 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Continual Learning via CLAMP
May 12, 2024



Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10\%$ margin.
Mixup Domain Adaptations for Dynamic Remaining Useful Life Predictions
Apr 07, 2024



Remaining Useful Life (RUL) predictions play vital role for asset planning and maintenance leading to many benefits to industries such as reduced downtime, low maintenance costs, etc. Although various efforts have been devoted to study this topic, most existing works are restricted for i.i.d conditions assuming the same condition of the training phase and the deployment phase. This paper proposes a solution to this problem where a mix-up domain adaptation (MDAN) is put forward. MDAN encompasses a three-staged mechanism where the mix-up strategy is not only performed to regularize the source and target domains but also applied to establish an intermediate mix-up domain where the source and target domains are aligned. The self-supervised learning strategy is implemented to prevent the supervision collapse problem. Rigorous evaluations have been performed where MDAN is compared to recently published works for dynamic RUL predictions. MDAN outperforms its counterparts with substantial margins in 12 out of 12 cases. In addition, MDAN is evaluated with the bearing machine dataset where it beats prior art with significant gaps in 8 of 12 cases. Source codes of MDAN are made publicly available in \url{https://github.com/furqon3009/MDAN}.
* accepted for publication in Knowledge-based Systems
Towards Cross-Domain Continual Learning
Feb 19, 2024



Continual learning is a process that involves training learning agents to sequentially master a stream of tasks or classes without revisiting past data. The challenge lies in leveraging previously acquired knowledge to learn new tasks efficiently, while avoiding catastrophic forgetting. Existing methods primarily focus on single domains, restricting their applicability to specific problems. In this work, we introduce a novel approach called Cross-Domain Continual Learning (CDCL) that addresses the limitations of being limited to single supervised domains. Our method combines inter- and intra-task cross-attention mechanisms within a compact convolutional network. This integration enables the model to maintain alignment with features from previous tasks, thereby delaying the data drift that may occur between tasks, while performing unsupervised cross-domain (UDA) between related domains. By leveraging an intra-task-specific pseudo-labeling method, we ensure accurate input pairs for both labeled and unlabeled samples, enhancing the learning process. To validate our approach, we conduct extensive experiments on public UDA datasets, showcasing its positive performance on cross-domain continual learning challenges. Additionally, our work introduces incremental ideas that contribute to the advancement of this field. We make our code and models available to encourage further exploration and reproduction of our results: \url{https://github.com/Ivsucram/CDCL}
Cross-Domain Few-Shot Learning via Adaptive Transformer Networks
Jan 25, 2024Most few-shot learning works rely on the same domain assumption between the base and the target tasks, hindering their practical applications. This paper proposes an adaptive transformer network (ADAPTER), a simple but effective solution for cross-domain few-shot learning where there exist large domain shifts between the base task and the target task. ADAPTER is built upon the idea of bidirectional cross-attention to learn transferable features between the two domains. The proposed architecture is trained with DINO to produce diverse, and less biased features to avoid the supervision collapse problem. Furthermore, the label smoothing approach is proposed to improve the consistency and reliability of the predictions by also considering the predicted labels of the close samples in the embedding space. The performance of ADAPTER is rigorously evaluated in the BSCD-FSL benchmarks in which it outperforms prior arts with significant margins.
Dynamic Long-Term Time-Series Forecasting via Meta Transformer Networks
Jan 25, 2024



A reliable long-term time-series forecaster is highly demanded in practice but comes across many challenges such as low computational and memory footprints as well as robustness against dynamic learning environments. This paper proposes Meta-Transformer Networks (MANTRA) to deal with the dynamic long-term time-series forecasting tasks. MANTRA relies on the concept of fast and slow learners where a collection of fast learners learns different aspects of data distributions while adapting quickly to changes. A slow learner tailors suitable representations to fast learners. Fast adaptations to dynamic environments are achieved using the universal representation transformer layers producing task-adapted representations with a small number of parameters. Our experiments using four datasets with different prediction lengths demonstrate the advantage of our approach with at least $3\%$ improvements over the baseline algorithms for both multivariate and univariate settings. Source codes of MANTRA are publicly available in \url{https://github.com/anwarmaxsum/MANTRA}.
