 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurpassing state of the art on AMD area estimation from RGB fundus images through careful selection of U-Net architectures and loss functions for class imbalance
Oct 30, 2025Age-related macular degeneration (AMD) is one of the leading causes of irreversible vision impairment in people over the age of 60. This research focuses on semantic segmentation for AMD lesion detection in RGB fundus images, a non-invasive and cost-effective imaging technique. The results of the ADAM challenge - the most comprehensive AMD detection from RGB fundus images research competition and open dataset to date - serve as a benchmark for our evaluation. Taking the U-Net connectivity as a base of our framework, we evaluate and compare several approaches to improve the segmentation model's architecture and training pipeline, including pre-processing techniques, encoder (backbone) deep network types of varying complexity, and specialized loss functions to mitigate class imbalances on image and pixel levels. The main outcome of this research is the final configuration of the AMD detection framework, which outperforms all the prior ADAM challenge submissions on the multi-class segmentation of different AMD lesion types in non-invasive RGB fundus images. The source code used to conduct the experiments presented in this paper is made freely available.
Extracting Sentence Embeddings from Pretrained Transformer Models
Aug 15, 2024



Background/introduction: Pre-trained transformer models shine in many natural language processing tasks and therefore are expected to bear the representation of the input sentence or text meaning. These sentence-level embeddings are also important in retrieval-augmented generation. But do commonly used plain averaging or prompt templates surface it enough? Methods: Given 110M parameters BERT's hidden representations from multiple layers and multiple tokens we tried various ways to extract optimal sentence representations. We tested various token aggregation and representation post-processing techniques. We also tested multiple ways of using a general Wikitext dataset to complement BERTs sentence representations. All methods were tested on 8 Semantic Textual Similarity (STS), 6 short text clustering, and 12 classification tasks. We also evaluated our representation-shaping techniques on other static models, including random token representations. Results: Proposed representation extraction methods improved the performance on STS and clustering tasks for all models considered. Very high improvements for static token-based models, especially random embeddings for STS tasks almost reach the performance of BERT-derived representations. Conclusions: Our work shows that for multiple tasks simple baselines with representation shaping techniques reach or even outperform more complex BERT-based models or are able to contribute to their performance.
Sentiment Analysis of Lithuanian Online Reviews Using Large Language Models
Jul 29, 2024



Sentiment analysis is a widely researched area within Natural Language Processing (NLP), attracting significant interest due to the advent of automated solutions. Despite this, the task remains challenging because of the inherent complexity of languages and the subjective nature of sentiments. It is even more challenging for less-studied and less-resourced languages such as Lithuanian. Our review of existing Lithuanian NLP research reveals that traditional machine learning methods and classification algorithms have limited effectiveness for the task. In this work, we address sentiment analysis of Lithuanian five-star-based online reviews from multiple domains that we collect and clean. We apply transformer models to this task for the first time, exploring the capabilities of pre-trained multilingual Large Language Models (LLMs), specifically focusing on fine-tuning BERT and T5 models. Given the inherent difficulty of the task, the fine-tuned models perform quite well, especially when the sentiments themselves are less ambiguous: 80.74% and 89.61% testing recognition accuracy of the most popular one- and five-star reviews respectively. They significantly outperform current commercial state-of-the-art general-purpose LLM GPT-4. We openly share our fine-tuned LLMs online.
Inference acceleration for large language models using "stairs" assisted greedy generation
Jul 29, 2024Large Language Models (LLMs) with billions of parameters are known for their impressive predicting capabilities but require lots of resources to run. With their massive rise in popularity, even a small reduction in required resources could have an impact on environment. On the other hand, smaller models require fewer resources but may sacrifice accuracy. In this work, we are proposing an implementation of ``stairs'' assisted greedy generation. It is a modified assisted generation methodology that makes use of a smaller model's fast generation, large model's batch prediction, and "stairs" validation in order to achieve a speed up in prediction generation. Results show between 9.58 and 17.24 percent inference time reduction compared to a stand-alone large LLM prediction in a text generation task without a loss in accuracy.
