 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More Accurate Automatic Sleep Staging via Deep Transfer Learning
Jul 30, 2019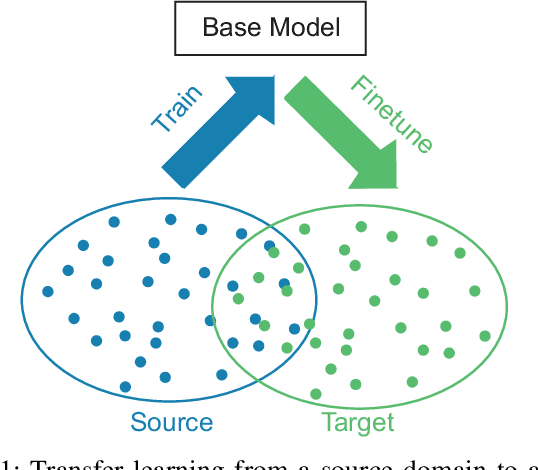
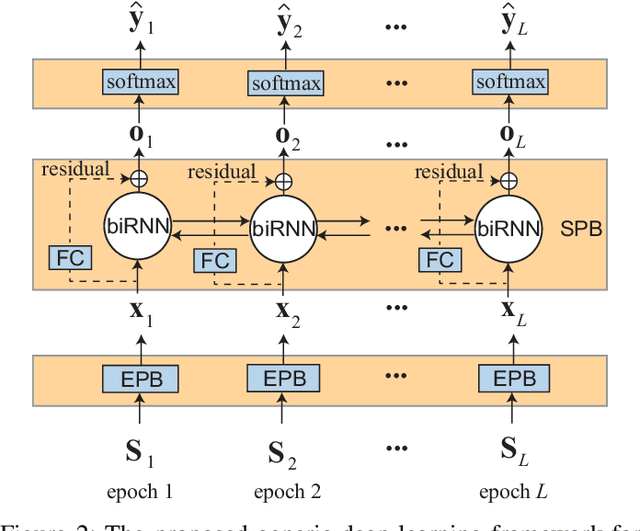
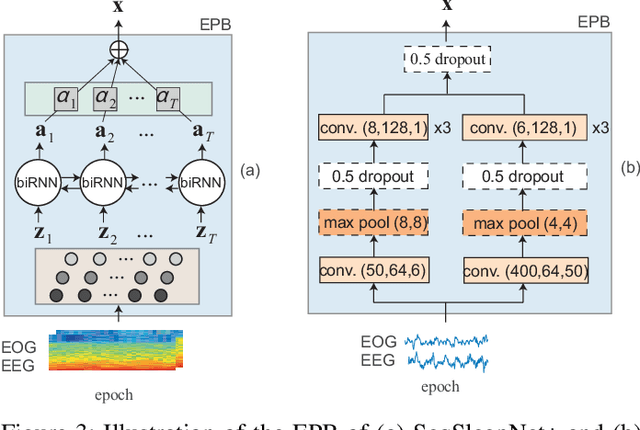
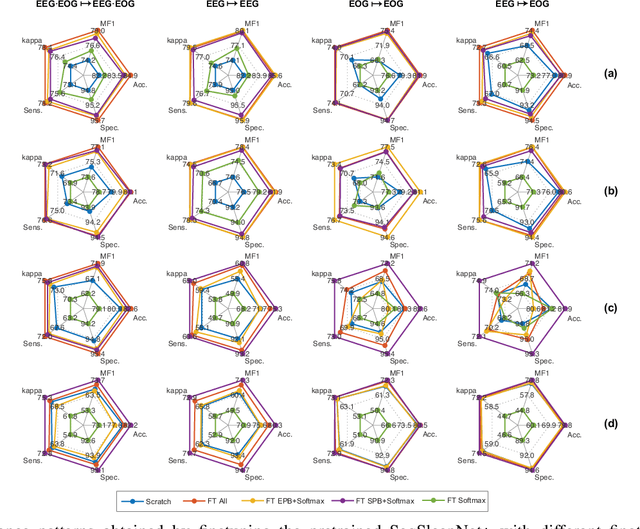
Although large annotated sleep databases are publicly available, and might be used to train automated scoring algorithms, it might still be a challenge to develop an optimal algorithm for your personal sleep study, which might have few subjects or rely on a different recording setup. Both directly applying a learned algorithm or retraining the algorithm on your rather small database is suboptimal. And definitely state-of-the-art sleep staging algorithms based on deep neural networks demand a large amount of data to be trained. This work presents a deep transfer learning approach to overcome the channel mismatch problem and enable transferring knowledge from a large dataset to a small cohort for automatic sleep staging. We start from a generic end-to-end deep learning framework for sequence-to-sequence sleep staging and derive two networks adhering to this framework as a device for transfer learning. The networks are first trained in the source domain (i.e. the large database). The pretrained networks are then finetuned in the target domain, i.e. the small cohort, to complete knowledge transfer. We employ the Montreal Archive of Sleep Studies (MASS) database consisting of 200 subjects as the source domain and study deep transfer learning on four different target domains: the Sleep Cassette subset and the Sleep Telemetry subset of the Sleep-EDF Expanded database, the Surrey-cEEGGrid database, and the Surrey-PSG database. The target domains are purposely adopted to cover different degrees of channel mismatch to the source domain. Our experimental results show significant performance improvement on automatic sleep staging on the target domains achieved with the proposed deep transfer learning approach and we discuss the impact of various fine tuning approaches.
