 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference
Apr 09, 2026Video streaming analytics is a crucial workload for vision-language model serving, but the high cost of multimodal inference limits scalability. Prior systems reduce inference cost by exploiting temporal and spatial redundancy in video streams, but they target either the vision transformer (ViT) or the LLM with a limited view, leaving end-to-end opportunities untapped. Moreover, existing methods incur significant overhead to identify redundancy, either through offline profiling and training or costly online computation, making them ill-suited for dynamic real-time streams. We present CodecSight, a codec-guided streaming video analytics system, built on a key observation that video codecs already extract the temporal and spatial structure of each stream as a byproduct of compression. CodecSight treats this codec metadata as a low-cost runtime signal to unify optimization across video decoding, visual processing, and LLM prefilling, with transmission reduction as an inherent benefit of operating directly on compressed bitstreams. This drives codec-guided patch pruning before ViT encoding and selective key-value cache refresh during LLM prefilling, both of which are fully online and do not require offline training. Experiments show that CodecSight achieves an improvement in throughput of up to 3$\times$, and a reduction of up to 87% in GPU compute over state-of-the-art baselines, maintaining competitive accuracy with only 0$\sim$8% F1 drop.
CoStream: Codec-Guided Resource-Efficient System for Video Streaming Analytics
Apr 07, 2026Video streaming analytics is a crucial workload for vision-language model serving, but the high cost of multimodal inference limits scalability. Prior systems reduce inference cost by exploiting temporal and spatial redundancy in video streams, but they target either the vision transformer (ViT) or the LLM with a limited view, leaving end-to-end opportunities untapped. Moreover, existing methods incur significant overhead to identify redundancy, either through offline profiling and training or costly online computation, making them ill-suited for dynamic real-time streams. We present CoStream, a codec-guided streaming video analytics system built on a key observation that video codecs already extract the temporal and spatial structure of each stream as a byproduct of compression. CoStream treats this codec metadata as a low-cost runtime signal to unify optimization across video decoding, visual processing, and LLM prefilling, with transmission reduction as an inherent benefit of operating directly on compressed bitstreams. This drives codec-guided patch pruning before ViT encoding and selective key-value cache refresh during LLM prefilling, both of which are fully online and do not require offline training. Experiments show that CoStream achieves up to 3x throughput improvement and up to 87% GPU compute reduction over state-of-the-art baselines, while maintaining competitive accuracy with only 0-8% F1 drop.
Micro Batch Streaming: Allowing the Training of DNN models Using a large batch size on Small Memory Systems
Oct 24, 2021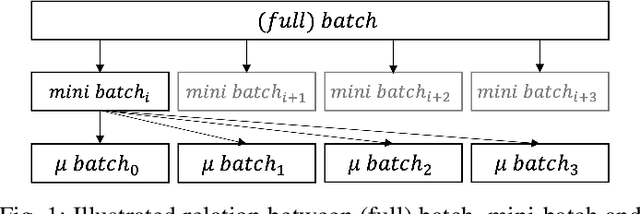
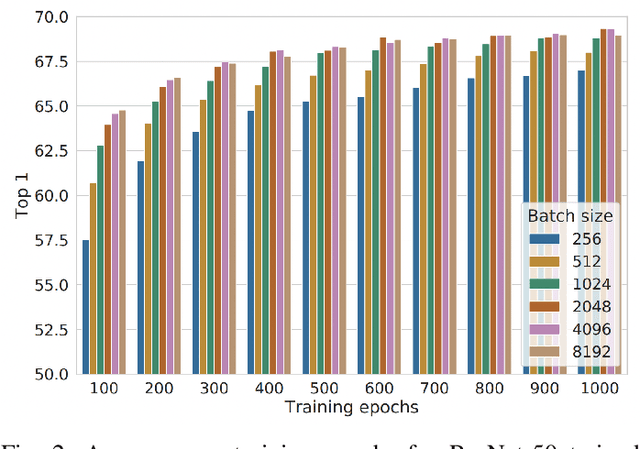
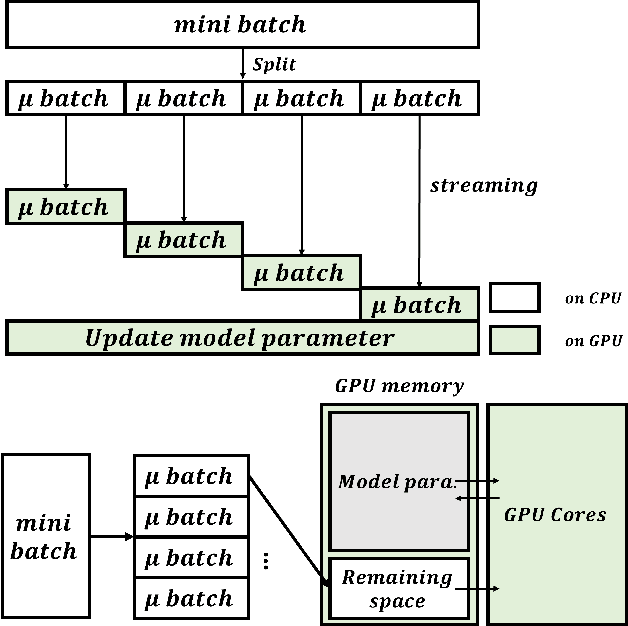
The size of the deep learning models has greatly increased over the past decade. Such models are difficult to train using a large batch size, because commodity machines do not have enough memory to accommodate both the model and a large data size. The batch size is one of the hyper-parameters used in the training model, and it is dependent on and is limited by the target machine memory capacity and it is dependent on the remaining memory after the model is uploaded. A smaller batch size usually results in performance degradation. This paper proposes a framework called Micro-Batch Streaming (MBS) to address this problem. This method helps deep learning models to train by providing a batch streaming algorithm that splits a batch into the appropriate size for the remaining memory size and streams them sequentially to the target machine. A loss normalization algorithm based on the gradient accumulation is used to maintain the performance. The purpose of our method is to allow deep learning models to train using mathematically determined optimal batch sizes that cannot fit into the memory of a target system.