 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCoDrift: Stabilizing Decoder Coupling in Closed-Loop Foundation Segmentation
May 25, 2026Foundation segmentation models such as Segment Anything Model (SAM) are now routinely used in iterative pipelines, where each predicted mask is fed back as the next prompt. This practice turns segmentation into a closed-loop dynamical process, yet the decoder-level behavior of these systems remains largely unexamined. We show that this feedback loop can induce a previously overlooked failure mode, decoder coupling drift, in which the mask decoder's cross-attention progressively loses alignment with the target object, causing errors to accumulate across iterations. We study this phenomenon by instrumenting SAM's mask decoder and deriving ground-truth-free measures of prompt-image coupling, attention stability, and temporal consistency. On volumetric electron microscopy data, these decoder-internal signals reveal that standard iterative prompting systematically degrades attention alignment and temporal coherence relative to oracle-anchored feedback. We then formalize iterative prompting as a discrete-time dynamical system and show how proximal anchoring reduces error amplification in the feedback loop. Building on this analysis, we introduce DeCoDrift, a training-free inference-time stabilization framework that constrains prompt updates and preserves decoder coupling across iterations. Across extensive experiments, DeCoDrift consistently improves attention stability, temporal coherence, and segmentation quality over standard iterative prompting, without retraining or ground-truth supervision. More broadly, our results show that decoder-internal dynamics are not merely diagnostic: they provide actionable signals for stabilizing foundation segmentation models in closed-loop use.
Patient Similarity Computation for Clinical Decision Support: An Efficient Use of Data Transformation, Combining Static and Time Series Data
Jun 08, 2025Patient similarity computation (PSC) is a fundamental problem in healthcare informatics. The aim of the patient similarity computation is to measure the similarity among patients according to their historical clinical records, which helps to improve clinical decision support. This paper presents a novel distributed patient similarity computation (DPSC) technique based on data transformation (DT) methods, utilizing an effective combination of time series and static data. Time series data are sensor-collected patients' information, including metrics like heart rate, blood pressure, Oxygen saturation, respiration, etc. The static data are mainly patient background and demographic data, including age, weight, height, gender, etc. Static data has been used for clustering the patients. Before feeding the static data to the machine learning model adaptive Weight-of-Evidence (aWOE) and Z-score data transformation (DT) methods have been performed, which improve the prediction performances. In aWOE-based patient similarity models, sensitive patient information has been processed using aWOE which preserves the data privacy of the trained models. We used the Dynamic Time Warping (DTW) approach, which is robust and very popular, for time series similarity. However, DTW is not suitable for big data due to the significant computational run-time. To overcome this problem, distributed DTW computation is used in this study. For Coronary Artery Disease, our DT based approach boosts prediction performance by as much as 11.4%, 10.20%, and 12.6% in terms of AUC, accuracy, and F-measure, respectively. In the case of Congestive Heart Failure (CHF), our proposed method achieves performance enhancement up to 15.9%, 10.5%, and 21.9% for the same measures, respectively. The proposed method reduces the computation time by as high as 40%.
Privacy-Preserving Customer Churn Prediction Model in the Context of Telecommunication Industry
Nov 03, 2024Data is the main fuel of a successful machine learning model. A dataset may contain sensitive individual records e.g. personal health records, financial data, industrial information, etc. Training a model using this sensitive data has become a new privacy concern when someone uses third-party cloud computing. Trained models also suffer privacy attacks which leads to the leaking of sensitive information of the training data. This study is conducted to preserve the privacy of training data in the context of customer churn prediction modeling for the telecommunications industry (TCI). In this work, we propose a framework for privacy-preserving customer churn prediction (PPCCP) model in the cloud environment. We have proposed a novel approach which is a combination of Generative Adversarial Networks (GANs) and adaptive Weight-of-Evidence (aWOE). Synthetic data is generated from GANs, and aWOE is applied on the synthetic training dataset before feeding the data to the classification algorithms. Our experiments were carried out using eight different machine learning (ML) classifiers on three openly accessible datasets from the telecommunication sector. We then evaluated the performance using six commonly employed evaluation metrics. In addition to presenting a data privacy analysis, we also performed a statistical significance test. The training and prediction processes achieve data privacy and the prediction classifiers achieve high prediction performance (87.1\% in terms of F-Measure for GANs-aWOE based Na\"{\i}ve Bayes model). In contrast to earlier studies, our suggested approach demonstrates a prediction enhancement of up to 28.9\% and 27.9\% in terms of accuracy and F-measure, respectively.
