 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Entropy-based Active Learning for Fair Brain Segmentation
May 03, 2026Active learning (AL) has emerged as a crucial strategy for reducing the prohibitive costs associated with medical image segmentation. However, standard uncertainty-based AL methods typically focus on maximizing performance metrics, ignoring performance disparities or fairness across groups with sensitive attributes. While fair active learning has been explored in classification tasks, its intersection with medical image segmentation remains unaddressed. In this work, we introduced a fairness-aware active learning framework with a Weighted Entropy selection strategy that modulates uncertainty based on current group-specific performance estimates on the labeled set. To decouple true epistemic uncertainty from anatomical volume variances, we further utilized a masked, scaled entropy restricted to the region of interest. The framework was evaluated on synthetic T1-weighted brain MRIs with controlled left caudate bias in both strong and weak bias settings. A 3D U-Net was trained to segment the left caudate under several AL strategies, starting from both demographically balanced and strongly imbalanced initial labeled sets. Experiments demonstrated that our method markedly reduces performance disparities between groups compared to random sampling and standard uncertainty sampling. By prioritizing poorly segmented subgroups during the AL cycles, our method consistently achieved the highest equity-scaled performance and reduced the disparity metric by 75% (strong bias) and 86% (weak bias) relative to standard entropy at the final budget. Overall, this work is among the first studies on fair AL for medical image segmentation, offering an efficient strategy to train more equitable models in resource-constrained environments.
Anatomically-aware conformal prediction for medical image segmentation with random walks
Jan 26, 2026The reliable deployment of deep learning in medical imaging requires uncertainty quantification that provides rigorous error guarantees while remaining anatomically meaningful. Conformal prediction (CP) is a powerful distribution-free framework for constructing statistically valid prediction intervals. However, standard applications in segmentation often ignore anatomical context, resulting in fragmented, spatially incoherent, and over-segmented prediction sets that limit clinical utility. To bridge this gap, this paper proposes Random-Walk Conformal Prediction (RW-CP), a model-agnostic framework which can be added on top of any segmentation method. RW-CP enforces spatial coherence to generate anatomically valid sets. Our method constructs a k-nearest neighbour graph from pre-trained vision foundation model features and applies a random walk to diffuse uncertainty. The random walk diffusion regularizes the non-conformity scores, making the prediction sets less sensitive to the conformal calibration parameter $λ$, ensuring more stable and continuous anatomical boundaries. RW-CP maintains rigorous marginal coverage while significantly improving segmentation quality. Evaluations on multi-modal public datasets show improvements of up to $35.4\%$ compared to standard CP baselines, given an allowable error rate of $α=0.1$.
Prompt learning with bounding box constraints for medical image segmentation
Jul 03, 2025Pixel-wise annotations are notoriously labourious and costly to obtain in the medical domain. To mitigate this burden, weakly supervised approaches based on bounding box annotations-much easier to acquire-offer a practical alternative. Vision foundation models have recently shown noteworthy segmentation performance when provided with prompts such as points or bounding boxes. Prompt learning exploits these models by adapting them to downstream tasks and automating segmentation, thereby reducing user intervention. However, existing prompt learning approaches depend on fully annotated segmentation masks. This paper proposes a novel framework that combines the representational power of foundation models with the annotation efficiency of weakly supervised segmentation. More specifically, our approach automates prompt generation for foundation models using only bounding box annotations. Our proposed optimization scheme integrates multiple constraints derived from box annotations with pseudo-labels generated by the prompted foundation model. Extensive experiments across multimodal datasets reveal that our weakly supervised method achieves an average Dice score of 84.90% in a limited data setting, outperforming existing fully-supervised and weakly-supervised approaches. The code is available at https://github.com/Minimel/box-prompt-learning-VFM.git
Automating MedSAM by Learning Prompts with Weak Few-Shot Supervision
Sep 30, 2024Foundation models such as the recently introduced Segment Anything Model (SAM) have achieved remarkable results in image segmentation tasks. However, these models typically require user interaction through handcrafted prompts such as bounding boxes, which limits their deployment to downstream tasks. Adapting these models to a specific task with fully labeled data also demands expensive prior user interaction to obtain ground-truth annotations. This work proposes to replace conditioning on input prompts with a lightweight module that directly learns a prompt embedding from the image embedding, both of which are subsequently used by the foundation model to output a segmentation mask. Our foundation models with learnable prompts can automatically segment any specific region by 1) modifying the input through a prompt embedding predicted by a simple module, and 2) using weak labels (tight bounding boxes) and few-shot supervision (10 samples). Our approach is validated on MedSAM, a version of SAM fine-tuned for medical images, with results on three medical datasets in MR and ultrasound imaging. Our code is available on https://github.com/Minimel/MedSAMWeakFewShotPromptAutomation.
