 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving the Kesten-Stigum bound in the non-uniform hypergraph stochastic block model
Apr 21, 2026We study the community detection problem in the non-uniform hypergraph stochastic block model (HSBM), where hyperedges of varying sizes coexist. This setting captures higher-order and multi-view interactions and raises a fundamental question: can multiple uniform hypergraph layers below the detection threshold be combined to enable weak recovery? We answer this question by establishing a Kesten--Stigum-type bound for weak recovery in a general class of non-uniform HSBMs with $r$ blocks, generated according to multiple symmetric probability tensors. In the case $r=2$, we show that weak recovery is possible whenever the sum of the signal-to-noise ratios across all uniform hypergraph layers exceeds one, thereby confirming the positive part of a conjecture in (Chodrow et al., 2023). Moreover, we provide a polynomial-time spectral algorithm that achieves this threshold via an optimally weighted non-backtracking operator. For the unweighted non-backtracking matrix, our spectral method attains a different algorithmic threshold, also conjectured in (Chodrow et al., 2023). Our approach develops a spectral theory for weighted non-backtracking operators on non-uniform hypergraphs, including a precise characterization of outlier eigenvalues and eigenvector overlaps. We introduce a novel Ihara--Bass formula tailored to weighted non-uniform hypergraphs, which yields an efficient low-dimensional representation and leads to a provable spectral reconstruction algorithm. Taken together, these results provide a principled and computationally efficient approach to clustering in non-uniform hypergraphs, and highlight the role of optimal weighting in aggregating heterogeneous higher-order interactions.
Tight Kernel Query Complexity of Kernel Ridge Regression and Kernel $k$-means Clustering
May 15, 2019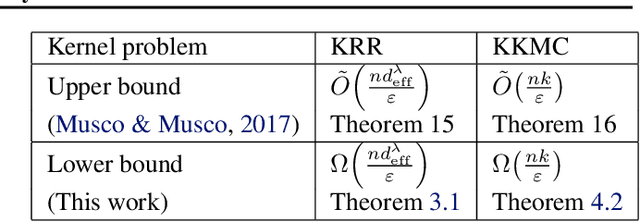
We present tight lower bounds on the number of kernel evaluations required to approximately solve kernel ridge regression (KRR) and kernel $k$-means clustering (KKMC) on $n$ input points. For KRR, our bound for relative error approximation to the minimizer of the objective function is $\Omega(nd_{\mathrm{eff}}^\lambda/\varepsilon)$ where $d_{\mathrm{eff}}^\lambda$ is the effective statistical dimension, which is tight up to a $\log(d_{\mathrm{eff}}^\lambda/\varepsilon)$ factor. For KKMC, our bound for finding a $k$-clustering achieving a relative error approximation of the objective function is $\Omega(nk/\varepsilon)$, which is tight up to a $\log(k/\varepsilon)$ factor. Our KRR result resolves a variant of an open question of El Alaoui and Mahoney, asking whether the effective statistical dimension is a lower bound on the sampling complexity or not. Furthermore, for the important practical case when the input is a mixture of Gaussians, we provide a KKMC algorithm which bypasses the above lower bound.