Neural Network Based Undersampling Techniques
Aug 18, 2019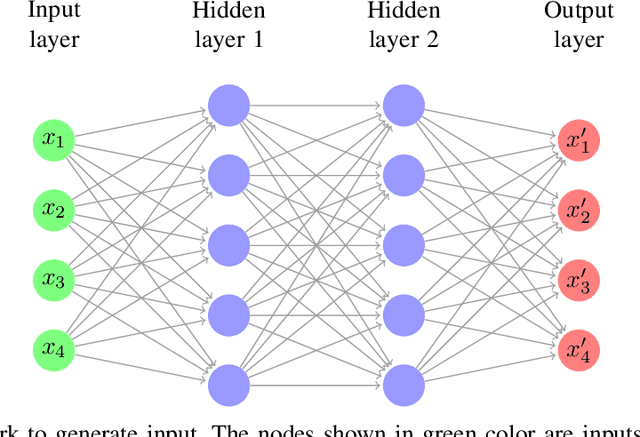
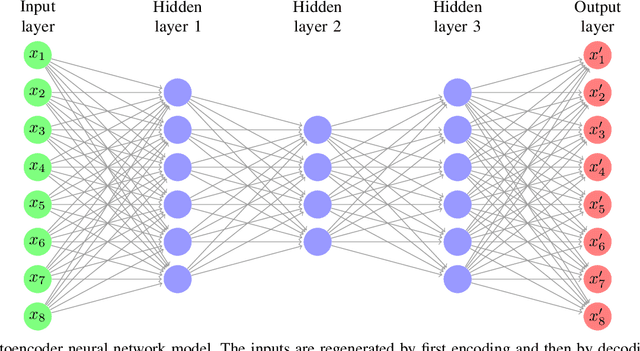
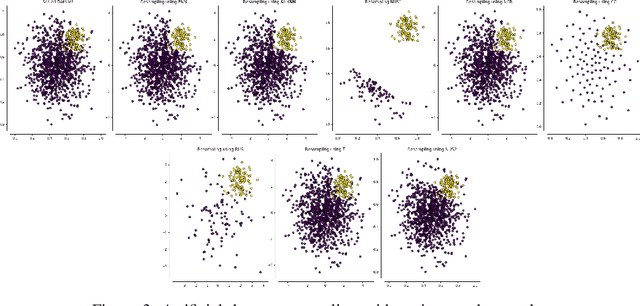
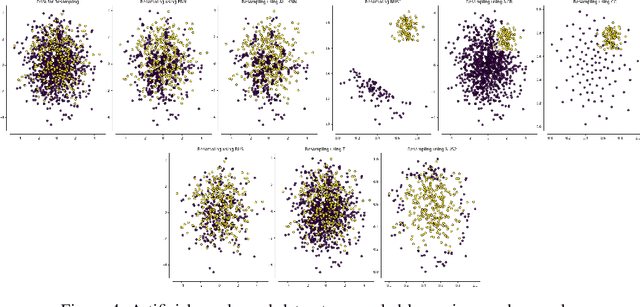
Class imbalance problem is commonly faced while developing machine learning models for real-life issues. Due to this problem, the fitted model tends to be biased towards the majority class data, which leads to lower precision, recall, AUC, F1, G-mean score. Several researches have been done to tackle this problem, most of which employed resampling, i.e. oversampling and undersampling techniques to bring the required balance in the data. In this paper, we propose neural network based algorithms for undersampling. Then we resampled several class imbalanced data using our algorithms and also some other popular resampling techniques. Afterwards we classified these undersampled data using some common classifier. We found out that our resampling approaches outperform most other resampling techniques in terms of both AUC, F1 and G-mean score.