Active learning for medical image segmentation with stochastic batches
Jan 18, 2023



The performance of learning-based algorithms improves with the amount of labelled data used for training. Yet, manually annotating data can be tedious and expensive, especially in medical image segmentation. To reduce manual labelling, active learning (AL) targets the most informative samples from the unlabelled set to annotate and add to the labelled training set. On one hand, most active learning works have focused on the classification or limited segmentation of natural images, despite active learning being highly desirable in the difficult task of medical image segmentation. On the other hand, uncertainty-based AL approaches notoriously offer sub-optimal batch-query strategies, while diversity-based methods tend to be computationally expensive. Over and above methodological hurdles, random sampling has proven an extremely difficult baseline to outperform when varying learning and sampling conditions. This work aims to take advantage of the diversity and speed offered by random sampling to improve the selection of uncertainty-based AL methods for segmenting medical images. More specifically, we propose to compute uncertainty at the level of batches instead of samples through an original use of stochastic batches during sampling in AL. Exhaustive experiments on medical image segmentation, with an illustration on MRI prostate imaging, show that the benefits of stochastic batches during sample selection are robust to a variety of changes in the training and sampling procedures.
TAAL: Test-time Augmentation for Active Learning in Medical Image Segmentation
Jan 16, 2023Deep learning methods typically depend on the availability of labeled data, which is expensive and time-consuming to obtain. Active learning addresses such effort by prioritizing which samples are best to annotate in order to maximize the performance of the task model. While frameworks for active learning have been widely explored in the context of classification of natural images, they have been only sparsely used in medical image segmentation. The challenge resides in obtaining an uncertainty measure that reveals the best candidate data for annotation. This paper proposes Test-time Augmentation for Active Learning (TAAL), a novel semi-supervised active learning approach for segmentation that exploits the uncertainty information offered by data transformations. Our method applies cross-augmentation consistency during training and inference to both improve model learning in a semi-supervised fashion and identify the most relevant unlabeled samples to annotate next. In addition, our consistency loss uses a modified version of the JSD to further improve model performance. By relying on data transformations rather than on external modules or simple heuristics typically used in uncertainty-based strategies, TAAL emerges as a simple, yet powerful task-agnostic semi-supervised active learning approach applicable to the medical domain. Our results on a publicly-available dataset of cardiac images show that TAAL outperforms existing baseline methods in both fully-supervised and semi-supervised settings. Our implementation is publicly available on https://github.com/melinphd/TAAL.
Joint reconstruction and bias field correction for undersampled MR imaging
Jul 26, 2020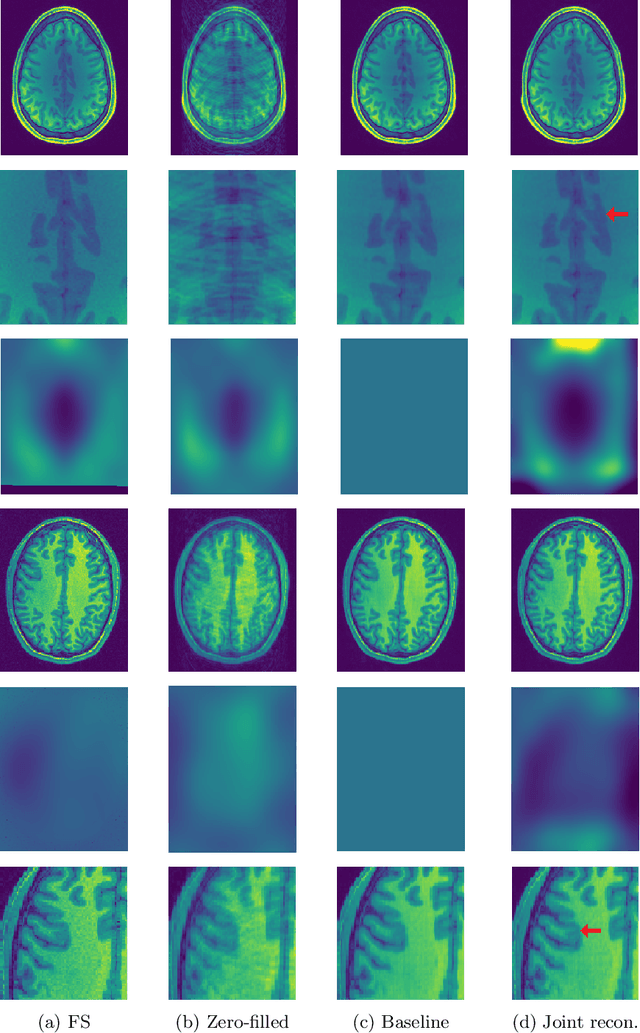
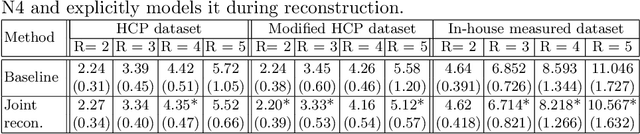
Undersampling the k-space in MRI allows saving precious acquisition time, yet results in an ill-posed inversion problem. Recently, many deep learning techniques have been developed, addressing this issue of recovering the fully sampled MR image from the undersampled data. However, these learning based schemes are susceptible to differences between the training data and the image to be reconstructed at test time. One such difference can be attributed to the bias field present in MR images, caused by field inhomogeneities and coil sensitivities. In this work, we address the sensitivity of the reconstruction problem to the bias field and propose to model it explicitly in the reconstruction, in order to decrease this sensitivity. To this end, we use an unsupervised learning based reconstruction algorithm as our basis and combine it with a N4-based bias field estimation method, in a joint optimization scheme. We use the HCP dataset as well as in-house measured images for the evaluations. We show that the proposed method improves the reconstruction quality, both visually and in terms of RMSE.