Deep Transfer Learning for Single-Channel Automatic Sleep Staging with Channel Mismatch
Apr 11, 2019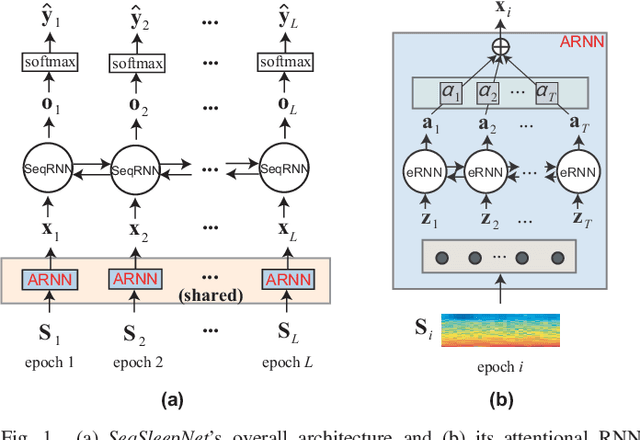
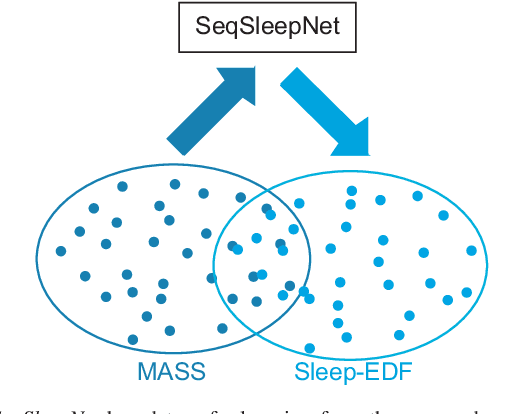
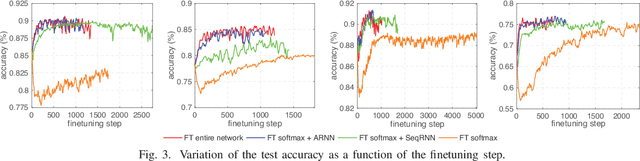
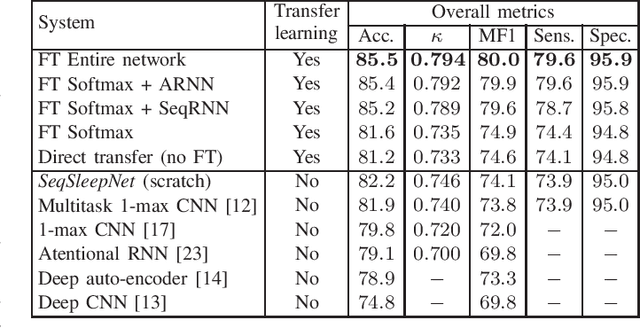
Many sleep studies suffer from the problem of insufficient data to fully utilize deep neural networks as different labs use different recordings set ups, leading to the need of training automated algorithms on rather small databases, whereas large annotated databases are around but cannot be directly included into these studies for data compensation due to channel mismatch. This work presents a deep transfer learning approach to overcome the channel mismatch problem and transfer knowledge from a large dataset to a small cohort to study automatic sleep staging with single-channel input. We employ the state-of-the-art SeqSleepNet and train the network in the source domain, i.e. the large dataset. Afterwards, the pretrained network is finetuned in the target domain, i.e. the small cohort, to complete knowledge transfer. We study two transfer learning scenarios with slight and heavy channel mismatch between the source and target domains. We also investigate whether, and if so, how finetuning entirely or partially the pretrained network would affect the performance of sleep staging on the target domain. Using the Montreal Archive of Sleep Studies (MASS) database consisting of 200 subjects as the source domain and the Sleep-EDF Expanded database consisting of 20 subjects as the target domain in this study, our experimental results show significant performance improvement on sleep staging achieved with the proposed deep transfer learning approach. Furthermore, these results also reveal the essential of finetuning the feature-learning parts of the pretrained network to be able to bypass the channel mismatch problem.
