and another to capture permutability in sets of input variables: fully characterizing the canalization present in Boolean functions. Two-symbol schemata explain aspects of the behaviour of automata networks that the characterization of their emergent patterns does not capture. We use our method to compare two well-known cellular automata for the density classification task: the human engineered CA GKL, and another obtained via genetic programming (GP). We show that despite having very different collective behaviour, these rules are very similar. Indeed, GKL is a special case of GP. Therefore, we demonstrate that it is more feasible to compare cellular automata via schema redescriptions of their rules, than by looking at their emergent behaviour, leading us to question the tendency in complexity research to pay much more attention to emergent patterns than to local interactions.
* paper submitted to the 2011 IEEE Symposium on Artificial Life