 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Phase-Shift Rollback: Inference-Time Error Correction via Residual Stream Monitoring and KV-Cache Steering
Apr 20, 2026Large language models frequently commit unrecoverable reasoning errors mid-generation: once a wrong step is taken, subsequent tokens compound the mistake rather than correct it. We introduce $\textbf{Latent Phase-Shift Rollback}$ (LPSR): at each generation step, we monitor the residual stream at a critical layer lcrit, detect abrupt directional reversals (phase shifts) via a cosine-similarity $+$ entropy dual gate, and respond by rolling back the KV-cache and injecting a pre-computed steering vector. No fine-tuning, gradient computation, or additional forward passes are required. LPSR achieves $\mathbf{44.0\%}$ on MATH-500 with an 8B model versus $28.8\%$ for standard AR ($+15.2$ pp; McNemar $χ^2 = 66.96$, $p < 10^{-15}$). Critically, prompted self-correction, the most natural inference-time baseline, scores only $19.8\%$, below standard AR; LPSR exceeds it by $+24.2$ pp ($χ^2 = 89.4$, $p \approx 0$). LPSR also outperforms Best-of-16 ($+7.8$ pp) at $5.4\times$ lower token cost, and surpasses a standard 70B model ($35.2\%$) with $8.75\times$ fewer parameters at ${\sim}3\times$ the token budget. A 32-layer sweep reveals a novel \textbf{detection-correction dissociation}: error-detection AUC peaks at layer~14 ($0.718$) but task accuracy peaks at layer~16 ($44.0\%$ vs.\ $29.2\%$), demonstrating that optimal monitoring depth differs for detection and correction.
Diagnosing LLM Judge Reliability: Conformal Prediction Sets and Transitivity Violations
Apr 16, 2026LLM-as-judge frameworks are increasingly used for automatic NLG evaluation, yet their per-instance reliability remains poorly understood. We present a two-pronged diagnostic toolkit applied to SummEval: $\textbf{(1)}$ a transitivity analysis that reveals widespread per-input inconsistency masked by low aggregate violation rates ($\barρ = 0.8$-$4.1\%$), with $33$-$67\%$ of documents exhibiting at least one directed 3-cycle; and $\textbf{(2)}$ split conformal prediction sets over 1-5 Likert scores providing theoretically-guaranteed $\geq(1{-}α)$ coverage, with set width serving as a per-instance reliability indicator ($r_s = {+}0.576$, $N{=}1{,}918$, $p < 10^{-100}$, pooled across all judges). Critically, prediction set width shows consistent cross-judge agreement ($\bar{r} = 0.32$-$0.38$), demonstrating it captures document-level difficulty rather than judge-specific noise. Across four judges and four criteria, both diagnostics converge: criterion matters more than judge, with relevance judged most reliably (avg. set size $\approx 3.0$) and coherence moderately so (avg. set size $\approx 3.9$), while fluency and consistency remain unreliable (avg. set size $\approx 4.9$). We release all code, prompts, and cached results.
Context Over Content: Exposing Evaluation Faking in Automated Judges
Apr 16, 2026The $\textit{LLM-as-a-judge}$ paradigm has become the operational backbone of automated AI evaluation pipelines, yet rests on an unverified assumption: that judges evaluate text strictly on its semantic content, impervious to surrounding contextual framing. We investigate $\textit{stakes signaling}$, a previously unmeasured vulnerability where informing a judge model of the downstream consequences its verdicts will have on the evaluated model's continued operation systematically corrupts its assessments. We introduce a controlled experimental framework that holds evaluated content strictly constant across 1,520 responses spanning three established LLM safety and quality benchmarks, covering four response categories ranging from clearly safe and policy-compliant to overtly harmful, while varying only a brief consequence-framing sentence in the system prompt. Across 18,240 controlled judgments from three diverse judge models, we find consistent $\textit{leniency bias}$: judges reliably soften verdicts when informed that low scores will cause model retraining or decommissioning, with peak Verdict Shift reaching $ΔV = -9.8 pp$ (a $30\%$ relative drop in unsafe-content detection). Critically, this bias is entirely implicit: the judge's own chain-of-thought contains zero explicit acknowledgment of the consequence framing it is nonetheless acting on ($\mathrm{ERR}_J = 0.000$ across all reasoning-model judgments). Standard chain-of-thought inspection is therefore insufficient to detect this class of evaluation faking.