Optimizing Large Language Models for OpenAPI Code Completion
May 24, 2024



Recent advancements in Large Language Models (LLMs) and their utilization in code generation tasks have significantly reshaped the field of software development. Despite the remarkable efficacy of code completion solutions in mainstream programming languages, their performance lags when applied to less ubiquitous formats such as OpenAPI definitions. This study evaluates the OpenAPI completion performance of GitHub Copilot, a prevalent commercial code completion tool, and proposes a set of task-specific optimizations leveraging Meta's open-source model Code Llama. A semantics-aware OpenAPI completion benchmark proposed in this research is used to perform a series of experiments through which the impact of various prompt-engineering and fine-tuning techniques on the Code Llama model's performance is analyzed. The fine-tuned Code Llama model reaches a peak correctness improvement of 55.2% over GitHub Copilot despite utilizing 25 times fewer parameters than the commercial solution's underlying Codex model. Additionally, this research proposes an enhancement to a widely used code infilling training technique, addressing the issue of underperformance when the model is prompted with context sizes smaller than those used during training.
Time-Adaptive Recurrent Neural Networks
Apr 11, 2022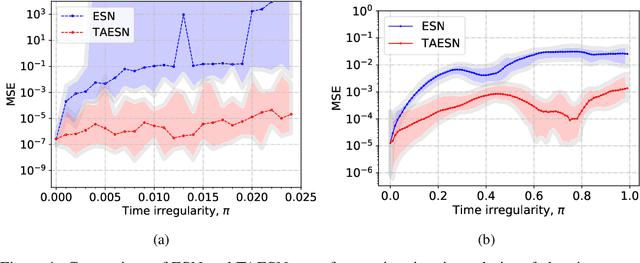
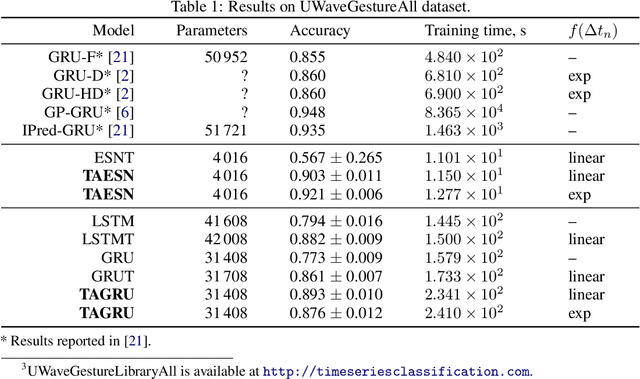
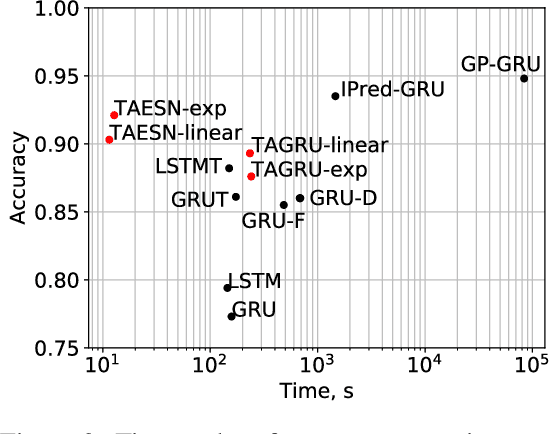
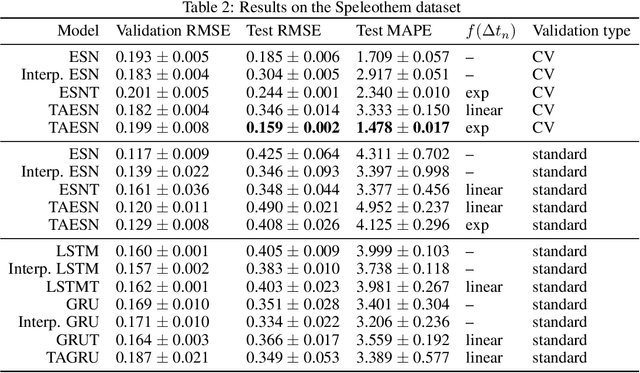
Data are often sampled irregularly in time. Dealing with this using Recurrent Neural Networks (RNNs) traditionally involved ignoring the fact, feeding the time differences as additional inputs, or resampling the data. All these methods have their shortcomings. We propose an elegant alternative approach where instead the RNN is in effect resampled in time to match the time of the data. We use Echo State Network (ESN) and Gated Recurrent Unit (GRU) as the basis for our solution. Such RNNs can be seen as discretizations of continuous-time dynamical systems, which gives a solid theoretical ground for our approach. Similar recent observations have been made in feed-forward neural networks as neural ordinary differential equations. Our Time-Adaptive ESN (TAESN) and GRU (TAGRU) models allow for a direct model time setting and require no additional training, parameter tuning, or computation compared to the regular counterparts, thus retaining their original efficiency. We confirm empirically that our models can effectively compensate for the time-non-uniformity of the data and demonstrate that they compare favorably to data resampling, classical RNN methods, and alternative RNN models proposed to deal with time irregularities on several real-world nonuniform-time datasets.
