 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-VQG: Generating Engaging Questions for Multiple Images
Nov 18, 2022



Generating engaging content has drawn much recent attention in the NLP community. Asking questions is a natural way to respond to photos and promote awareness. However, most answers to questions in traditional question-answering (QA) datasets are factoids, which reduce individuals' willingness to answer. Furthermore, traditional visual question generation (VQG) confines the source data for question generation to single images, resulting in a limited ability to comprehend time-series information of the underlying event. In this paper, we propose generating engaging questions from multiple images. We present MVQG, a new dataset, and establish a series of baselines, including both end-to-end and dual-stage architectures. Results show that building stories behind the image sequence enables models to generate engaging questions, which confirms our assumption that people typically construct a picture of the event in their minds before asking questions. These results open up an exciting challenge for visual-and-language models to implicitly construct a story behind a series of photos to allow for creativity and experience sharing and hence draw attention to downstream applications.
Ask to Know More: Generating Counterfactual Explanations for Fake Claims
Jun 14, 2022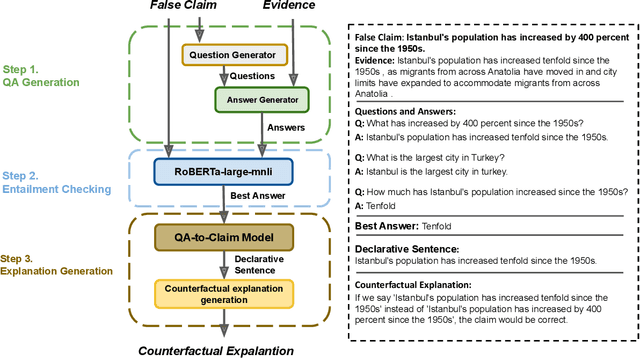
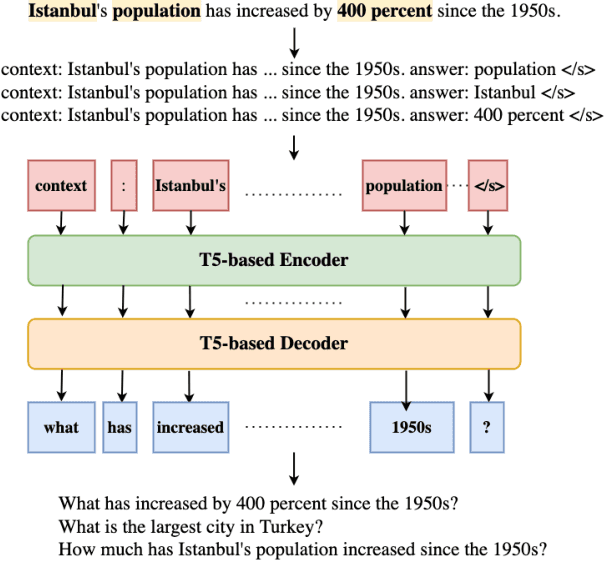
Automated fact checking systems have been proposed that quickly provide veracity prediction at scale to mitigate the negative influence of fake news on people and on public opinion. However, most studies focus on veracity classifiers of those systems, which merely predict the truthfulness of news articles. We posit that effective fact checking also relies on people's understanding of the predictions. In this paper, we propose elucidating fact checking predictions using counterfactual explanations to help people understand why a specific piece of news was identified as fake. In this work, generating counterfactual explanations for fake news involves three steps: asking good questions, finding contradictions, and reasoning appropriately. We frame this research question as contradicted entailment reasoning through question answering (QA). We first ask questions towards the false claim and retrieve potential answers from the relevant evidence documents. Then, we identify the most contradictory answer to the false claim by use of an entailment classifier. Finally, a counterfactual explanation is created using a matched QA pair with three different counterfactual explanation forms. Experiments are conducted on the FEVER dataset for both system and human evaluations. Results suggest that the proposed approach generates the most helpful explanations compared to state-of-the-art methods.