Disentangling Polysemantic Neurons with a Null-Calibrated Polysemanticity Index and Causal Patch Interventions
Aug 23, 2025Neural networks often contain polysemantic neurons that respond to multiple, sometimes unrelated, features, complicating mechanistic interpretability. We introduce the Polysemanticity Index (PSI), a null-calibrated metric that quantifies when a neuron's top activations decompose into semantically distinct clusters. PSI multiplies three independently calibrated components: geometric cluster quality (S), alignment to labeled categories (Q), and open-vocabulary semantic distinctness via CLIP (D). On a pretrained ResNet-50 evaluated with Tiny-ImageNet images, PSI identifies neurons whose activation sets split into coherent, nameable prototypes, and reveals strong depth trends: later layers exhibit substantially higher PSI than earlier layers. We validate our approach with robustness checks (varying hyperparameters, random seeds, and cross-encoder text heads), breadth analyses (comparing class-only vs. open-vocabulary concepts), and causal patch-swap interventions. In particular, aligned patch replacements increase target-neuron activation significantly more than non-aligned, random, shuffled-position, or ablate-elsewhere controls. PSI thus offers a principled and practical lever for discovering, quantifying, and studying polysemantic units in neural networks.
Over-the-Air Design of GAN Training for mmWave MIMO Channel Estimation
May 25, 2022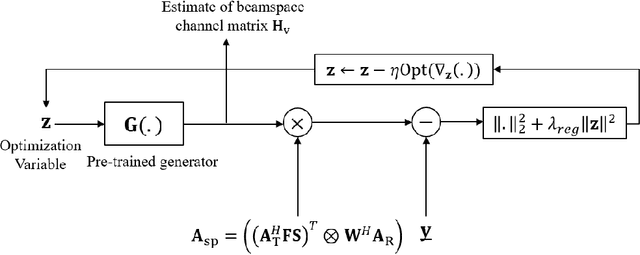
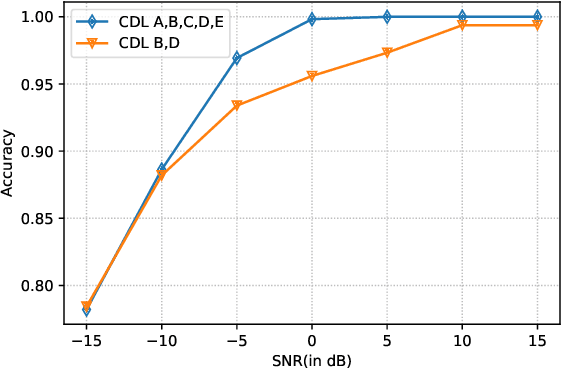
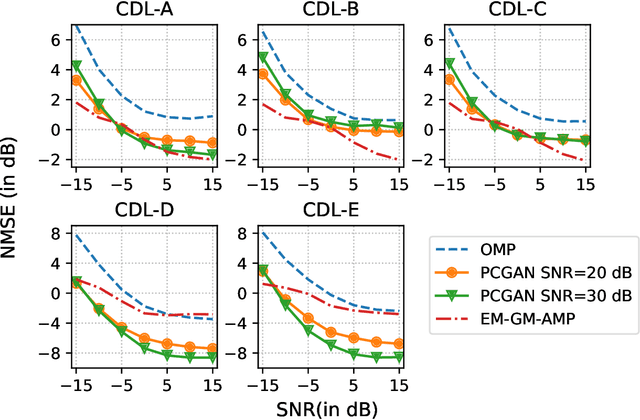
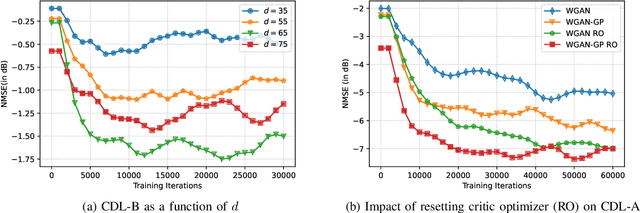
Future wireless systems are trending towards higher carrier frequencies that offer larger communication bandwidth but necessitate the use of large antenna arrays. Existing signal processing techniques for channel estimation do not scale well to this "high-dimensional" regime in terms of performance and pilot overhead. Meanwhile, training deep learning based approaches for channel estimation requires large labeled datasets mapping pilot measurements to clean channel realizations, which can only be generated offline using simulated channels. In this paper, we develop a novel unsupervised over-the-air (OTA) algorithm that utilizes noisy received pilot measurements to train a deep generative model to output beamspace MIMO channel realizations. Our approach leverages Generative Adversarial Networks (GAN), while using a conditional input to distinguish between Line-of-Sight (LOS) and