 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can embedding models bind concepts?
May 29, 2026Humans easily determine which color belongs to which shape in multi-object scenes, an ability known as concept binding. Vision-language embedding models such as CLIP struggle with binding: they recognize individual concepts but fail to represent which concepts form which objects. Although CLIP behaves like a bag-of-concepts model in cross-modal retrieval, object information is recoverable from its image and text embeddings separately. We study this tension through the binding function, which maps concepts to scene embeddings. We find that scene embeddings decompose additively into object representations, explaining why uni-modal probes can recover object information. However, CLIP's binding function is high-complexity, which likely prevents the image and text encoders from learning a shared binding mechanism that generalizes to unseen concept combinations. We then ask whether this limitation is fundamental. We show that it is not. In controlled transformer models trained from scratch, binding generalization emerges with sufficient data coverage. These models learn low-complexity binding functions characterized by multiplicative interactions between concepts, enabling systematic generalization. Code is publicly available at https://github.com/oshapio/binding-concepts-complexity.
MEME: Multi-entity & Evolving Memory Evaluation
May 12, 2026LLM-based agents increasingly operate in persistent environments where they must store, update, and reason over information across many sessions. While prior benchmarks evaluate only single-entity updates, MEME defines six tasks spanning the full space defined by the multi-entity and evolving axes, including three not scored by prior work: Cascade and Absence (dependency reasoning) and Deletion (post-removal state). Evaluating six memory systems spanning three memory paradigms on 100 controlled episodes, we find that all systems collapse on dependency reasoning under the default configuration (Cascade: 3%, Absence: 1% in average accuracy) despite adequate static retrieval performance. Prompt optimization, deeper retrieval, reduced filler noise, and most stronger LLMs fail to close this gap. Only a file-based agent paired with Claude Opus 4.7 as its internal LLM partially closes the gap, but at ~70x the baseline cost, indicating closure currently depends on configurations that are not practical at scale. Code and data are available on the project page: https://seokwonjung-jay.github.io/meme-eval/.
Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
Feb 27, 2026Compositional generalization, the ability to recognize familiar parts in novel contexts, is a defining property of intelligent systems. Although modern models are trained on massive datasets, they still cover only a tiny fraction of the combinatorial space of possible inputs, raising the question of what structure representations must have to support generalization to unseen combinations. We formalize three desiderata for compositional generalization under standard training (divisibility, transferability, stability) and show they impose necessary geometric constraints: representations must decompose linearly into per-concept components, and these components must be orthogonal across concepts. This provides theoretical grounding for the Linear Representation Hypothesis: the linear structure widely observed in neural representations is a necessary consequence of compositional generalization. We further derive dimension bounds linking the number of composable concepts to the embedding geometry. Empirically, we evaluate these predictions across modern vision models (CLIP, SigLIP, DINO) and find that representations exhibit partial linear factorization with low-rank, near-orthogonal per-concept factors, and that the degree of this structure correlates with compositional generalization on unseen combinations. As models continue to scale, these conditions predict the representational geometry they may converge to. Code is available at https://github.com/oshapio/necessary-compositionality.
Half-Truths Break Similarity-Based Retrieval
Feb 27, 2026When a text description is extended with an additional detail, image-text similarity should drop if that detail is wrong. We show that CLIP-style dual encoders often violate this intuition: appending a plausible but incorrect object or relation to an otherwise correct description can increase the similarity score. We call such cases half-truths. On COCO, CLIP prefers the correct shorter description only 40.6% of the time, and performance drops to 32.9% when the added detail is a relation. We trace this vulnerability to weak supervision on caption parts: contrastive training aligns full sentences but does not explicitly enforce that individual entities and relations are grounded. We propose CS-CLIP (Component-Supervised CLIP), which decomposes captions into entity and relation units, constructs a minimally edited foil for each unit, and fine-tunes the model to score the correct unit above its foil while preserving standard dual-encoder inference. CS-CLIP raises half-truth accuracy to 69.3% and improves average performance on established compositional benchmarks by 5.7 points, suggesting that reducing half-truth errors aligns with broader gains in compositional understanding. Code is publicly available at: https://github.com/kargibora/CS-CLIP
Does Data Scaling Lead to Visual Compositional Generalization?