Spatio-Temporal Attention Pooling for Audio Scene Classification
Apr 06, 2019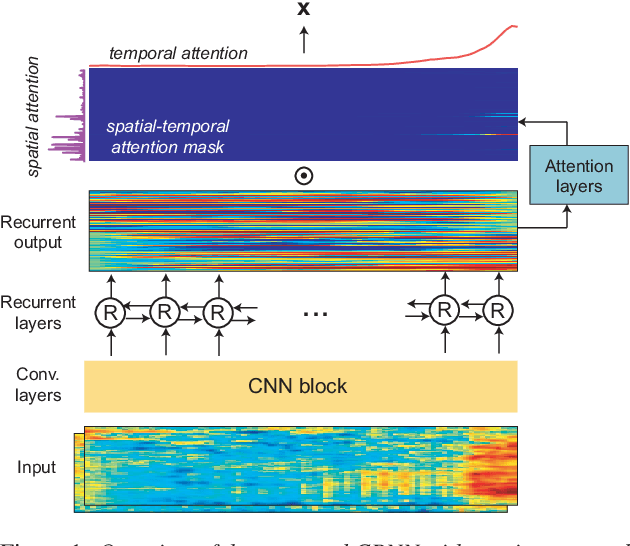
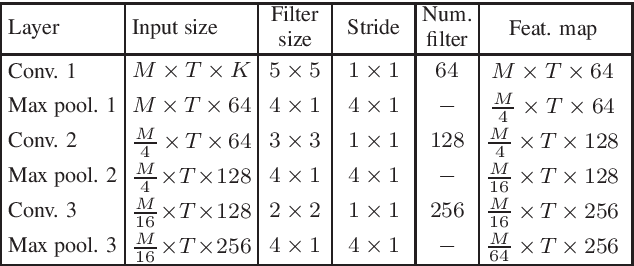
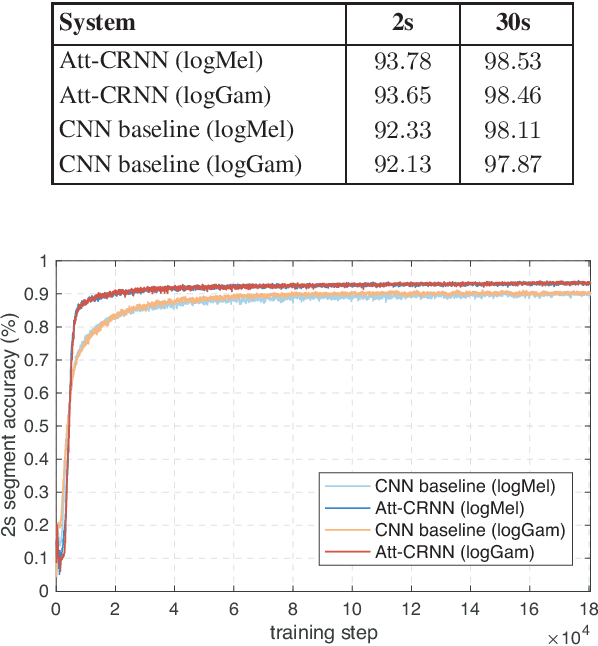
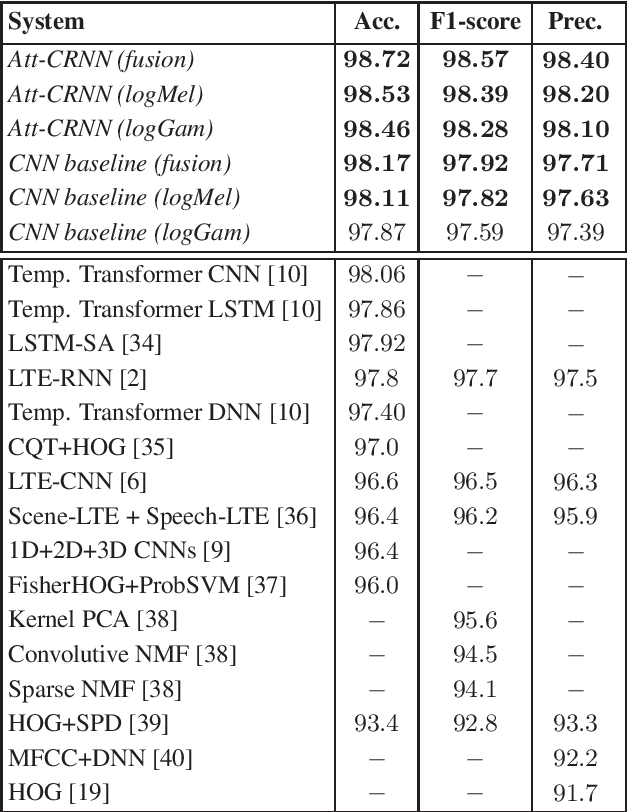
Acoustic scenes are rich and redundant in their content. In this work, we present a spatio-temporal attention pooling layer coupled with a convolutional recurrent neural network to learn from patterns that are discriminative while suppressing those that are irrelevant for acoustic scene classification. The convolutional layers in this network learn invariant features from time-frequency input. The bidirectional recurrent layers are then able to encode the temporal dynamics of the resulting convolutional features. Afterwards, a two-dimensional attention mask is formed via the outer product of the spatial and temporal attention vectors learned from two designated attention layers to weigh and pool the recurrent output into a final feature vector for classification. The network is trained with between-class examples generated from between-class data augmentation. Experiments demonstrate that the proposed method not only outperforms a strong convolutional neural network baseline but also sets new state-of-the-art performance on the LITIS Rouen dataset.
