 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSTM: Spatiotemporal Recurrent Transformers for Multi-frame Optical Flow Estimation
Apr 26, 2023Inaccurate optical flow estimates in and near occluded regions, and out-of-boundary regions are two of the current significant limitations of optical flow estimation algorithms. Recent state-of-the-art optical flow estimation algorithms are two-frame based methods where optical flow is estimated sequentially for each consecutive image pair in a sequence. While this approach gives good flow estimates, it fails to generalize optical flows in occluded regions mainly due to limited local evidence regarding moving elements in a scene. In this work, we propose a learning-based multi-frame optical flow estimation method that estimates two or more consecutive optical flows in parallel from multi-frame image sequences. Our underlying hypothesis is that by understanding temporal scene dynamics from longer sequences with more than two frames, we can characterize pixel-wise dependencies in a larger spatiotemporal domain, generalize complex motion patterns and thereby improve the accuracy of optical flow estimates in occluded regions. We present learning-based spatiotemporal recurrent transformers for multi-frame based optical flow estimation (SSTMs). Our method utilizes 3D Convolutional Gated Recurrent Units (3D-ConvGRUs) and spatiotemporal transformers to learn recurrent space-time motion dynamics and global dependencies in the scene and provide a generalized optical flow estimation. When compared with recent state-of-the-art two-frame and multi-frame methods on real world and synthetic datasets, performance of the SSTMs were significantly higher in occluded and out-of-boundary regions. Among all published state-of-the-art multi-frame methods, SSTM achieved state-of the-art results on the Sintel Final and KITTI2015 benchmark datasets.
Multi-Resolution Factor Graph Based Stereo Correspondence Algorithm
Feb 02, 2022A dense depth-map of a scene at an arbitrary view orientation can be estimated from dense view correspondences among multiple lower-dimensional views of the scene. These low-dimensional view correspondences are dependent on the geometrical relationship among the views and the scene. Determining dense view correspondences is difficult in part due to presence of homogeneous regions in the scene and due to presence of occluded regions and illumination differences among the views. We present a new multi-resolution factor graph-based stereo matching algorithm (MR-FGS) that utilizes both intra- and inter-resolution dependencies among the views as well as among the disparity estimates. The proposed framework allows exchange of information among multiple resolutions