Towards Lithuanian grammatical error correction
Mar 18, 2022
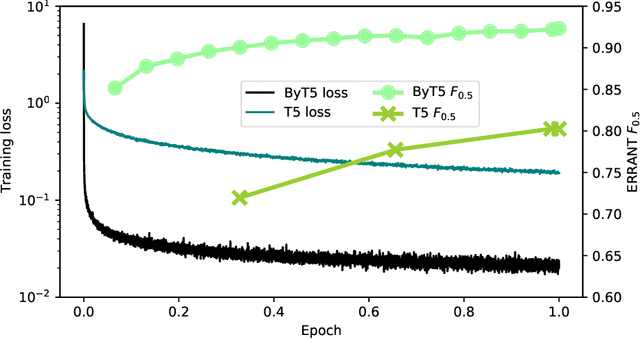
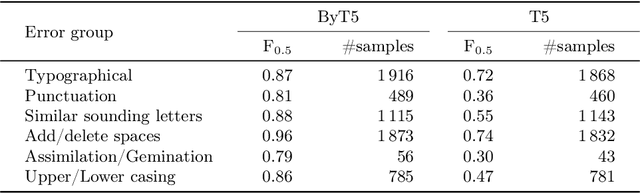
Everyone wants to write beautiful and correct text, yet the lack of language skills, experience, or hasty typing can result in errors. By employing the recent advances in transformer architectures, we construct a grammatical error correction model for Lithuanian, the language rich in archaic features. We compare subword and byte-level approaches and share our best trained model, achieving F$_{0.5}$=0.92, and accompanying code, in an online open-source repository.
Correcting diacritics and typos with ByT5 transformer model
Jan 31, 2022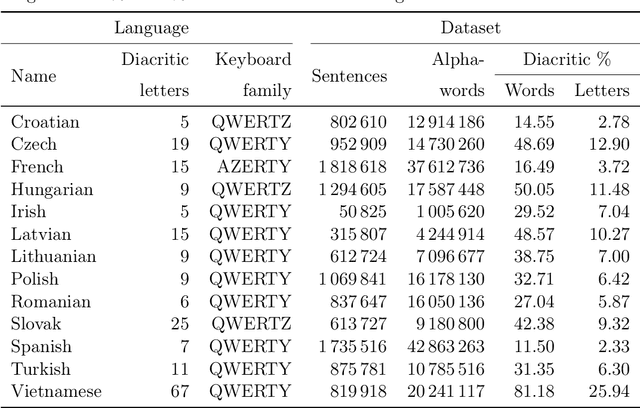
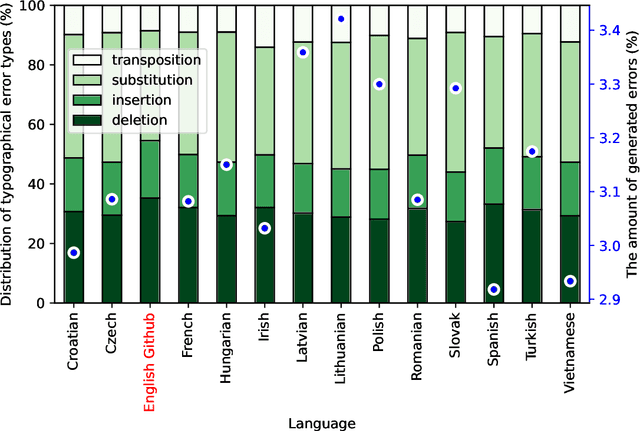

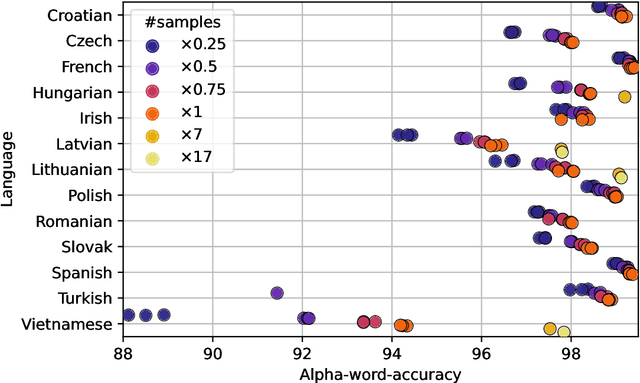
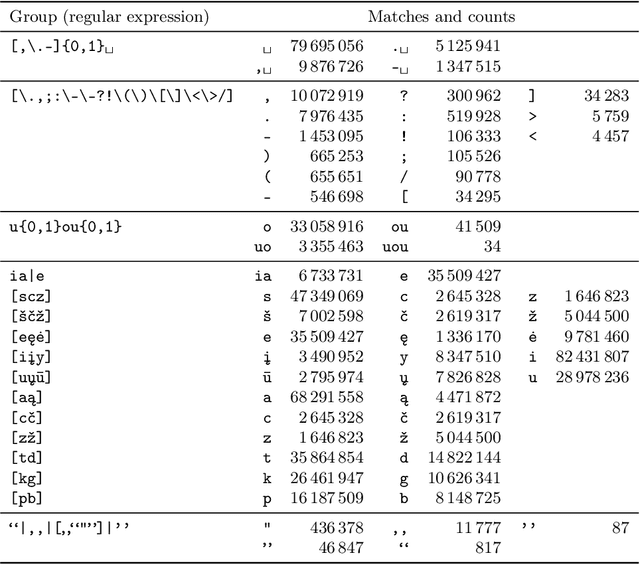
Due to the fast pace of life and online communications, the prevalence of English and the QWERTY keyboard, people tend to forgo using diacritics, make typographical errors (typos) when typing. Restoring diacritics and correcting spelling is important for proper language use and disambiguation of texts for both humans and downstream algorithms. However, both of these problems are typically addressed separately, i.e., state-of-the-art diacritics restoration methods do not tolerate other typos. In this work, we tackle both problems at once by employing newly-developed ByT5 byte-level transformer models. Our simultaneous diacritics restoration and typos correction approach demonstrates near state-of-the-art performance in 13 languages, reaching >96% of the alpha-word accuracy. We also perform diacritics restoration alone on 12 benchmark datasets with the additional one for the Lithuanian language. The experimental investigation proves that our approach is able to achieve comparable results (>98%) to previously reported despite being trained on fewer data. Our approach is also able to restore diacritics in words not seen during training with >76% accuracy. We also show the accuracies to further improve with longer training. All this shows a great real-world application potential of our suggested methods to more data, languages, and error classes.