Let's Talk! Striking Up Conversations via Conversational Visual Question Generation
May 19, 2022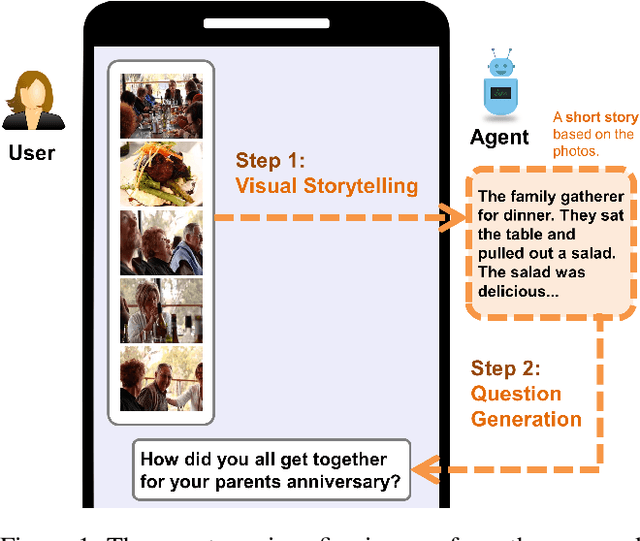

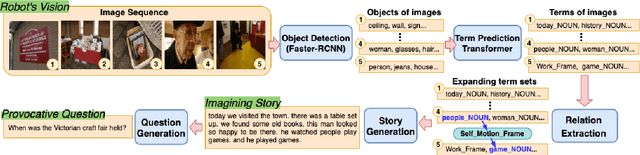

An engaging and provocative question can open up a great conversation. In this work, we explore a novel scenario: a conversation agent views a set of the user's photos (for example, from social media platforms) and asks an engaging question to initiate a conversation with the user. The existing vision-to-question models mostly generate tedious and obvious questions, which might not be ideals conversation starters. This paper introduces a two-phase framework that first generates a visual story for the photo set and then uses the story to produce an interesting question. The human evaluation shows that our framework generates more response-provoking questions for starting conversations than other vision-to-question baselines.
Hyperbolic Disentangled Representation for Fine-Grained Aspect Extraction
Dec 16, 2021
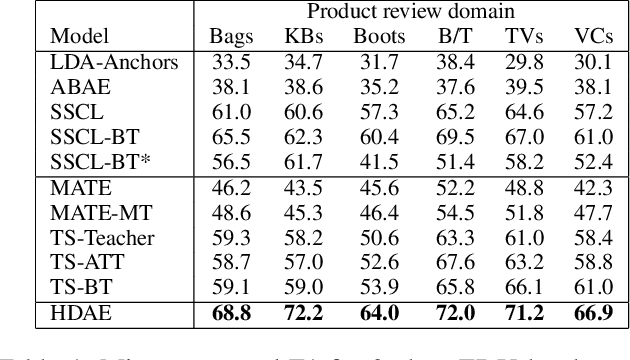
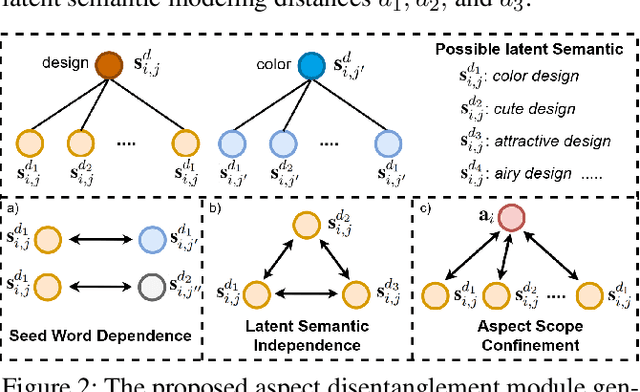
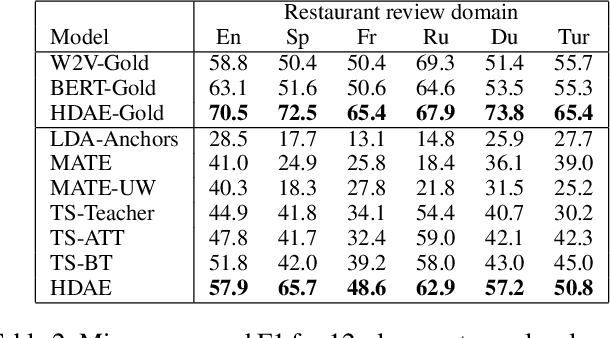