of the correspondence problem and is useful for handling larger homogeneous regions in a scene. The MR-FGS algorithm was evaluated qualitatively and quantitatively using stereo pairs in the Middlebury stereo benchmark dataset based on commonly used performance measures. When compared to a recently developed factor graph model (FGS), the MR-FGS algorithm provided more accurate disparity estimates without requiring the commonly used post-processing procedure known as the left-right consistency check. The multi-resolution dependency constraint within the factor-graph model significantly improved contrast along depth boundaries in the MR-FGS generated disparity maps.
A Novel Factor Graph-Based Optimization Technique for Stereo Correspondence Estimation
Sep 22, 2021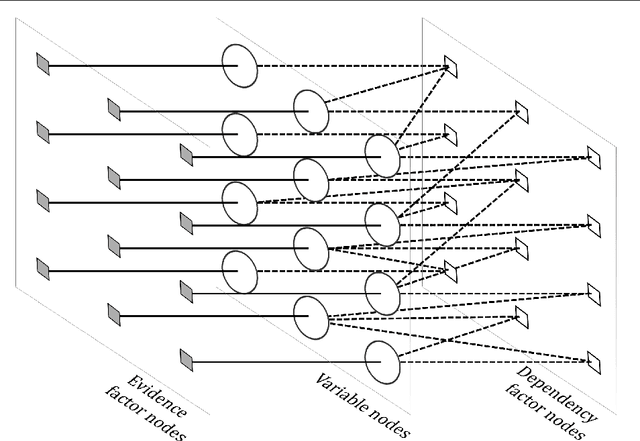
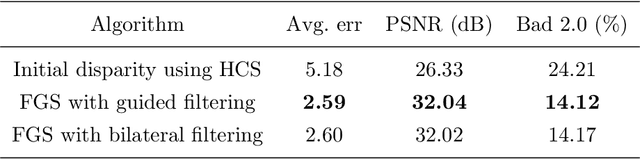
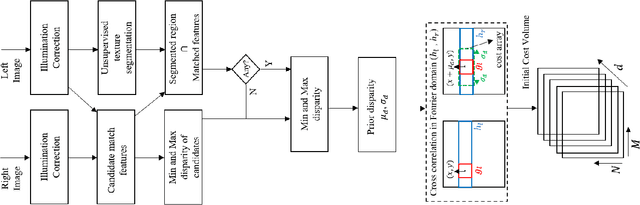
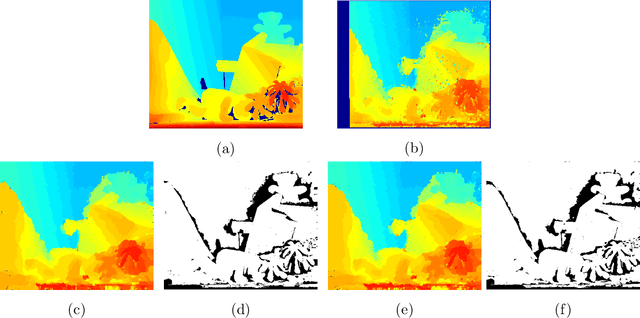
Dense disparities among multiple views is essential for estimating the 3D architecture of a scene based on the geometrical relationship among the scene and the views or cameras. Scenes with larger extents of heterogeneous textures, differing scene illumination among the multiple views and with occluding objects affect the accuracy of the estimated disparities. Markov random fields (MRF) based methods for disparity estimation address these limitations using spatial dependencies among the observations and among the disparity estimates. These methods, however, are limited by spatially fixed and smaller neighborhood systems or cliques. In this work, we present a new factor graph-based probabilistic graphical model for disparity estimation that allows a larger and a spatially variable neighborhood structure determined based on the local scene characteristics. We evaluated our method using the Middlebury benchmark stereo datasets and the Middlebury evaluation dataset version 3.0 and compared its performance with recent state-of-the-art disparity estimation algorithms. The new factor graph-based method provided disparity estimates with higher accuracy when compared to the recent non-learning- and learning-based disparity estimation algorithms. In addition to disparity estimation, our factor graph formulation can be useful for obtaining maximum a posteriori solution to optimization problems with complex and variable dependency structures as well as for other dense estimation problems such as optical flow estimation.
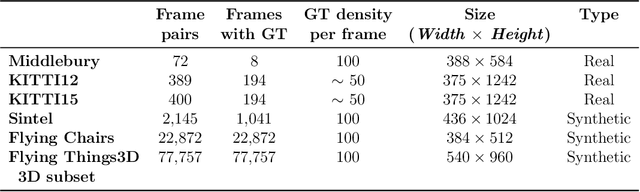
DDCNet-Multires: Effective Receptive Field Guided Multiresolution CNN for Dense Prediction
Jul 12, 2021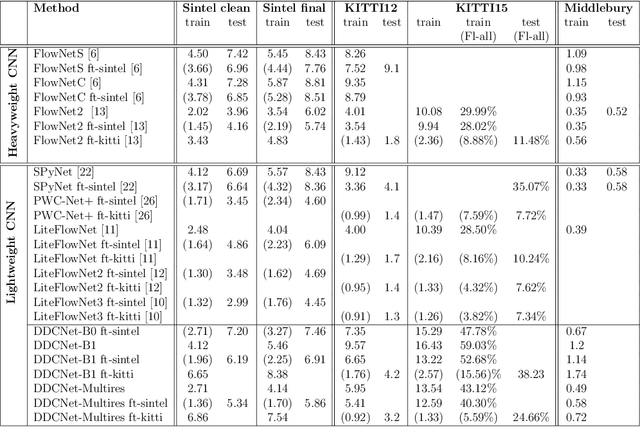
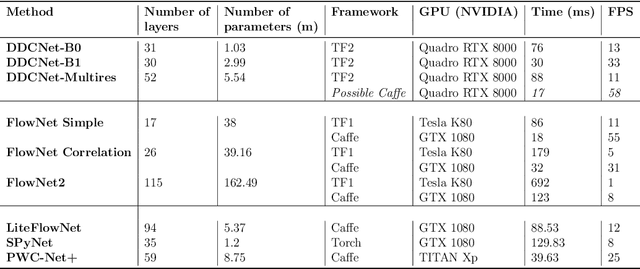

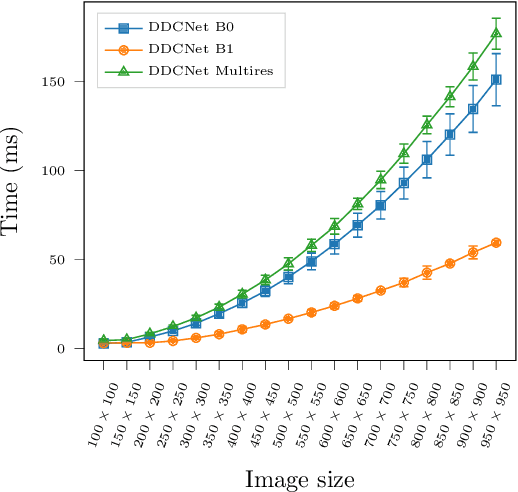