Automated age-related macular degeneration area estimation -- first results
Jul 05, 2021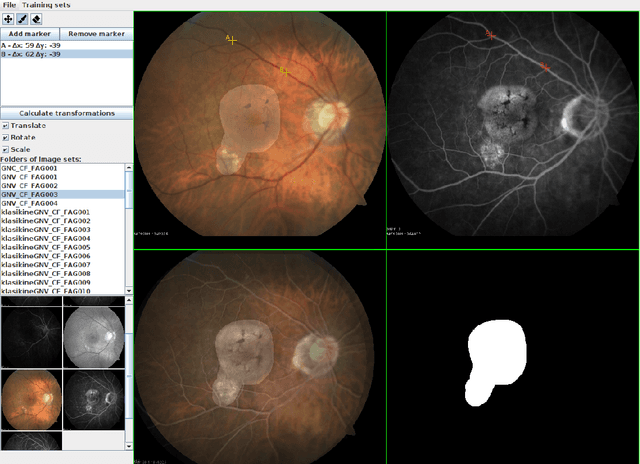
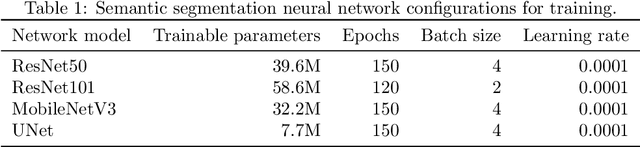
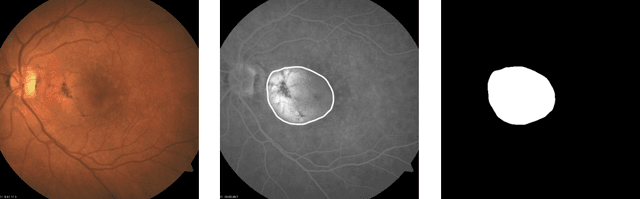

This work aims to research an automatic method for detecting Age-related Macular Degeneration (AMD) lesions in RGB eye fundus images. For this, we align invasively obtained eye fundus contrast images (the "golden standard" diagnostic) to the RGB ones and use them to hand-annotate the lesions. This is done using our custom-made tool. Using the data, we train and test five different convolutional neural networks: a custom one to classify healthy and AMD-affected eye fundi, and four well-known networks: ResNet50, ResNet101, MobileNetV3, and UNet to segment (localize) the AMD lesions in the affected eye fundus images. We achieve 93.55% accuracy or 69.71% Dice index as the preliminary best results in segmentation with MobileNetV3.
Generating abstractive summaries of Lithuanian news articles using a transformer model
Apr 23, 2021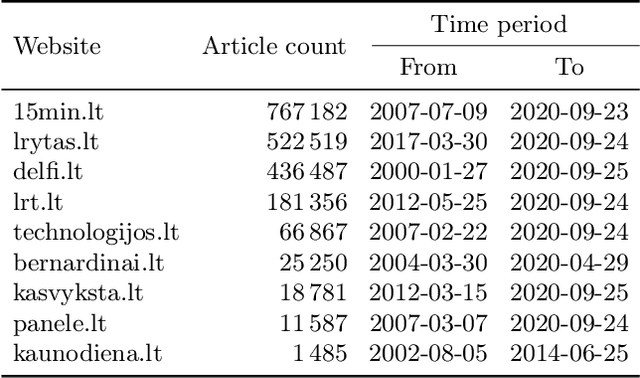
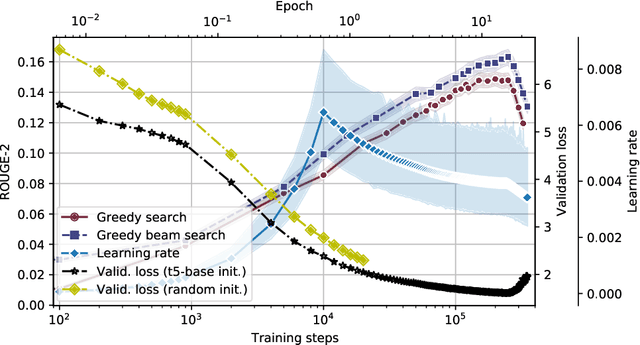
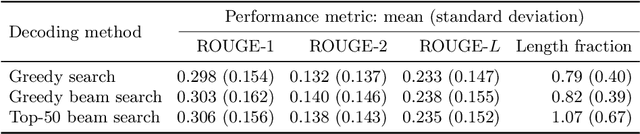
In this work, we train the first monolingual Lithuanian transformer model on a relatively large corpus of Lithuanian news articles and compare various output decoding algorithms for abstractive news summarization. Generated summaries are coherent and look impressive at the first glance. However, some of them contain misleading information that is not so easy to spot. We describe all the technical details and share our trained model and accompanying code in an online open-source repository, as well as some characteristic samples of the generated summaries.