Automatic identification of salient aspects from user reviews is especially useful for opinion analysis. There has been significant progress in utilizing weakly supervised approaches, which require only a small set of seed words for training aspect classifiers. However, there is always room for improvement. First, no weakly supervised approaches fully utilize latent hierarchies between words. Second, each seed words representation should have different latent semantics and be distinct when it represents a different aspect. In this paper, we propose HDAE, a hyperbolic disentangled aspect extractor in which a hyperbolic aspect classifier captures words latent hierarchies, and aspect-disentangled representation models the distinct latent semantics of each seed word. Compared to previous baselines, HDAE achieves average F1 performance gains of 18.2% and 24.1% on Amazon product review and restaurant review datasets, respectively. In addition, the em-bedding visualization experience demonstrates that HDAE is a more effective approach to leveraging seed words. An ablation study and a case study further attest to the effectiveness of the proposed components
Plot and Rework: Modeling Storylines for Visual Storytelling
May 23, 2021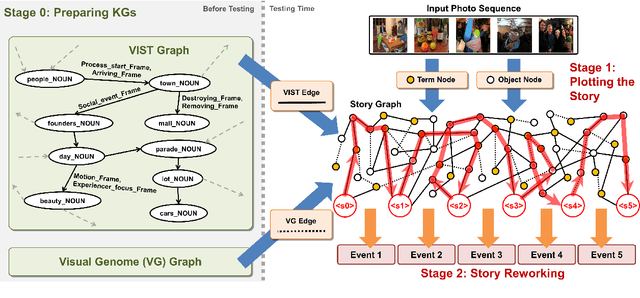

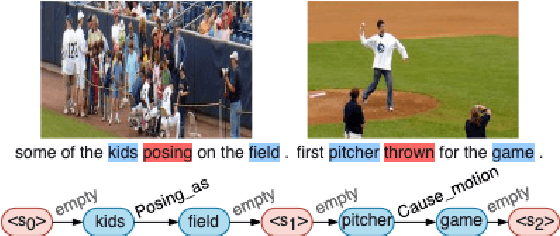

Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.