Jul 09, 2025Compositional understanding is crucial for human intelligence, yet it remains unclear whether contemporary vision models exhibit it. The dominant machine learning paradigm is built on the premise that scaling data and model sizes will improve out-of-distribution performance, including compositional generalization. We test this premise through controlled experiments that systematically vary data scale, concept diversity, and combination coverage. We find that compositional generalization is driven by data diversity, not mere data scale. Increased combinatorial coverage forces models to discover a linearly factored representational structure, where concepts decompose into additive components. We prove this structure is key to efficiency, enabling perfect generalization from few observed combinations. Evaluating pretrained models (DINO, CLIP), we find above-random yet imperfect performance, suggesting partial presence of this structure. Our work motivates stronger emphasis on constructing diverse datasets for compositional generalization, and considering the importance of representational structure that enables efficient compositional learning. Code available at https://github.com/oshapio/visual-compositional-generalization.
Diffusion Classifiers Understand Compositionality, but Conditions Apply
May 23, 2025Understanding visual scenes is fundamental to human intelligence. While discriminative models have significantly advanced computer vision, they often struggle with compositional understanding. In contrast, recent generative text-to-image diffusion models excel at synthesizing complex scenes, suggesting inherent compositional capabilities. Building on this, zero-shot diffusion classifiers have been proposed to repurpose diffusion models for discriminative tasks. While prior work offered promising results in discriminative compositional scenarios, these results remain preliminary due to a small number of benchmarks and a relatively shallow analysis of conditions under which the models succeed. To address this, we present a comprehensive study of the discriminative capabilities of diffusion classifiers on a wide range of compositional tasks. Specifically, our study covers three diffusion models (SD 1.5, 2.0, and, for the first time, 3-m) spanning 10 datasets and over 30 tasks. Further, we shed light on the role that target dataset domains play in respective performance; to isolate the domain effects, we introduce a new diagnostic benchmark Self-Bench comprised of images created by diffusion models themselves. Finally, we explore the importance of timestep weighting and uncover a relationship between domain gap and timestep sensitivity, particularly for SD3-m. To sum up, diffusion classifiers understand compositionality, but conditions apply! Code and dataset are available at https://github.com/eugene6923/Diffusion-Classifiers-Compositionality.
Intermediate Layer Classifiers for OOD generalization
Apr 07, 2025



Deep classifiers are known to be sensitive to data distribution shifts, primarily due to their reliance on spurious correlations in training data. It has been suggested that these classifiers can still find useful features in the network's last layer that hold up under such shifts. In this work, we question the use of last-layer representations for out-of-distribution (OOD) generalisation and explore the utility of intermediate layers. To this end, we introduce \textit{Intermediate Layer Classifiers} (ILCs). We discover that intermediate layer representations frequently offer substantially better generalisation than those from the penultimate layer. In many cases, zero-shot OOD generalisation using earlier-layer representations approaches the few-shot performance of retraining on penultimate layer representations. This is confirmed across multiple datasets, architectures, and types of distribution shifts. Our analysis suggests that intermediate layers are less sensitive to distribution shifts compared to the penultimate layer. These findings highlight the importance of understanding how information is distributed across network layers and its role in OOD generalisation, while also pointing to the limits of penultimate layer representation utility. Code is available at https://github.com/oshapio/intermediate-layer-generalization
CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally
Feb 05, 2025



CLIP (Contrastive Language-Image Pretraining) has become a popular choice for various downstream tasks. However, recent studies have questioned its ability to represent compositional concepts effectively. These works suggest that CLIP often acts like a bag-of-words (BoW) model, interpreting images and text as sets of individual concepts without grasping the structural relationships. In particular, CLIP struggles to correctly bind attributes to their corresponding objects when multiple objects are present in an image or text. In this work, we investigate why CLIP exhibits this BoW-like behavior. We find that the correct attribute-object binding information is already present in individual text and image modalities. Instead, the issue lies in the cross-modal alignment, which relies on cosine similarity. To address this, we propose Linear Attribute Binding CLIP or LABCLIP. It applies a linear transformation to text embeddings before computing cosine similarity. This approach significantly improves CLIP's ability to bind attributes to correct objects, thereby enhancing its compositional understanding.
