 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartition of unity networks: deep hp-approximation
Jan 27, 2021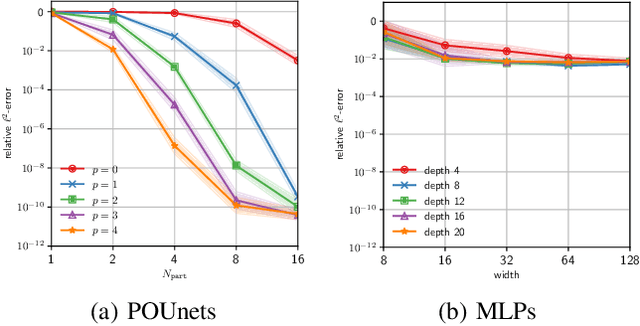
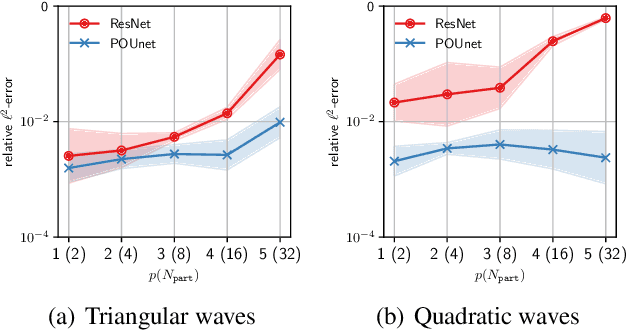
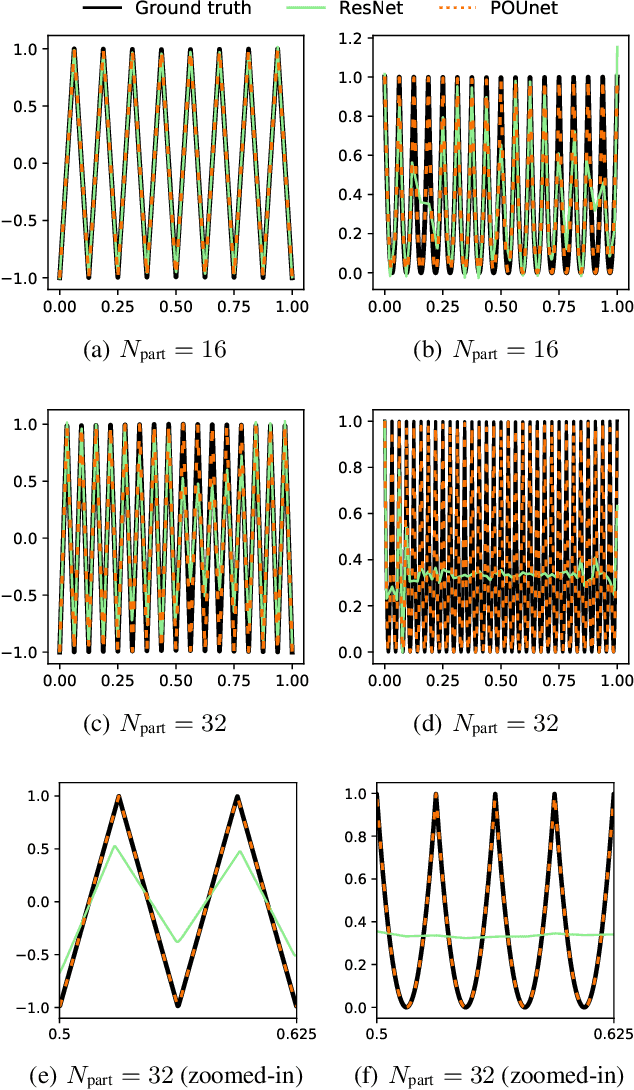
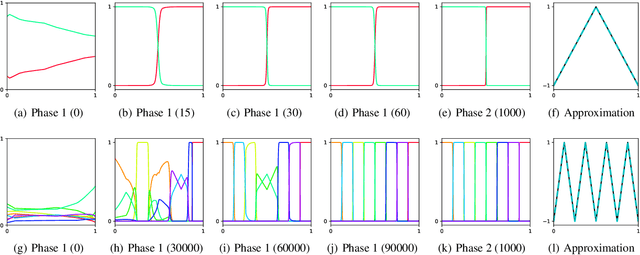
Approximation theorists have established best-in-class optimal approximation rates of deep neural networks by utilizing their ability to simultaneously emulate partitions of unity and monomials. Motivated by this, we propose partition of unity networks (POUnets) which incorporate these elements directly into the architecture. Classification architectures of the type used to learn probability measures are used to build a meshfree partition of space, while polynomial spaces with learnable coefficients are associated to each partition. The resulting hp-element-like approximation allows use of a fast least-squares optimizer, and the resulting architecture size need not scale exponentially with spatial dimension, breaking the curse of dimensionality. An abstract approximation result establishes desirable properties to guide network design. Numerical results for two choices of architecture demonstrate that POUnets yield hp-convergence for smooth functions and consistently outperform MLPs for piecewise polynomial functions with large numbers of discontinuities.