Detection of REM Sleep Behaviour Disorder by Automated Polysomnography Analysis
Nov 12, 2018
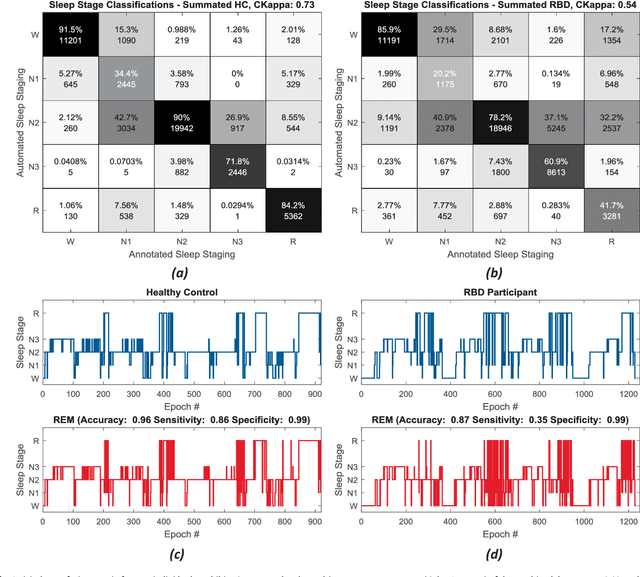
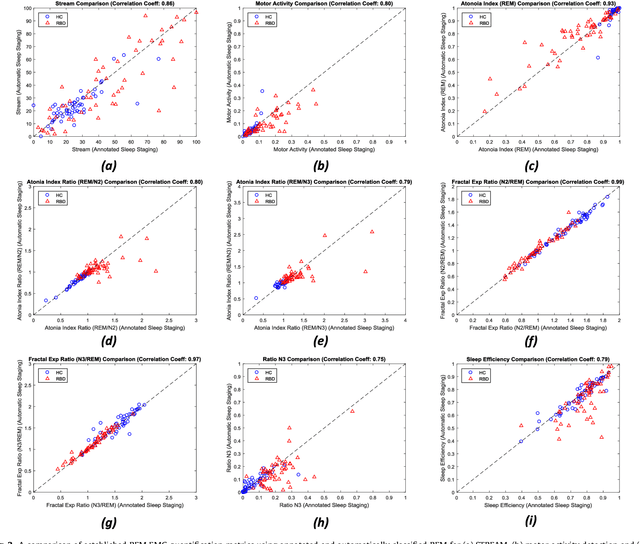
Evidence suggests Rapid-Eye-Movement (REM) Sleep Behaviour Disorder (RBD) is an early predictor of Parkinson's disease. This study proposes a fully-automated framework for RBD detection consisting of automated sleep staging followed by RBD identification. Analysis was assessed using a limited polysomnography montage from 53 participants with RBD and 53 age-matched healthy controls. Sleep stage classification was achieved using a Random Forest (RF) classifier and 156 features extracted from electroencephalogram (EEG), electrooculogram (EOG) and electromyogram (EMG) channels. For RBD detection, a RF classifier was trained combining established techniques to quantify muscle atonia with additional features that incorporate sleep architecture and the EMG fractal exponent. Automated multi-state sleep staging achieved a 0.62 Cohen's Kappa score. RBD detection accuracy improved by 10% to 96% (compared to individual established metrics) when using manually annotated sleep staging. Accuracy remained high (92%) when using automated sleep staging. This study outperforms established metrics and demonstrates that incorporating sleep architecture and sleep stage transitions can benefit RBD detection. This study also achieved automated sleep staging with a level of accuracy comparable to manual annotation. This study validates a tractable, fully-automated, and sensitive pipeline for RBD identification that could be translated to wearable take-home technology.
Beyond Equal-Length Snippets: How Long is Sufficient to Recognize an Audio Scene?
Nov 02, 2018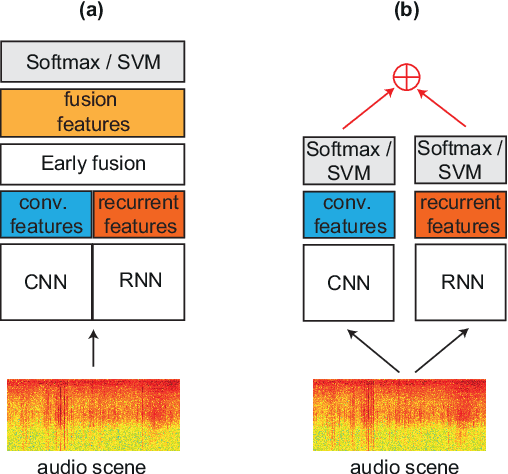

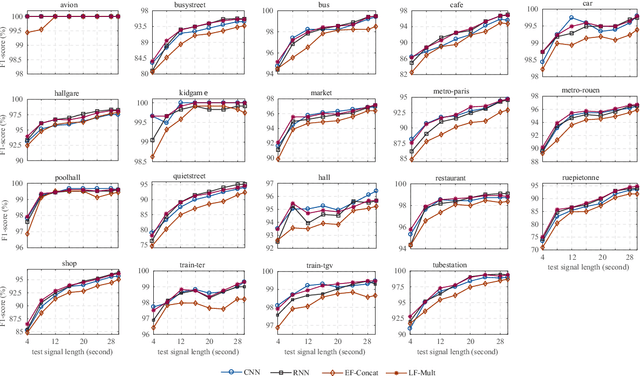
Due to the variability in characteristics of audio scenes, some can naturally be recognized earlier, i.e. after a shorter duration, than others. In this work, rather than using equal-length snippets for all scene categories, as is common in the literature, we study to which temporal extent an audio scene can be reliably recognized. For modelling, in addition to two single-network systems relying on a convolutional neural network and a recurrent neural network, we also investigate early fusion and late fusion of these two single networks for audio scene classification. Moreover, as model fusion is prevalent in audio scene classifiers, we further aim to study whether and when model fusion is really necessary for this task.
