 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference
Apr 09, 2026Video streaming analytics is a crucial workload for vision-language model serving, but the high cost of multimodal inference limits scalability. Prior systems reduce inference cost by exploiting temporal and spatial redundancy in video streams, but they target either the vision transformer (ViT) or the LLM with a limited view, leaving end-to-end opportunities untapped. Moreover, existing methods incur significant overhead to identify redundancy, either through offline profiling and training or costly online computation, making them ill-suited for dynamic real-time streams. We present CodecSight, a codec-guided streaming video analytics system, built on a key observation that video codecs already extract the temporal and spatial structure of each stream as a byproduct of compression. CodecSight treats this codec metadata as a low-cost runtime signal to unify optimization across video decoding, visual processing, and LLM prefilling, with transmission reduction as an inherent benefit of operating directly on compressed bitstreams. This drives codec-guided patch pruning before ViT encoding and selective key-value cache refresh during LLM prefilling, both of which are fully online and do not require offline training. Experiments show that CodecSight achieves an improvement in throughput of up to 3$\times$, and a reduction of up to 87% in GPU compute over state-of-the-art baselines, maintaining competitive accuracy with only 0$\sim$8% F1 drop.
CoStream: Codec-Guided Resource-Efficient System for Video Streaming Analytics
Apr 07, 2026Video streaming analytics is a crucial workload for vision-language model serving, but the high cost of multimodal inference limits scalability. Prior systems reduce inference cost by exploiting temporal and spatial redundancy in video streams, but they target either the vision transformer (ViT) or the LLM with a limited view, leaving end-to-end opportunities untapped. Moreover, existing methods incur significant overhead to identify redundancy, either through offline profiling and training or costly online computation, making them ill-suited for dynamic real-time streams. We present CoStream, a codec-guided streaming video analytics system built on a key observation that video codecs already extract the temporal and spatial structure of each stream as a byproduct of compression. CoStream treats this codec metadata as a low-cost runtime signal to unify optimization across video decoding, visual processing, and LLM prefilling, with transmission reduction as an inherent benefit of operating directly on compressed bitstreams. This drives codec-guided patch pruning before ViT encoding and selective key-value cache refresh during LLM prefilling, both of which are fully online and do not require offline training. Experiments show that CoStream achieves up to 3x throughput improvement and up to 87% GPU compute reduction over state-of-the-art baselines, while maintaining competitive accuracy with only 0-8% F1 drop.
Applying the Roofline model for Deep Learning performance optimizations
Sep 23, 2020
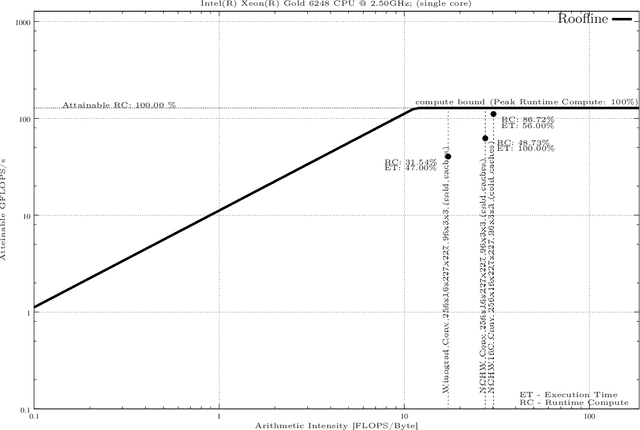
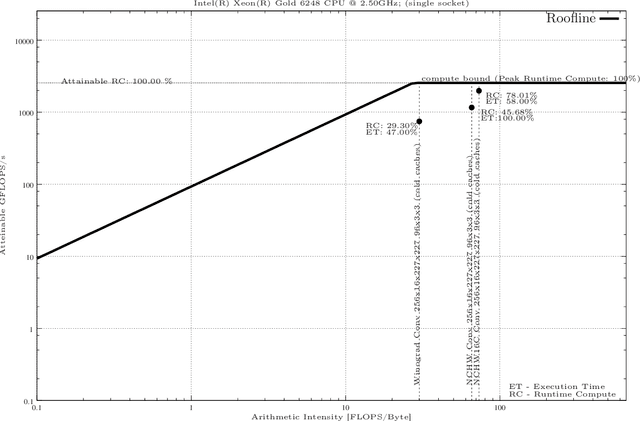
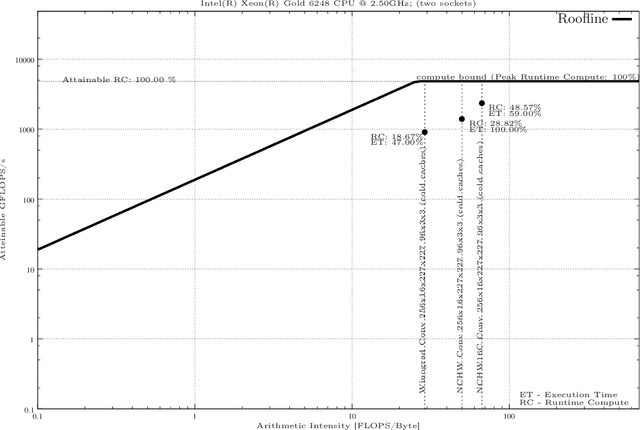
In this paper We present a methodology for creating Roofline models automatically for Non-Unified Memory Access (NUMA) using Intel Xeon as an example. Finally, we present an evaluation of highly efficient deep learning primitives as implemented in the Intel oneDNN Library.
An FPGA-based Parallel Architecture for Face Detection using Mixed Color Models
May 27, 2014

In this paper, a reliable method for detecting human faces in color images is proposed. This system firstly detects skin color in YCgCr and YIQ color space, then filters binary texture and the result is morphological processed, finally converts skin tone to the preferred skin color configured by users in YIQ color space. The real-time adjusting circuit is implemented and some of simulation results are given out. Experimental results demonstrate that the method has achieved high rates and low false positives, another advantage is its simplicity and minor computational costs.