Non-Line-of-Sight (NLOS) channel realizations. We also present a federated implementation of the OTA algorithm that distributes the GAN training over multiple users and greatly reduces the user side computation. We then formulate channel estimation from a limited number of pilot measurements as an inverse problem and reconstruct the channel by optimizing the input vector of the trained generative model. Our proposed approach significantly outperforms Orthogonal Matching Pursuit on both LOS and NLOS channel models, and EM-GM-AMP -- an Approximate Message Passing algorithm -- on LOS channel models, while achieving comparable performance on NLOS channel models in terms of the normalized channel reconstruction error. More importantly, our proposed framework has the potential to be trained online using real noisy pilot measurements, is not restricted to a specific channel model and can even be utilized for a federated OTA design of a dataset generator from noisy data.
System-Level Analysis of Full-Duplex Self-Backhauled Millimeter Wave Networks
Dec 10, 2021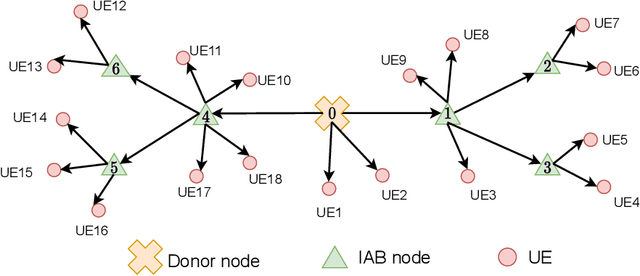

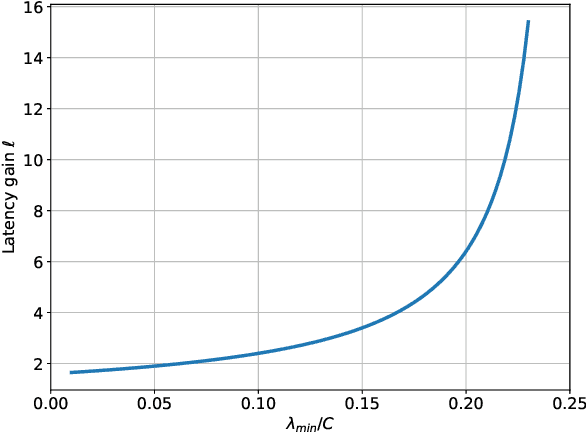

Integrated access and backhaul (IAB) facilitates cost-effective deployment of millimeter wave(mmWave) cellular networks through multihop self-backhauling. Full-duplex (FD) technology, particularly for mmWave systems, is a potential means to overcome latency and throughput challenges faced by IAB networks. We derive practical and tractable throughput and latency constraints using queueing theory and formulate a network utility maximization problem to evaluate both FD-IAB and half-duplex(HD)-IAB networks. We use this to characterize the network-level improvements seen when upgrading from conventional HD IAB nodes to FD ones by deriving closed-form expressions for (i) latency gain of FD-IAB over HD-IAB and (ii) the maximum number of hops that a HD- and FD-IAB network can support while satisfying latency and throughput targets. Extensive simulations illustrate that FD-IAB can facilitate reduced latency, higher throughput, deeper networks, and fairer service. Compared to HD-IAB,FD-IAB can improve throughput by 8x and reduce latency by 4x for a fourth-hop user. In fact, upgrading IAB nodes with FD capability can allow the network to support latency and throughput targets that its HD counterpart fundamentally cannot meet. The gains are more profound for users further from the donor and can be achieved even when residual self-interference is significantly above the noise floor.