Unifying Isolated and Overlapping Audio Event Detection with Multi-Label Multi-Task Convolutional Recurrent Neural Networks
Nov 02, 2018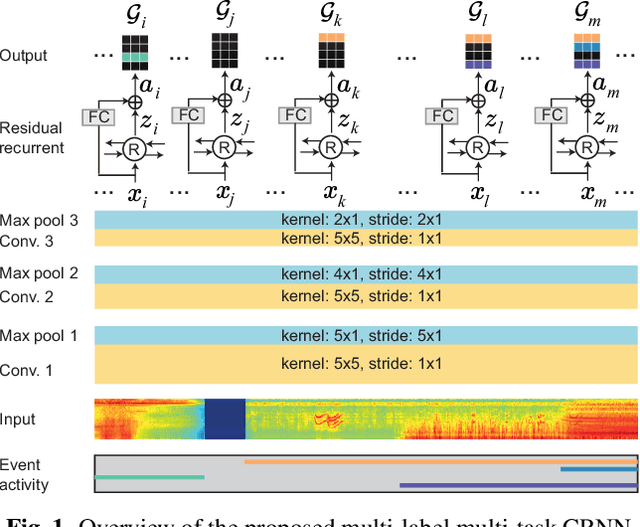
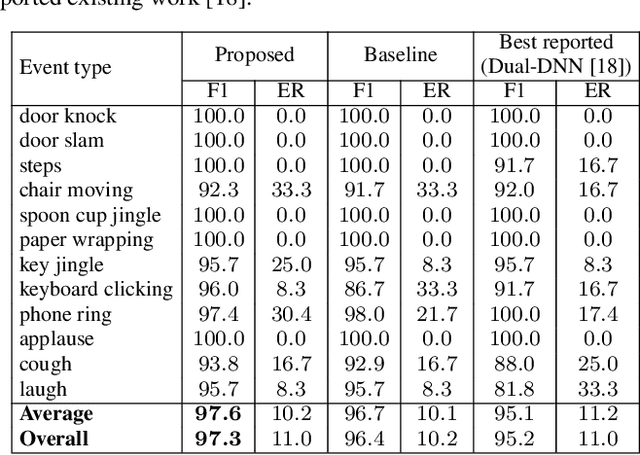
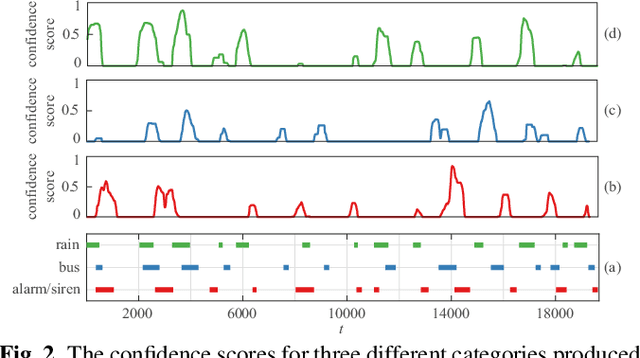
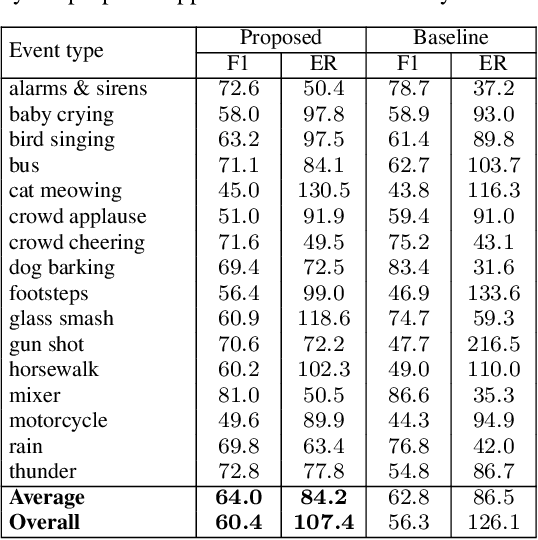
We propose a multi-label multi-task framework based on a convolutional recurrent neural network to unify detection of isolated and overlapping audio events. The framework leverages the power of convolutional recurrent neural network architectures; convolutional layers learn effective features over which higher recurrent layers perform sequential modelling. Furthermore, the output layer is designed to handle arbitrary degrees of event overlap. At each time step in the recurrent output sequence, an output triple is dedicated to each event category of interest to jointly model event occurrence and temporal boundaries. That is, the network jointly determines whether an event of this category occurs, and when it occurs, by estimating onset and offset positions at each recurrent time step. We then introduce three sequential losses for network training: multi-label classification loss, distance estimation loss, and confidence loss. We demonstrate good generalization on two datasets: ITC-Irst for isolated audio event detection, and TUT-SED-Synthetic-2016 for overlapping audio event detection.