Few-Shot Continual Learning via Flat-to-Wide Approaches
Jul 14, 2023



Existing approaches on continual learning call for a lot of samples in their training processes. Such approaches are impractical for many real-world problems having limited samples because of the overfitting problem. This paper proposes a few-shot continual learning approach, termed FLat-tO-WidE AppRoach (FLOWER), where a flat-to-wide learning process finding the flat-wide minima is proposed to address the catastrophic forgetting problem. The issue of data scarcity is overcome with a data augmentation approach making use of a ball generator concept to restrict the sampling space into the smallest enclosing ball. Our numerical studies demonstrate the advantage of FLOWER achieving significantly improved performances over prior arts notably in the small base tasks. For further study, source codes of FLOWER, competitor algorithms and experimental logs are shared publicly in \url{https://github.com/anwarmaxsum/FLOWER}.
Assessor-Guided Learning for Continual Environments
Mar 21, 2023



This paper proposes an assessor-guided learning strategy for continual learning where an assessor guides the learning process of a base learner by controlling the direction and pace of the learning process thus allowing an efficient learning of new environments while protecting against the catastrophic interference problem. The assessor is trained in a meta-learning manner with a meta-objective to boost the learning process of the base learner. It performs a soft-weighting mechanism of every sample accepting positive samples while rejecting negative samples. The training objective of a base learner is to minimize a meta-weighted combination of the cross entropy loss function, the dark experience replay (DER) loss function and the knowledge distillation loss function whose interactions are controlled in such a way to attain an improved performance. A compensated over-sampling (COS) strategy is developed to overcome the class imbalanced problem of the episodic memory due to limited memory budgets. Our approach, Assessor-Guided Learning Approach (AGLA), has been evaluated in the class-incremental and task-incremental learning problems. AGLA achieves improved performances compared to its competitors while the theoretical analysis of the COS strategy is offered. Source codes of AGLA, baseline algorithms and experimental logs are shared publicly in \url{https://github.com/anwarmaxsum/AGLA} for further study.