Happy Dance, Slow Clap: Using Reaction GIFs to Predict Induced Affect on Twitter
May 20, 2021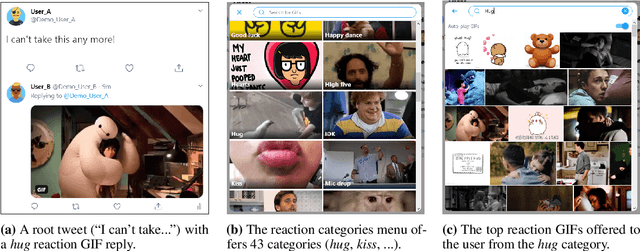
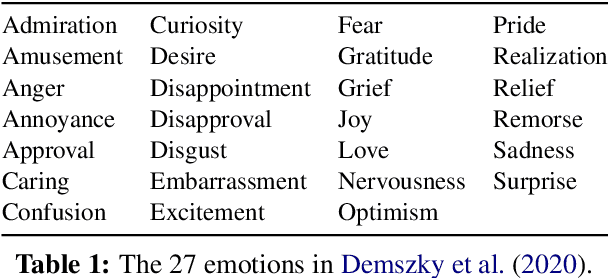
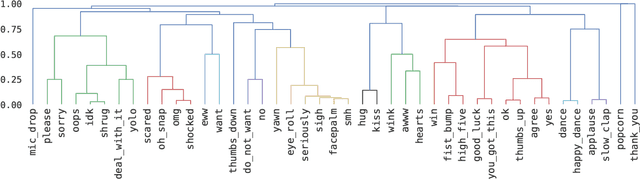
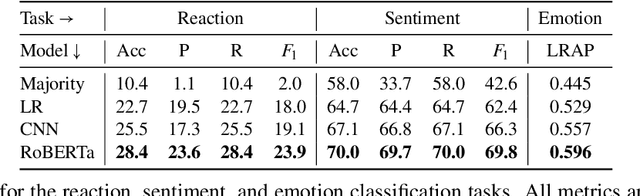
Datasets with induced emotion labels are scarce but of utmost importance for many NLP tasks. We present a new, automated method for collecting texts along with their induced reaction labels. The method exploits the online use of reaction GIFs, which capture complex affective states. We show how to augment the data with induced emotion and induced sentiment labels. We use our method to create and publish ReactionGIF, a first-of-its-kind affective dataset of 30K tweets. We provide baselines for three new tasks, including induced sentiment prediction and multilabel classification of induced emotions. Our method and dataset open new research opportunities in emotion detection and affective computing.
Beyond Fair Pay: Ethical Implications of NLP Crowdsourcing
Apr 20, 2021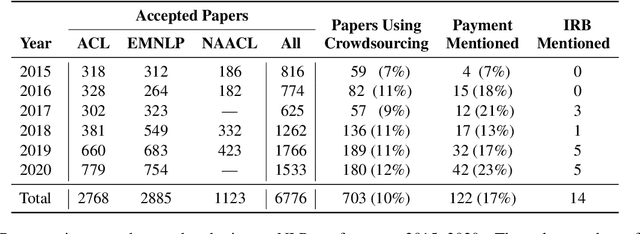


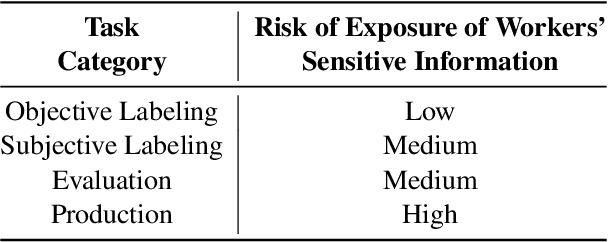
The use of crowdworkers in NLP research is growing rapidly, in tandem with the exponential increase in research production in machine learning and AI. Ethical discussion regarding the use of crowdworkers within the NLP research community is typically confined in scope to issues related to labor conditions such as fair pay. We draw attention to the lack of ethical considerations related to the various tasks performed by workers, including labeling, evaluation, and production. We find that the Final Rule, the common ethical framework used by researchers, did not anticipate the use of online crowdsourcing platforms for data collection, resulting in gaps between the spirit and practice of human-subjects ethics in NLP research. We enumerate common scenarios where crowdworkers performing NLP tasks are at risk of harm. We thus recommend that researchers evaluate these risks by considering the three ethical principles set up by the Belmont Report. We also clarify some common misconceptions regarding the Institutional Review Board (IRB) application. We hope this paper will serve to reopen the discussion within our community regarding the ethical use of crowdworkers.