SeqSleepNet: End-to-End Hierarchical Recurrent Neural Network for Sequence-to-Sequence Automatic Sleep Staging
Oct 01, 2018
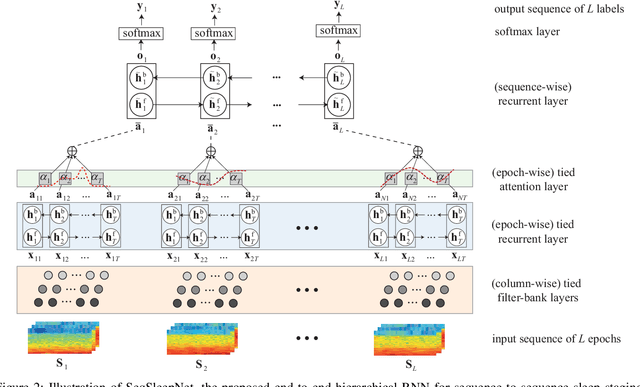
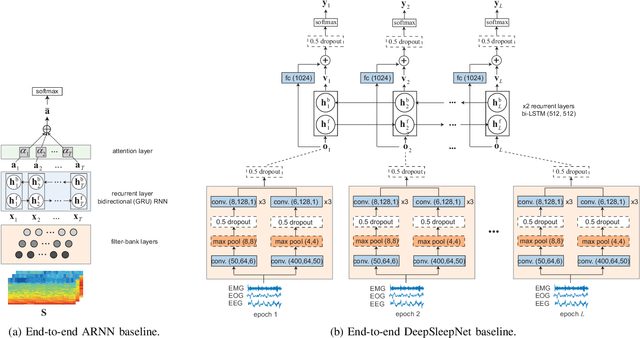
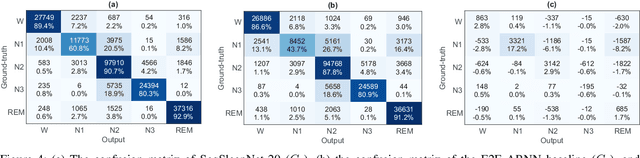
Automatic sleep staging has been often treated as a simple classification problem that aims at determining the label of individual target polysomnography (PSG) epochs one at a time. In this work, we tackle the task as a sequence-to-sequence classification problem that receives a sequence of multiple epochs as input and classifies all of their labels at once. For this purpose, we propose a hierarchical recurrent neural network named SeqSleepNet. The network epoch processing level consists of a filterbank layer tailored to learn frequency-domain filters for preprocessing and an attention-based recurrent layer designed for short-term sequential modelling. At the sequence processing level, a recurrent layer placed on top of the learned epoch-wise features for long-term modelling of sequential epochs. The classification is then carried out on the output vectors at every time step of the top recurrent layer to produce the sequence of output labels. Despite being hierarchical, we present a strategy to train the network in an end-to-end fashion. We show that the proposed network outperforms state-of-the-art approaches, achieving an overall accuracy, macro F1-score, and Cohen's kappa of 87.1%, 83.3%, and 0.815 on a publicly available dataset with 200 subjects.
A unifying Bayesian approach for preterm brain-age prediction that models EEG sleep transitions over age
Sep 19, 2018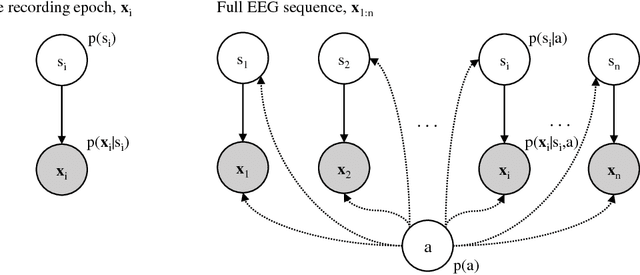
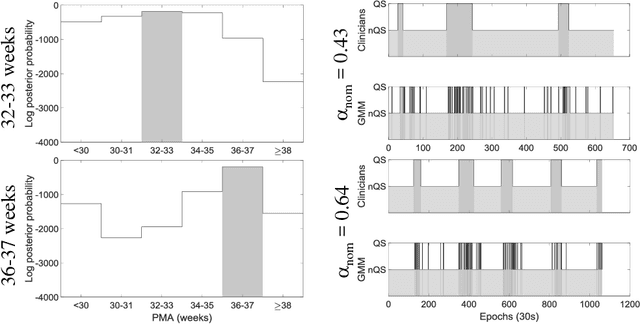
Preterm newborns undergo various stresses that may materialize as learning problems at school-age. Sleep staging of the Electroencephalogram (EEG), followed by prediction of their brain-age from these sleep states can quantify deviations from normal brain development early (when compared to the known age). Current automation of this approach relies on explicit sleep state classification, optimizing algorithms using clinician visually labelled sleep stages, which remains a subjective gold-standard. Such models fail to perform consistently over a wide age range and impacts the subsequent brain-age estimates that could prevent identification of subtler developmental deviations. We introduce a Bayesian Network utilizing multiple Gaussian Mixture Models, as a novel, unified approach for directly estimating brain-age, simultaneously modelling for both age and sleep dependencies on the EEG, to improve the accuracy of prediction over a wider age range.
