 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Causal Discovery Through the Lens of Exchangeability
Dec 10, 2025Causal discovery methods have traditionally been developed under two distinct regimes: independent and identically distributed (i.i.d.) and timeseries data, each governed by separate modelling assumptions. In this paper, we argue that the i.i.d. setting can and should be reframed in terms of exchangeability, a strictly more general symmetry principle. We present the implications of this reframing, alongside two core arguments: (1) a conceptual argument, based on extending the dependency of experimental causal inference on exchangeability to causal discovery; and (2) an empirical argument, showing that many existing i.i.d. causal-discovery methods are predicated on exchangeability assumptions, and that the sole extensive widely-used real-world "i.i.d." benchmark (the Tübingen dataset) consists mainly of exchangeable (and not i.i.d.) examples. Building on this insight, we introduce a novel synthetic dataset that enforces only the exchangeability assumption, without imposing the stronger i.i.d. assumption. We show that our exchangeable synthetic dataset mirrors the statistical structure of the real-world "i.i.d." dataset more closely than all other i.i.d. synthetic datasets. Furthermore, we demonstrate the predictive capability of this dataset by proposing a neural-network-based causal-discovery algorithm trained exclusively on our synthetic dataset, and which performs similarly to other state-of-the-art i.i.d. methods on the real-world benchmark.
DeepThought: An Architecture for Autonomous Self-motivated Systems
Nov 14, 2023The ability of large language models (LLMs) to engage in credible dialogues with humans, taking into account the training data and the context of the conversation, has raised discussions about their ability to exhibit intrinsic motivations, agency, or even some degree of consciousness. We argue that the internal architecture of LLMs and their finite and volatile state cannot support any of these properties. By combining insights from complementary learning systems, global neuronal workspace, and attention schema theories, we propose to integrate LLMs and other deep learning systems into an architecture for cognitive language agents able to exhibit properties akin to agency, self-motivation, even some features of meta-cognition.
Single-partition adaptive Q-learning
Jul 14, 2020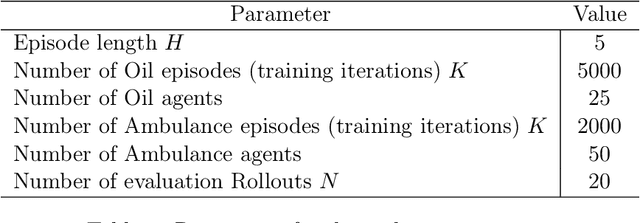
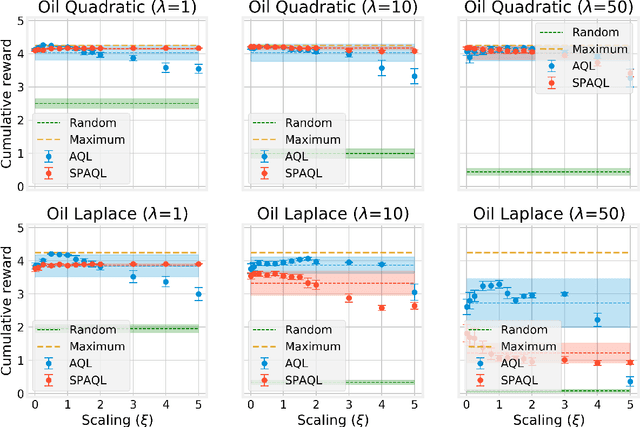
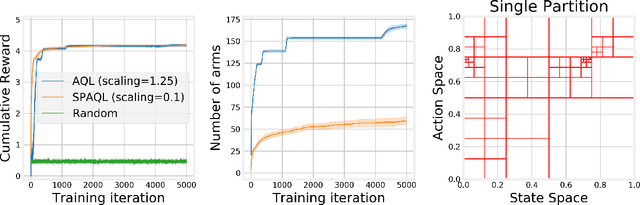
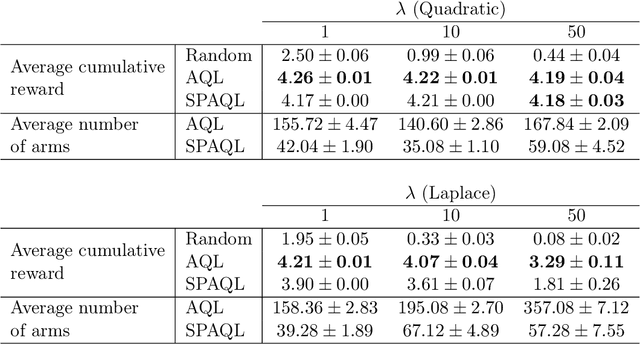
This paper introduces single-partition adaptive Q-learning (SPAQL), an algorithm for model-free episodic reinforcement learning (RL), which adaptively partitions the state-action space of a Markov decision process (MDP), while simultaneously learning a time-invariant policy (i. e., the mapping from states to actions does not depend explicitly on the episode time step) for maximizing the cumulative reward. The trade-off between exploration and exploitation is handled by using a mixture of upper confidence bounds (UCB) and Boltzmann exploration during training, with a temperature parameter that is automatically tuned as training progresses. The algorithm is an improvement over adaptive Q-learning (AQL). It converges faster to the optimal solution, while also using fewer arms. Tests on episodes with a large number of time steps show that SPAQL has no problems scaling, unlike AQL. Based on this empirical evidence, we claim that SPAQL may have a higher sample efficiency than AQL, thus being a relevant contribution to the field of efficient model-free RL methods.
Restoring STM images via Sparse Coding: noise and artifact removal
Oct 11, 2016

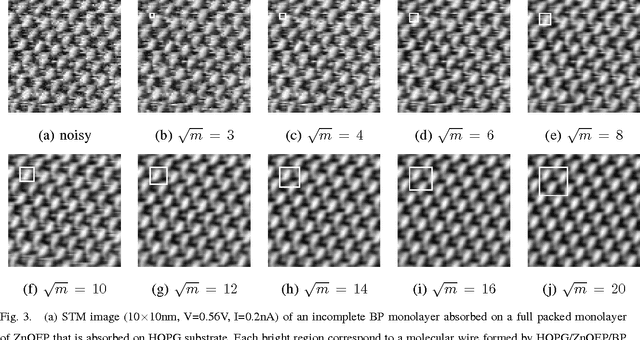
In this article, we present a denoising algorithm to improve the interpretation and quality of scanning tunneling microscopy (STM) images. Given the high level of self-similarity of STM images, we propose a denoising algorithm by reformulating the true estimation problem as a sparse regression, often termed sparse coding. We introduce modifications to the algorithm to cope with the existence of artifacts, mainly dropouts, which appear in a structured way as consecutive line segments on the scanning direction. The resulting algorithm treats the artifacts as missing data, and the estimated values outperform those algorithms that substitute the outliers by a local filtering. We provide code implementations for both Matlab and Gwyddion.