Time-Adaptive Recurrent Neural Networks
Apr 11, 2022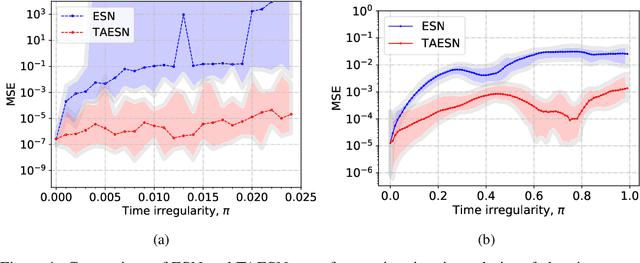
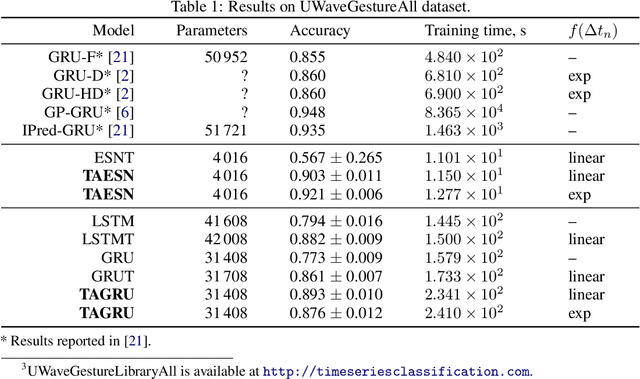
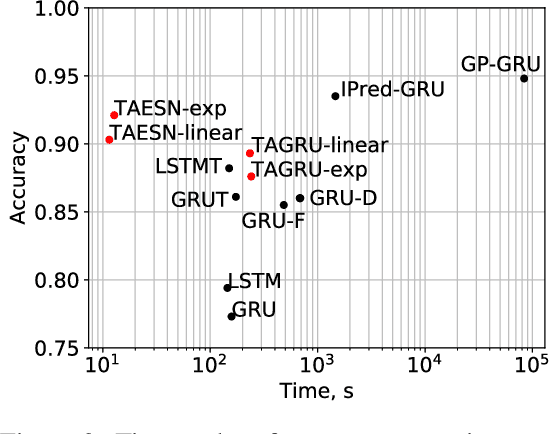
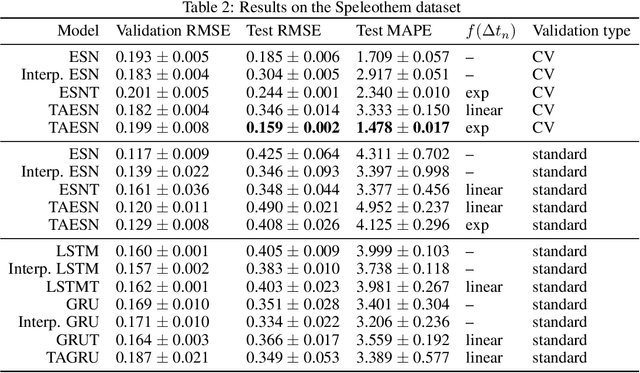
Data are often sampled irregularly in time. Dealing with this using Recurrent Neural Networks (RNNs) traditionally involved ignoring the fact, feeding the time differences as additional inputs, or resampling the data. All these methods have their shortcomings. We propose an elegant alternative approach where instead the RNN is in effect resampled in time to match the time of the data. We use Echo State Network (ESN) and Gated Recurrent Unit (GRU) as the basis for our solution. Such RNNs can be seen as discretizations of continuous-time dynamical systems, which gives a solid theoretical ground for our approach. Similar recent observations have been made in feed-forward neural networks as neural ordinary differential equations. Our Time-Adaptive ESN (TAESN) and GRU (TAGRU) models allow for a direct model time setting and require no additional training, parameter tuning, or computation compared to the regular counterparts, thus retaining their original efficiency. We confirm empirically that our models can effectively compensate for the time-non-uniformity of the data and demonstrate that they compare favorably to data resampling, classical RNN methods, and alternative RNN models proposed to deal with time irregularities on several real-world nonuniform-time datasets.