Joint Classification and Prediction CNN Framework for Automatic Sleep Stage Classification
Sep 04, 2018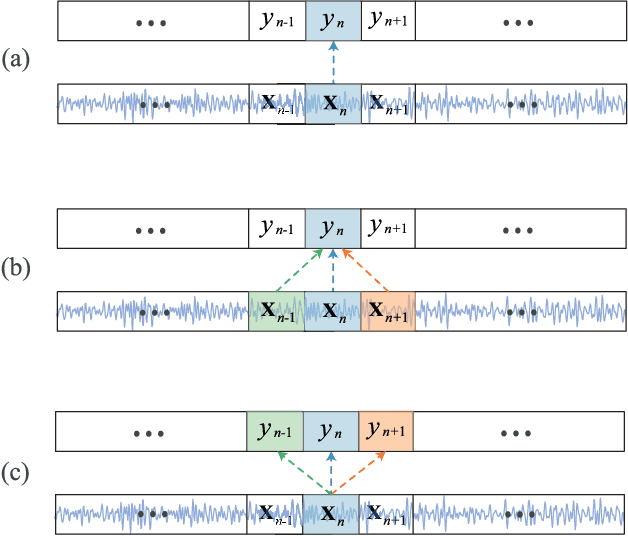
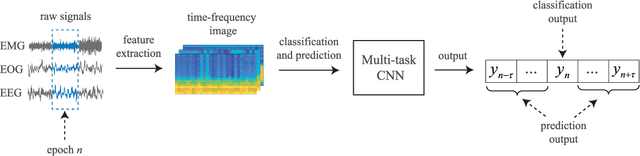
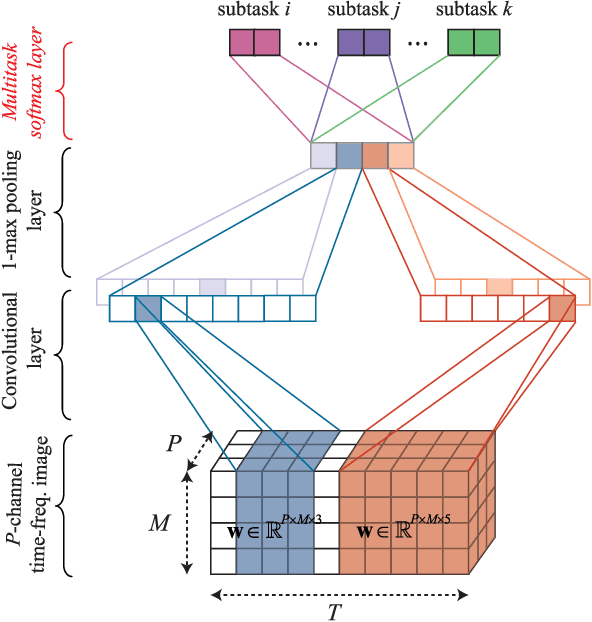
Correctly identifying sleep stages is important in diagnosing and treating sleep disorders. This work proposes a joint classification-and-prediction framework based on CNNs for automatic sleep staging, and, subsequently, introduces a simple yet efficient CNN architecture to power the framework. Given a single input epoch, the novel framework jointly determines its label (classification) and its neighboring epochs' labels (prediction) in the contextual output. While the proposed framework is orthogonal to the widely adopted classification schemes, which take one or multiple epochs as contextual inputs and produce a single classification decision on the target epoch, we demonstrate its advantages in several ways. First, it leverages the dependency among consecutive sleep epochs while surpassing the problems experienced with the common classification schemes. Second, even with a single model, the framework has the capacity to produce multiple decisions, which are essential in obtaining a good performance as in ensemble-of-models methods, with very little induced computational overhead. Probabilistic aggregation techniques are then proposed to leverage the availability of multiple decisions. We conducted experiments on two public datasets: Sleep-EDF Expanded with 20 subjects, and Montreal Archive of Sleep Studies dataset with 200 subjects. The proposed framework yields an overall classification accuracy of 82.3% and 83.6%, respectively. We also show that the proposed