Class-Incremental Learning via Knowledge Amalgamation
Sep 05, 2022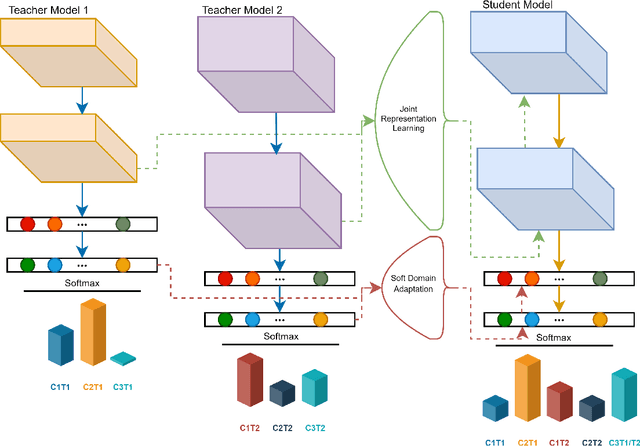
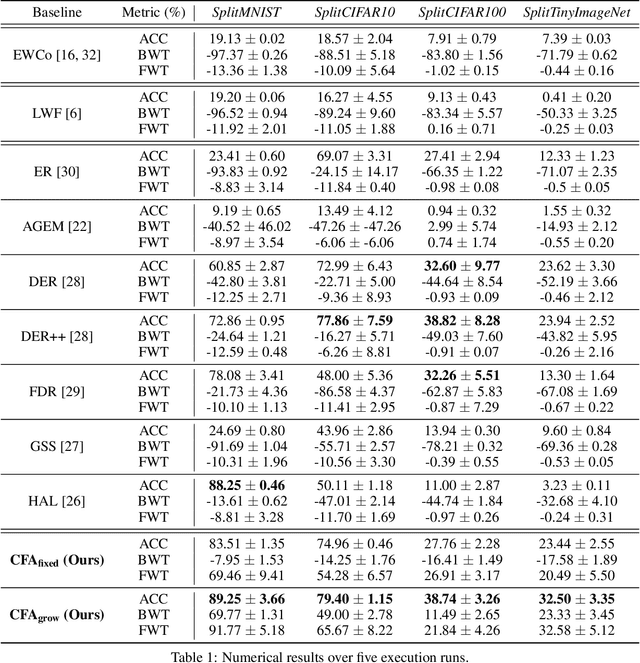
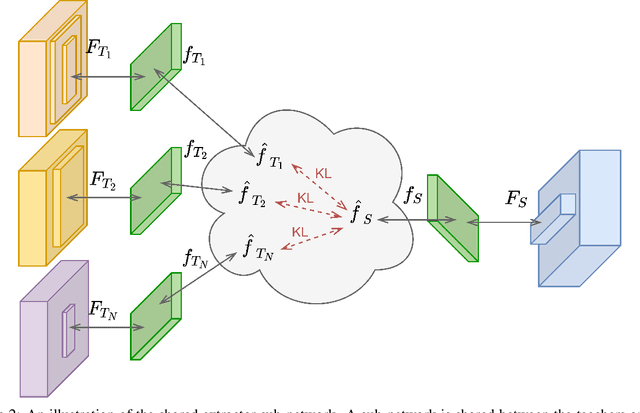
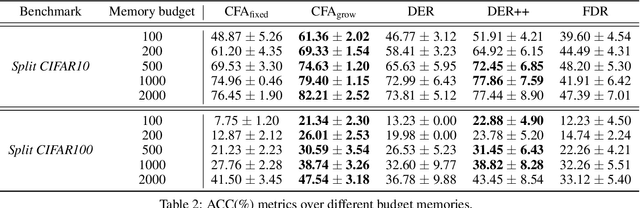
Catastrophic forgetting has been a significant problem hindering the deployment of deep learning algorithms in the continual learning setting. Numerous methods have been proposed to address the catastrophic forgetting problem where an agent loses its generalization power of old tasks while learning new tasks. We put forward an alternative strategy to handle the catastrophic forgetting with knowledge amalgamation (CFA), which learns a student network from multiple heterogeneous teacher models specializing in previous tasks and can be applied to current offline methods. The knowledge amalgamation process is carried out in a single-head manner with only a selected number of memorized samples and no annotations. The teachers and students do not need to share the same network structure, allowing heterogeneous tasks to be adapted to a compact or sparse data representation. We compare our method with competitive baselines from different strategies, demonstrating our approach's advantages.
Scalable Adversarial Online Continual Learning
Sep 04, 2022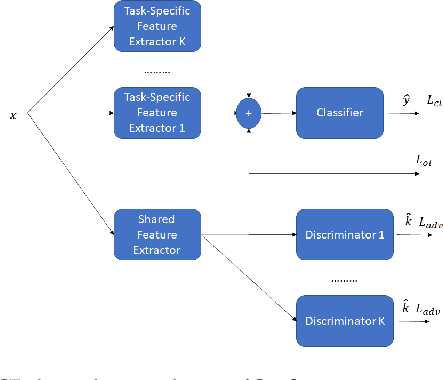
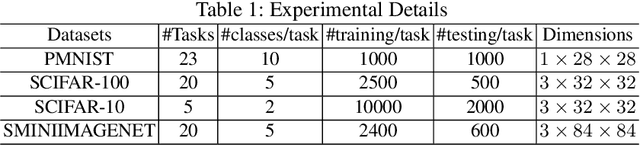
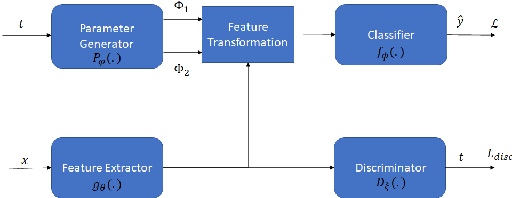
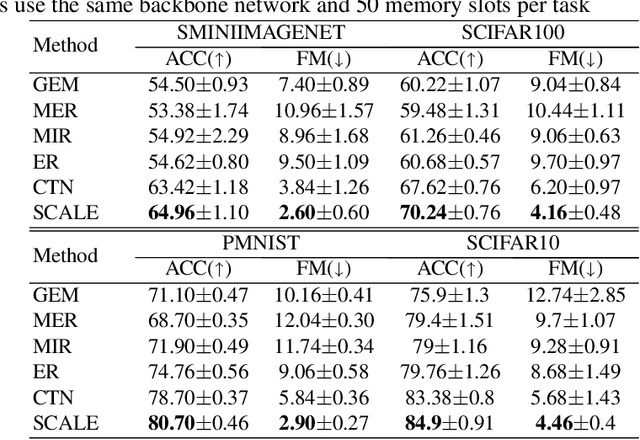
Adversarial continual learning is effective for continual learning problems because of the presence of feature alignment process generating task-invariant features having low susceptibility to the catastrophic forgetting problem. Nevertheless, the ACL method imposes considerable complexities because it relies on task-specific networks and discriminators. It also goes through an iterative training process which does not fit for online (one-epoch) continual learning problems. This paper proposes a scalable adversarial continual learning (SCALE) method putting forward a parameter generator transforming common features into task-specific features and a single discriminator in the adversarial game to induce common features. The training process is carried out in meta-learning fashions using a new combination of three loss functions. SCALE outperforms prominent baselines with noticeable margins in both accuracy and execution time.