Dense optical flow estimation is challenging when there are large displacements in a scene with heterogeneous motion dynamics, occlusion, and scene homogeneity. Traditional approaches to handle these challenges include hierarchical and multiresolution processing methods. Learning-based optical flow methods typically use a multiresolution approach with image warping when a broad range of flow velocities and heterogeneous motion is present. Accuracy of such coarse-to-fine methods is affected by the ghosting artifacts when images are warped across multiple resolutions and by the vanishing problem in smaller scene extents with higher motion contrast. Previously, we devised strategies for building compact dense prediction networks guided by the effective receptive field (ERF) characteristics of the network (DDCNet). The DDCNet design was intentionally simple and compact allowing it to be used as a building block for designing more complex yet compact networks. In this work, we extend the DDCNet strategies to handle heterogeneous motion dynamics by cascading DDCNet based sub-nets with decreasing extents of their ERF. Our DDCNet with multiresolution capability (DDCNet-Multires) is compact without any specialized network layers. We evaluate the performance of the DDCNet-Multires network using standard optical flow benchmark datasets. Our experiments demonstrate that DDCNet-Multires improves over the DDCNet-B0 and -B1 and provides optical flow estimates with accuracy comparable to similar lightweight learning-based methods.
DDCNet: Deep Dilated Convolutional Neural Network for Dense Prediction
Jul 09, 2021

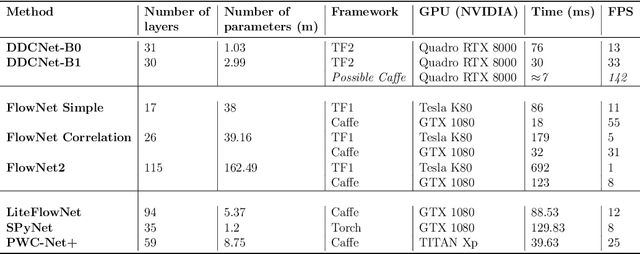
Dense pixel matching problems such as optical flow and disparity estimation are among the most challenging tasks in computer vision. Recently, several deep learning methods designed for these problems have been successful. A sufficiently larger effective receptive field (ERF) and a higher resolution of spatial features within a network are essential for providing higher-resolution dense estimates. In this work, we present a systemic approach to design network architectures that can provide a larger receptive field while maintaining a higher spatial feature resolution. To achieve a larger ERF, we utilized dilated convolutional layers. By aggressively increasing dilation rates in the deeper layers, we were able to achieve a sufficiently larger ERF with a significantly fewer number of trainable parameters. We used optical flow estimation problem as the primary benchmark to illustrate our network design strategy. The benchmark results (Sintel, KITTI, and Middlebury) indicate that our compact networks can achieve comparable performance in the class of lightweight networks.