A block coordinate descent optimizer for classification problems exploiting convexity
Jun 17, 2020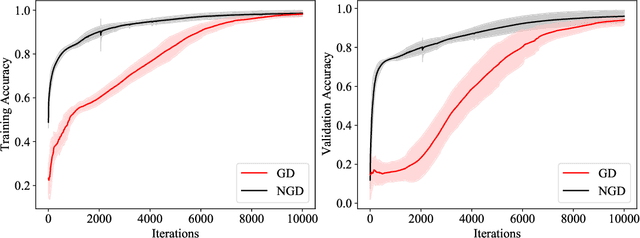
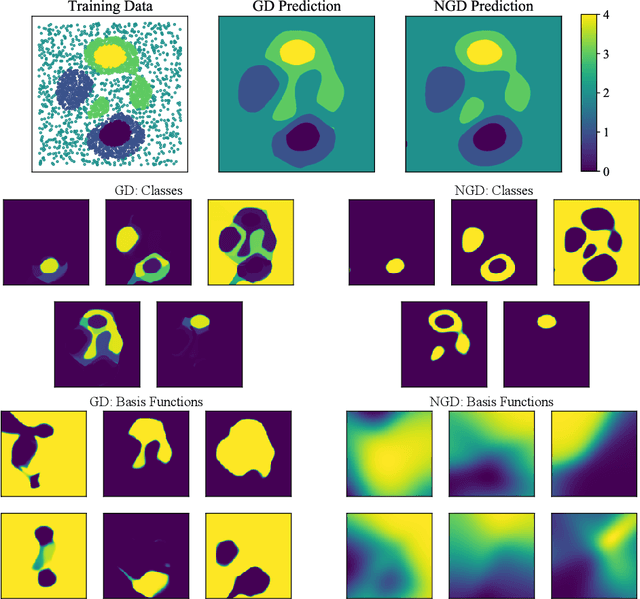
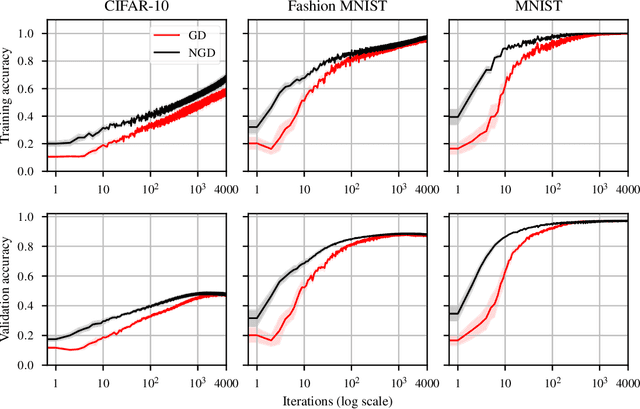
Second-order optimizers hold intriguing potential for deep learning, but suffer from increased cost and sensitivity to the non-convexity of the loss surface as compared to gradient-based approaches. We introduce a coordinate descent method to train deep neural networks for classification tasks that exploits global convexity of the cross-entropy loss in the weights of the linear layer. Our hybrid Newton/Gradient Descent (NGD) method is consistent with the interpretation of hidden layers as providing an adaptive basis and the linear layer as providing an optimal fit of the basis to data. By alternating between a second-order method to find globally optimal parameters for the linear layer and gradient descent to train the hidden layers, we ensure an optimal fit of the adaptive basis to data throughout training. The size of the Hessian in the second-order step scales only with the number weights in the linear layer and not the depth and width of the hidden layers; furthermore, the approach is applicable to arbitrary hidden layer architecture. Previous work applying this adaptive basis perspective to regression problems demonstrated significant improvements in accuracy at reduced training cost, and this work can be viewed as an extension of this approach to classification problems. We first prove that the resulting Hessian matrix is symmetric semi-definite, and that the Newton step realizes a global minimizer. By studying classification of manufactured two-dimensional point cloud data, we demonstrate both an improvement in validation error and a striking qualitative difference in the basis functions encoded in the hidden layer when trained using NGD. Application to image classification benchmarks for both dense and convolutional architectures reveals improved training accuracy, suggesting possible gains of second-order methods over gradient descent.
Robust Training and Initialization of Deep Neural Networks: An Adaptive Basis Viewpoint
Dec 10, 2019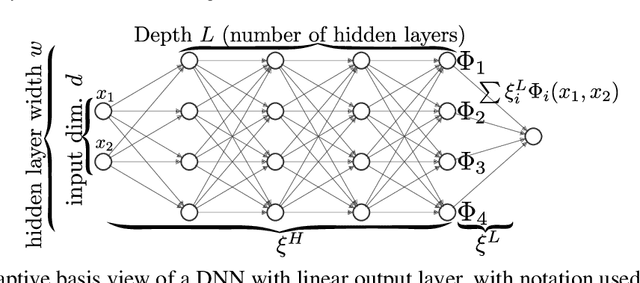
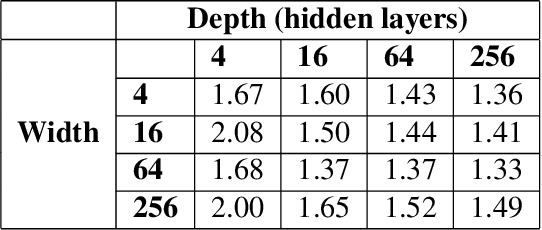
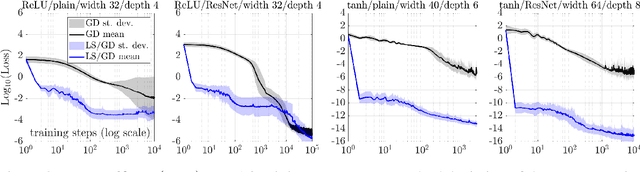
Motivated by the gap between theoretical optimal approximation rates of deep neural networks (DNNs) and the accuracy realized in practice, we seek to improve the training of DNNs. The adoption of an adaptive basis viewpoint of DNNs leads to novel initializations and a hybrid least squares/gradient descent optimizer. We provide analysis of these techniques and illustrate via numerical examples dramatic increases in accuracy and convergence rate for benchmarks characterizing scientific applications where DNNs are currently used, including regression problems and physics-informed neural networks for the solution of partial differential equations.