 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trust Calibration in Socially Interactive Agents: Investigating Gendered Multimodal Behaviors Generation with LLMs
May 19, 2026As Socially Interactive Agents (SIAs) become increasingly integrated into daily life, the ability to calibrate user trust to an agent's actual capabilities would help ensure appropriate usage of these agents. In this paper, we explore the capacity of Large Language Models (LLMs) to generate multimodal behaviors (verbal, vocal, gestural, and facial expression modalities) that reflect varying levels of ability and benevolence, two key dimensions of trustworthiness. We propose a novel method for automatically generating behaviors aligned with specific levels of these traits, a first step towards enabling nuanced and trust-calibrated interactions. By analyzing a large dataset of multimodal transcripts generated by LLMs, we demonstrate that GPT-5.4 is able to produce coherent behavior across different modalities (text, intonation, facial expression, and gesture). Using Random Forest feature importance analysis, we show that the generated behaviors align with theoretical expectations for ability and benevolence. However, we also find that when gender is specified in the prompt, LLMs tend to reproduce societal gender stereotypes, associating male agents' behaviors with high ability and female agents' behaviors with high benevolence. To validate our approach, we conducted a user study on Prolific using a within-subjects design. Participants perceived different levels of ability and benevolence in the generated behaviors align with the intended instructions.
Mitigation of gender bias in automatic facial non-verbal behaviors generation
Oct 09, 2024



Research on non-verbal behavior generation for social interactive agents focuses mainly on the believability and synchronization of non-verbal cues with speech. However, existing models, predominantly based on deep learning architectures, often perpetuate biases inherent in the training data. This raises ethical concerns, depending on the intended application of these agents. This paper addresses these issues by first examining the influence of gender on facial non-verbal behaviors. We concentrate on gaze, head movements, and facial expressions. We introduce a classifier capable of discerning the gender of a speaker from their non-verbal cues. This classifier achieves high accuracy on both real behavior data, extracted using state-of-the-art tools, and synthetic data, generated from a model developed in previous work.Building upon this work, we present a new model, FairGenderGen, which integrates a gender discriminator and a gradient reversal layer into our previous behavior generation model. This new model generates facial non-verbal behaviors from speech features, mitigating gender sensitivity in the generated behaviors. Our experiments demonstrate that the classifier, developed in the initial phase, is no longer effective in distinguishing the gender of the speaker from the generated non-verbal behaviors.
Expressing social attitudes in virtual agents for social training games
Feb 20, 2014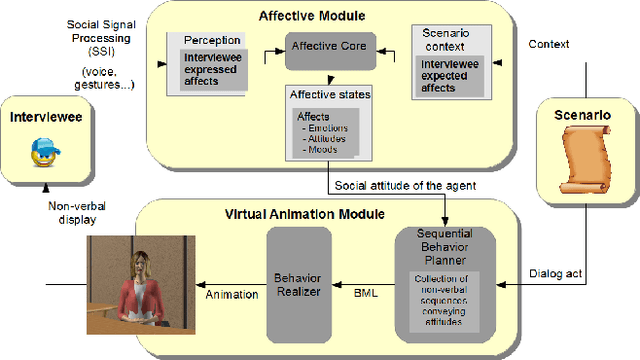
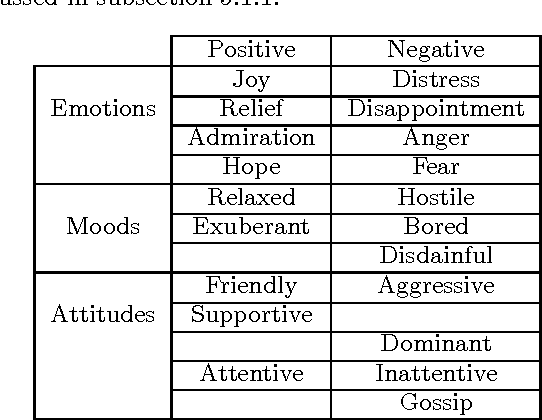
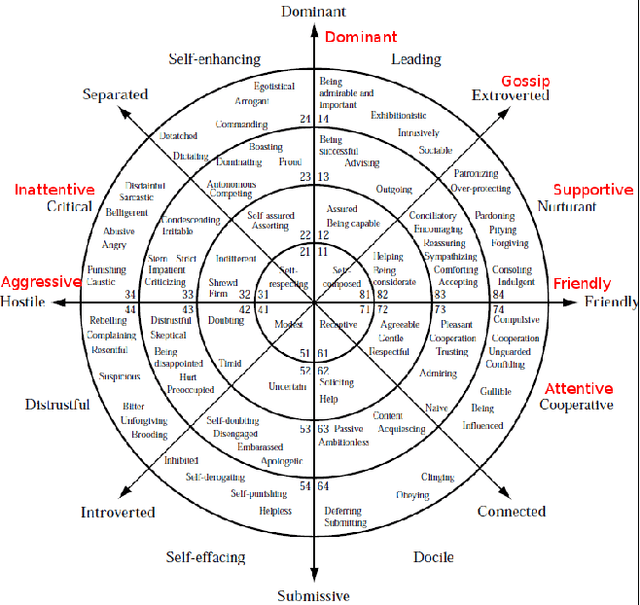
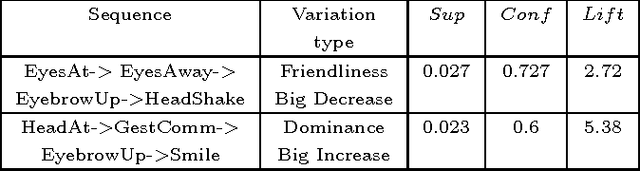
The use of virtual agents in social coaching has increased rapidly in the last decade. In order to train the user in different situations than can occur in real life, the virtual agent should be able to express different social attitudes. In this paper, we propose a model of social attitudes that enables a virtual agent to reason on the appropriate social attitude to express during the interaction with a user given the course of the interaction, but also the emotions, mood and personality of the agent. Moreover, the model enables the virtual agent to display its social attitude through its non-verbal behaviour. The proposed model has been developed in the context of job interview simulation. The methodology used to develop such a model combined a theoretical and an empirical approach. Indeed, the model is based both on the literature in Human and Social Sciences on social attitudes but also on the analysis of an audiovisual corpus of job interviews and on post-hoc interviews with the recruiters on their expressed attitudes during the job interview.