 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Gatekeeping: An Audit of Search Engine Results shows tailoring of queries on the Israel-Palestine Conflict
Feb 07, 2025



Search engines, often viewed as reliable gateways to information, tailor search results using customization algorithms based on user preferences, location, and more. While this can be useful for routine queries, it raises concerns when the topics are sensitive or contentious, possibly limiting exposure to diverse viewpoints and increasing polarization. To examine the extent of this tailoring, we focused on the Israel-Palestine conflict and developed a privacy-protecting tool to audit the behavior of three search engines: DuckDuckGo, Google and Yahoo. Our study focused on two main questions: (1) How do search results for the same query about the conflict vary among different users? and (2) Are these results influenced by the user's location and browsing history? Our findings revealed significant customization based on location and browsing preferences, unlike previous studies that found only mild personalization for general topics. Moreover, queries related to the conflict were more customized than unrelated queries, and the results were not neutral concerning the conflict's portrayal.
Learning from pandemics: using extraordinary events can improve disease now-casting models
Jan 17, 2021Online searches have been used to study different health-related behaviours, including monitoring disease outbreaks. An obvious caveat is that several reasons can motivate individuals to seek online information and models that are blind to people's motivations are of limited use and can even mislead. This is particularly true during extraordinary public health crisis, such as the ongoing pandemic, when fear, curiosity and many other reasons can lead individuals to search for health-related information, masking the disease-driven searches. However, health crisis can also offer an opportunity to disentangle between different drivers and learn about human behavior. Here, we focus on the two pandemics of the 21st century (2009-H1N1 flu and Covid-19) and propose a methodology to discriminate between search patterns linked to general information seeking (media driven) and search patterns possibly more associated with actual infection (disease driven). We show that by learning from such pandemic periods, with high anxiety and media hype, it is possible to select online searches and improve model performance both in pandemic and seasonal settings. Moreover, and despite the common claim that more data is always better, our results indicate that lower volume of the right data can be better than including large volumes of apparently similar data, especially in the long run. Our work provides a general framework that can be applied beyond specific events and diseases, and argues that algorithms can be improved simply by using less (better) data. This has important consequences, for example, to solve the accuracy-explainability trade-off in machine-learning.
PTPARL-D: Annotated Corpus of 44 years of Portuguese Parliament debates
Apr 26, 2020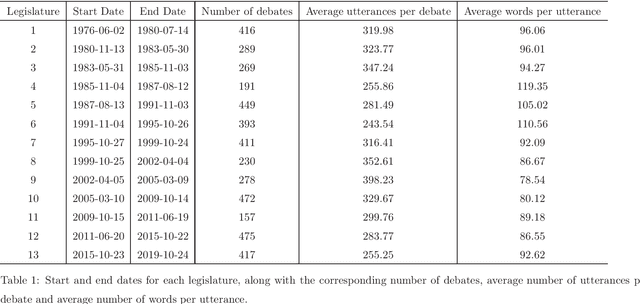
In a representative democracy, some decide in the name of the rest, and these elected officials are commonly gathered in public assemblies, such as parliaments, where they discuss policies, legislate, and vote on fundamental initiatives. A core aspect of such democratic processes are the plenary debates, where important public discussions take place. Many parliaments around the world are increasingly keeping the transcripts of such debates, and other parliamentary data, in digital formats accessible to the public, increasing transparency and accountability. Furthermore, some parliaments are bringing old paper transcripts to semi-structured digital formats. However, these records are often only provided as raw text or even as images, with little to no annotation, and inconsistent formats, making them difficult to analyze and study, reducing both transparency and public reach. Here, we present PTPARL-D, an annotated corpus of debates in the Portuguese Parliament, from 1976 to 2019, covering the entire period of Portuguese democracy.