Reinforced Continual Learning for Graphs
Sep 04, 2022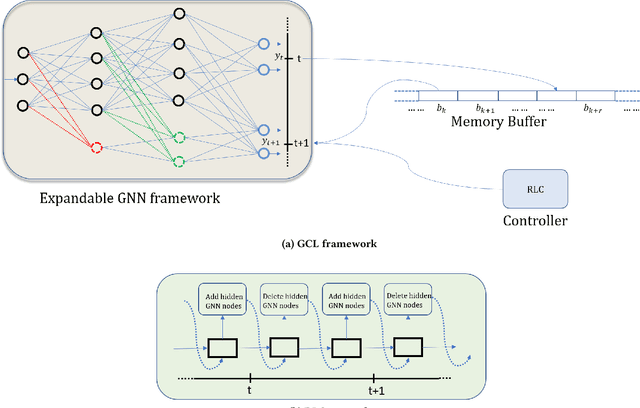
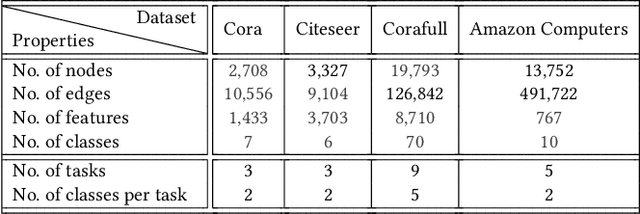
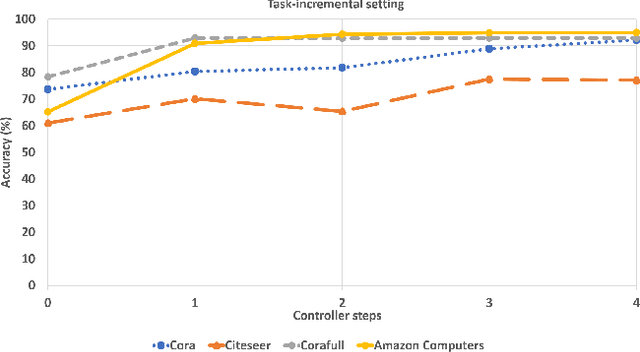
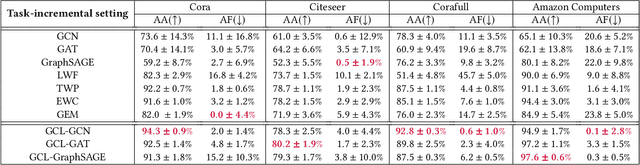
Graph Neural Networks (GNNs) have become the backbone for a myriad of tasks pertaining to graphs and similar topological data structures. While many works have been established in domains related to node and graph classification/regression tasks, they mostly deal with a single task. Continual learning on graphs is largely unexplored and existing graph continual learning approaches are limited to the task-incremental learning scenarios. This paper proposes a graph continual learning strategy that combines the architecture-based and memory-based approaches. The structural learning strategy is driven by reinforcement learning, where a controller network is trained in such a way to determine an optimal number of nodes to be added/pruned from the base network when new tasks are observed, thus assuring sufficient network capacities. The parameter learning strategy is underpinned by the concept of Dark Experience replay method to cope with the catastrophic forgetting problem. Our approach is numerically validated with several graph continual learning benchmark problems in both task-incremental learning and class-incremental learning settings. Compared to recently published works, our approach demonstrates improved performance in both the settings. The implementation code can be found at \url{https://github.com/codexhammer/gcl}.