Improving Malaria Parasite Detection from Red Blood Cell using Deep Convolutional Neural Networks
Jul 23, 2019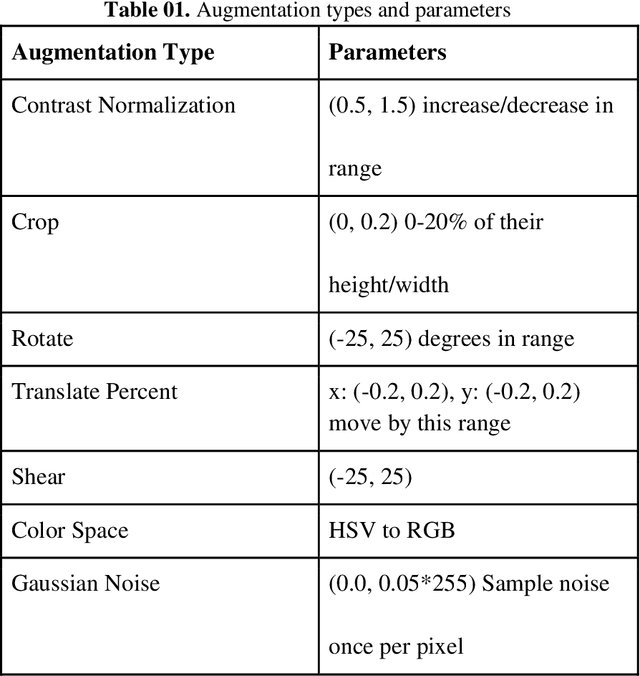
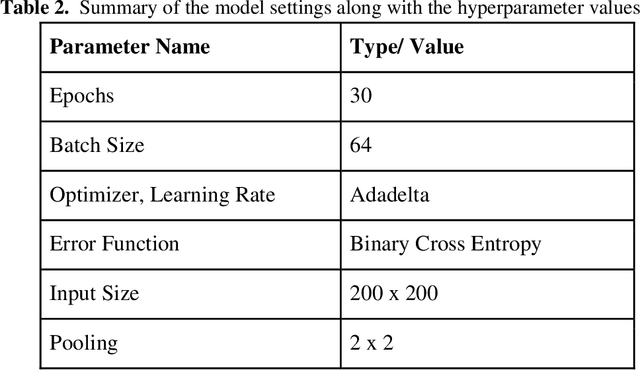
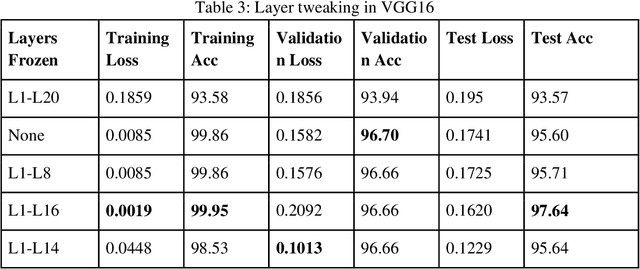
Malaria is a female anopheles mosquito-bite inflicted life-threatening disease which is considered endemic in many parts of the world. This article focuses on improving malaria detection from patches segmented from microscopic images of red blood cell smears by introducing a deep convolutional neural network. Compared to the traditional methods that use tedious hand engineering feature extraction, the proposed method uses deep learning in an end-to-end arrangement that performs both feature extraction and classification directly from the raw segmented patches of the red blood smears. The dataset used in this study was taken from National Institute of Health named NIH Malaria Dataset. The evaluation metric accuracy and loss along with 5-fold cross validation was used to compare and select the best performing architecture. To maximize the performance, existing standard pre-processing techniques from the literature has also been experimented. In addition, several other complex architectures have been implemented and tested to pick the best performing model. A holdout test has also been conducted to verify how well the proposed model generalizes on unseen data. Our best model achieves an accuracy of almost 97.77%.
FGPGA: An Efficient Genetic Approach for Producing Feasible Graph Partitions
Nov 17, 2014

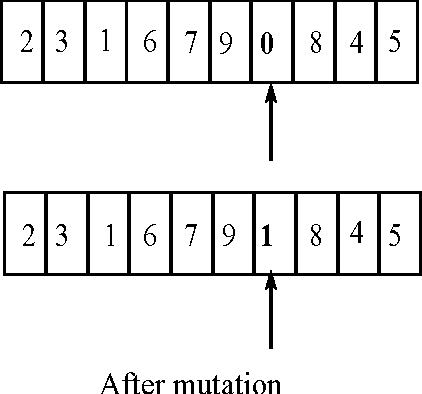
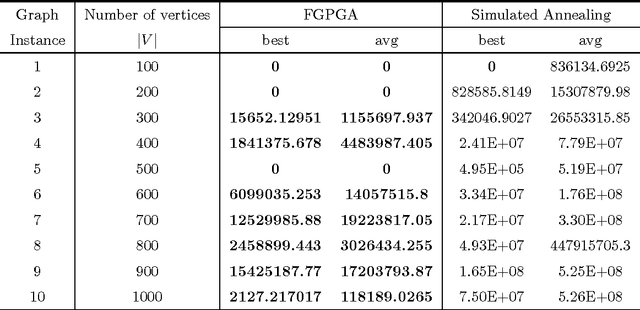
Graph partitioning, a well studied problem of parallel computing has many applications in diversified fields such as distributed computing, social network analysis, data mining and many other domains. In this paper, we introduce FGPGA, an efficient genetic approach for producing feasible graph partitions. Our method takes into account the heterogeneity and capacity constraints of the partitions to ensure balanced partitioning. Such approach has various applications in mobile cloud computing that include feasible deployment of software applications on the more resourceful infrastructure in the cloud instead of mobile hand set. Our proposed approach is light weight and hence suitable for use in cloud architecture. We ensure feasibility of the partitions generated by not allowing over-sized partitions to be generated during the initialization and search. Our proposed method tested on standard benchmark datasets significantly outperforms the state-of-the-art methods in terms of quality of partitions and feasibility of the solutions.