Efficient implementations of echo state network cross-validation
Jun 19, 2020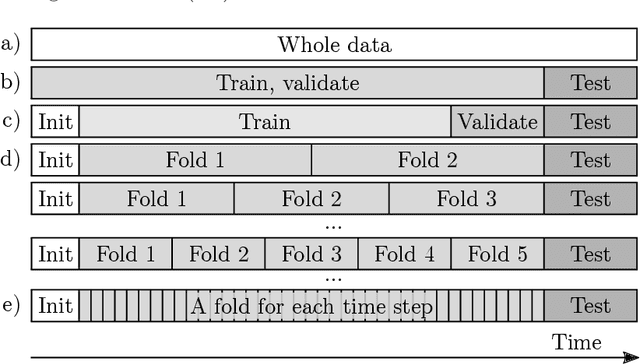
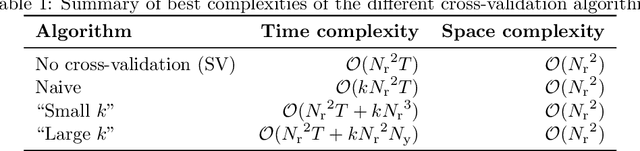
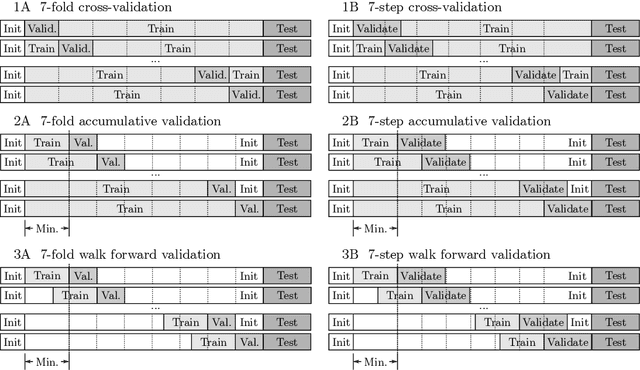

Background/introduction: Cross-validation is still uncommon in time series modeling. Echo State Networks (ESNs), as a prime example of Reservoir Computing (RC) models, are known for their fast and precise one-shot learning, that often benefit from good hyper-parameter tuning. This makes them ideal to change the status quo. Methods: We suggest several schemes for cross-validating ESNs and introduce an efficient algorithm for implementing them. This algorithm is presented as two levels of optimizations of doing $k$-fold cross-validation. Training an RC model typically consists of two stages: (i) running the reservoir with the data and (ii) computing the optimal readouts. The first level of our proposed optimization addresses the most computationally expensive part (i) and makes it remain constant irrespective of $k$. It dramatically reduces reservoir computations in any type of RC system and is enough if $k$ is small. The second level of optimization also makes the (ii) part remain constant irrespective of large $k$, as long as the dimension of the output is low. We discuss when the proposed validation schemes for ESNs could be beneficial, three options for producing the final model and empirically investigate them on six different real-world datasets, as well as do empirical computation time experiments. We provide the code in an online repository. Results: Proposed cross-validation schemes give better and more stable test performance in all the six different real-world datasets, three task types. Empirical run times confirm our complexity analysis. Conclusions: In most situations $k$-fold cross-validation of ESNs and many other RC models can be done for virtually the same time complexity as a simple single-split validation. Space complexity can also remain the same in all the cases. This enables cross-validation to become a standard practice in reservoir computing.