framework not only is superior to the baselines based on the common classification schemes but also outperforms existing deep-learning approaches. To our knowledge, this is the first work going beyond the standard single-output classification to consider multitask neural networks for automatic sleep staging. This framework provides avenues for further studies of different neural-network architectures for automatic sleep staging.
Compressed Sensing of Multi-Channel EEG Signals: The Simultaneous Cosparsity and Low Rank Optimization
Jun 29, 2015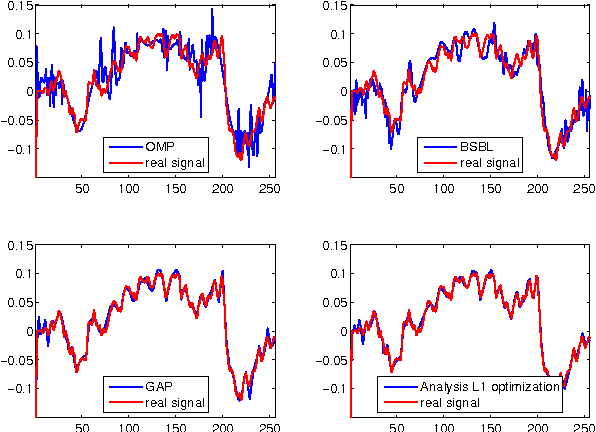
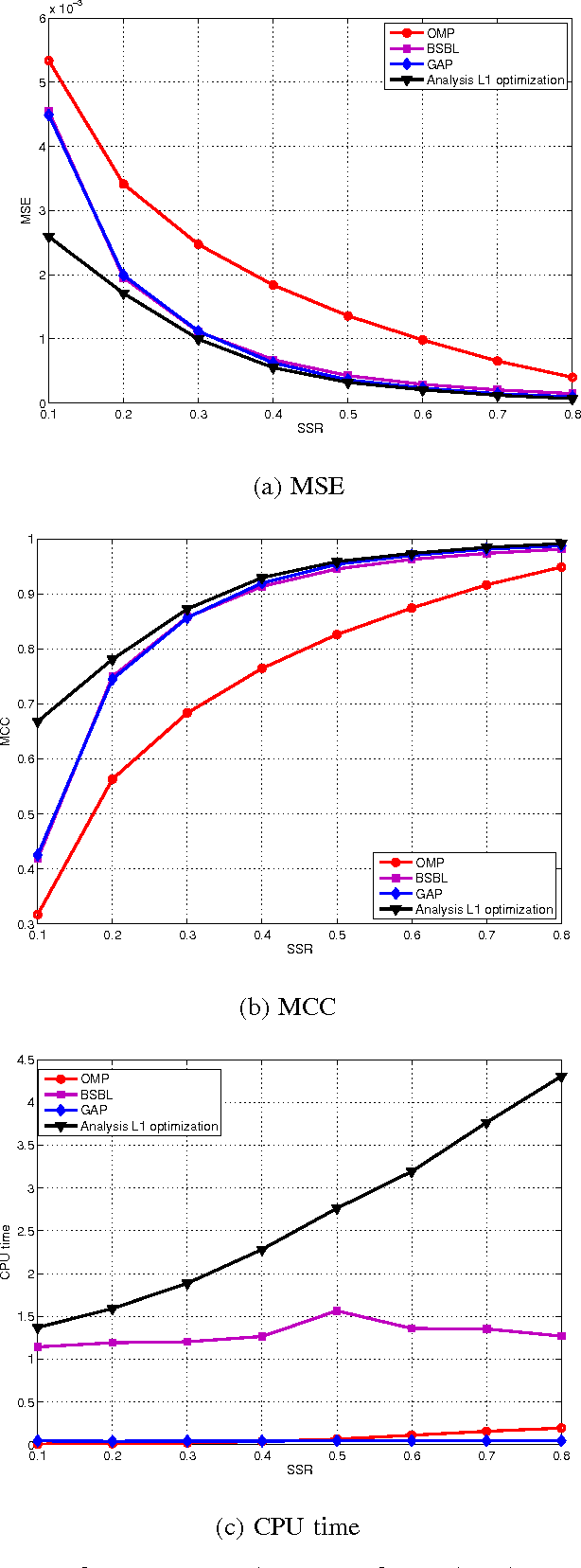
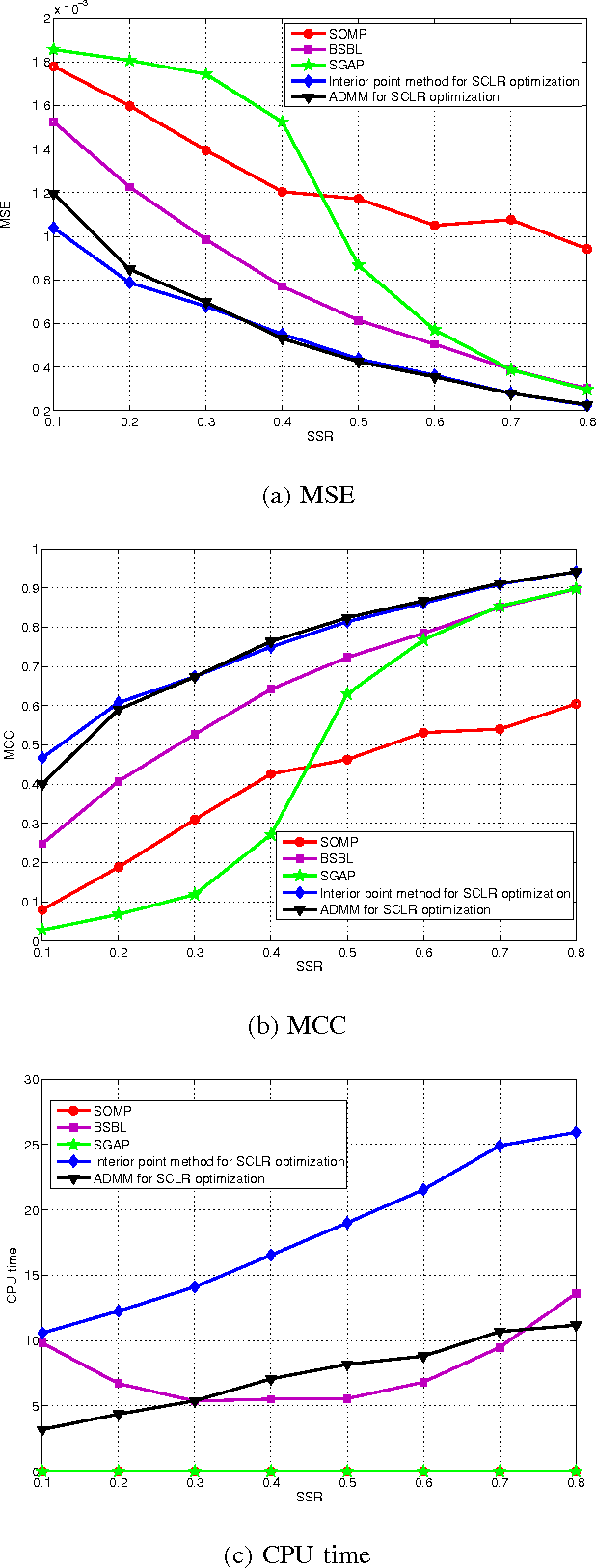
Goal: This paper deals with the problems that some EEG signals have no good sparse representation and single channel processing is not computationally efficient in compressed sensing of multi-channel EEG signals. Methods: An optimization model with L0 norm and Schatten-0 norm is proposed to enforce cosparsity and low rank structures in the reconstructed multi-channel EEG signals. Both convex relaxation and global consensus optimization with alternating direction method of multipliers are used to compute the optimization model. Results: The performance of multi-channel EEG signal reconstruction is improved in term of both accuracy and computational complexity. Conclusion: The proposed method is a better candidate than previous sparse signal recovery methods for compressed sensing of EEG signals. Significance: The proposed method enables successful compressed sensing of EEG signals even when the signals have no good sparse representation. Using compressed sensing would much reduce the power consumption of wireless EEG system.