 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecting Trust in Artificial Epistemic Agents
Mar 03, 2026Large language models increasingly function as epistemic agents -- entities that can 1) autonomously pursue epistemic goals and 2) actively shape our shared knowledge environment. They curate the information we receive, often supplanting traditional search-based methods, and are frequently used to generate both personal and deeply specialized advice. How they perform these functions, including whether they are reliable and properly calibrated to both individual and collective epistemic norms, is therefore highly consequential for the choices we make. We argue that the potential impact of epistemic AI agents on practices of knowledge creation, curation and synthesis, particularly in the context of complex multi-agent interactions, creates new informational interdependencies that necessitate a fundamental shift in evaluation and governance of AI. While a well-calibrated ecosystem could augment human judgment and collective decision-making, poorly aligned agents risk causing cognitive deskilling and epistemic drift, making the calibration of these models to human norms a high-stakes necessity. To ensure a beneficial human-AI knowledge ecosystem, we propose a framework centered on building and cultivating the trustworthiness of epistemic AI agents; aligning AI these agents with human epistemic goals; and reinforcing the surrounding socio-epistemic infrastructure. In this context, trustworthy AI agents must demonstrate epistemic competence, robust falsifiability, and epistemically virtuous behaviors, supported by technical provenance systems and "knowledge sanctuaries" designed to protect human resilience. This normative roadmap provides a path toward ensuring that future AI systems act as reliable partners in a robust and inclusive knowledge ecosystem.
Arbiters of Ambivalence: Challenges of Using LLMs in No-Consensus Tasks
May 28, 2025The increasing use of LLMs as substitutes for humans in ``aligning'' LLMs has raised questions about their ability to replicate human judgments and preferences, especially in ambivalent scenarios where humans disagree. This study examines the biases and limitations of LLMs in three roles: answer generator, judge, and debater. These roles loosely correspond to previously described alignment frameworks: preference alignment (judge) and scalable oversight (debater), with the answer generator reflecting the typical setting with user interactions. We develop a ``no-consensus'' benchmark by curating examples that encompass a variety of a priori ambivalent scenarios, each presenting two possible stances. Our results show that while LLMs can provide nuanced assessments when generating open-ended answers, they tend to take a stance on no-consensus topics when employed as judges or debaters. These findings underscore the necessity for more sophisticated methods for aligning LLMs without human oversight, highlighting that LLMs cannot fully capture human disagreement even on topics where humans themselves are divided.
SEAL: Systematic Error Analysis for Value ALignment
Aug 16, 2024



Reinforcement Learning from Human Feedback (RLHF) aims to align language models (LMs) with human values by training reward models (RMs) on binary preferences and using these RMs to fine-tune the base LMs. Despite its importance, the internal mechanisms of RLHF remain poorly understood. This paper introduces new metrics to evaluate the effectiveness of modeling and aligning human values, namely feature imprint, alignment resistance and alignment robustness. We categorize alignment datasets into target features (desired values) and spoiler features (undesired concepts). By regressing RM scores against these features, we quantify the extent to which RMs reward them - a metric we term feature imprint. We define alignment resistance as the proportion of the preference dataset where RMs fail to match human preferences, and we assess alignment robustness by analyzing RM responses to perturbed inputs. Our experiments, utilizing open-source components like the Anthropic/hh-rlhf preference dataset and OpenAssistant RMs, reveal significant imprints of target features and a notable sensitivity to spoiler features. We observed a 26% incidence of alignment resistance in portions of the dataset where LM-labelers disagreed with human preferences. Furthermore, we find that misalignment often arises from ambiguous entries within the alignment dataset. These findings underscore the importance of scrutinizing both RMs and alignment datasets for a deeper understanding of value alignment.
The Optimal Size of an Epistemic Congress
Jul 02, 2021
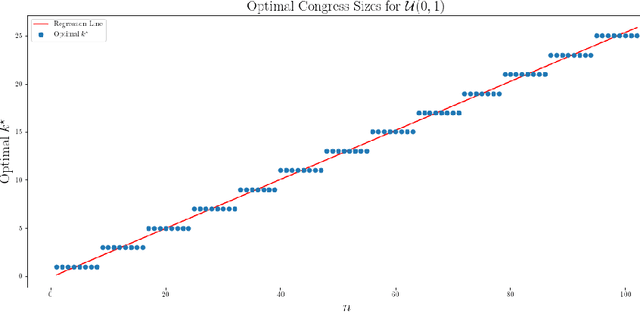
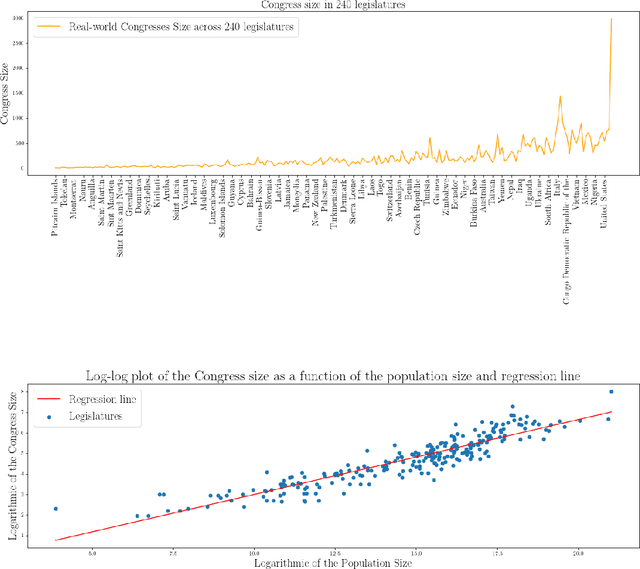
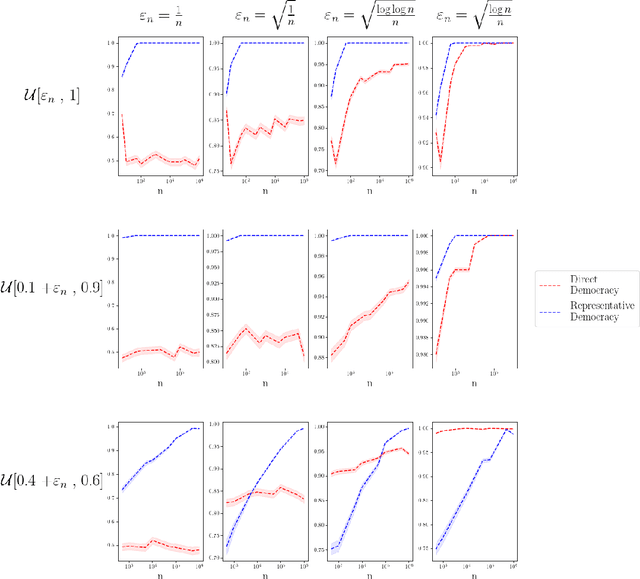
We analyze the optimal size of a congress in a representative democracy. We take an epistemic view where voters decide on a binary issue with one ground truth outcome, and each voter votes correctly according to their competence levels in $[0, 1]$. Assuming that we can sample the best experts to form an epistemic congress, we find that the optimal congress size should be linear in the population size. This result is striking because it holds even when allowing the top representatives to be accurate with arbitrarily high probabilities. We then analyze real world data, finding that the actual sizes of congresses are much smaller than the optimal size our theoretical results suggest. We conclude by analyzing under what conditions congresses of sub-optimal sizes would still outperform direct democracy, in which all voters vote.