SocialNLP EmotionGIF 2020 Challenge Overview: Predicting Reaction GIF Categories on Social Media
Feb 24, 2021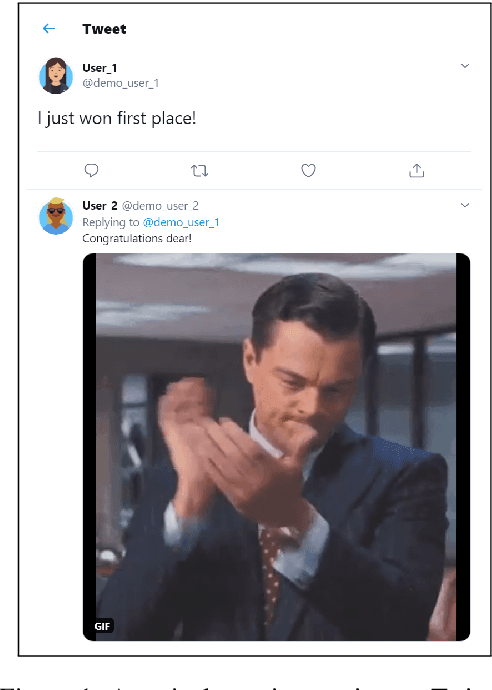



We present an overview of the EmotionGIF2020 Challenge, held at the 8th International Workshop on Natural Language Processing for Social Media (SocialNLP), in conjunction with ACL 2020. The challenge required predicting affective reactions to online texts, and included the EmotionGIF dataset, with tweets labeled for the reaction categories. The novel dataset included 40K tweets with their reaction GIFs. Due to the special circumstances of year 2020, two rounds of the competition were conducted. A total of 84 teams registered for the task. Of these, 25 teams success-fully submitted entries to the evaluation phase in the first round, while 13 teams participated successfully in the second round. Of the top participants, five teams presented a technical report and shared their code. The top score of the winning team using the Recall@K metric was 62.47%.
Assessing the Helpfulness of Learning Materials with Inference-Based Learner-Like Agent
Oct 05, 2020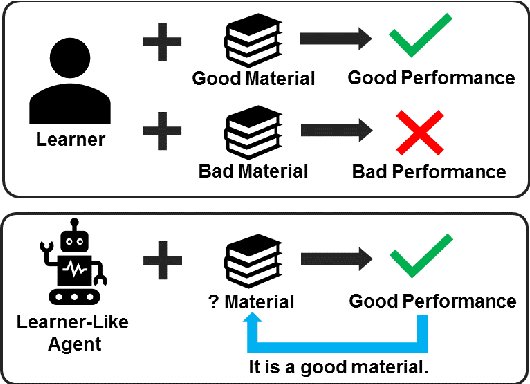
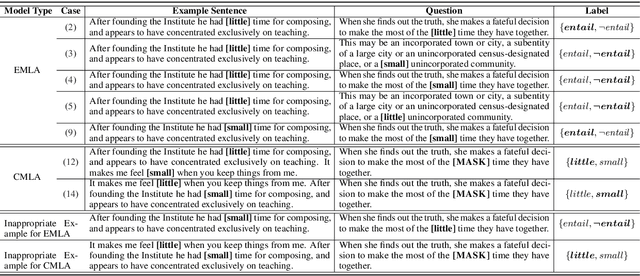
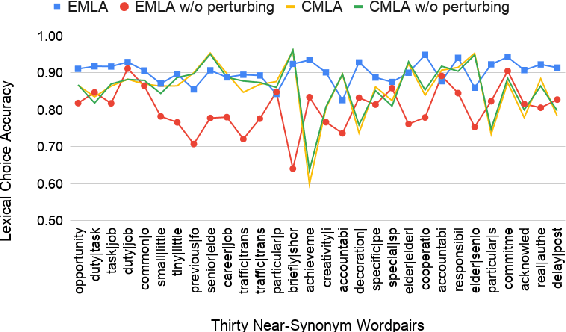

Many English-as-a-second language learners have trouble using near-synonym words (e.g., small vs.little; briefly vs.shortly) correctly, and often look for example sentences to learn how two nearly synonymous terms differ. Prior work uses hand-crafted scores to recommend sentences but has difficulty in adopting such scores to all the near-synonyms as near-synonyms differ in various ways. We notice that the helpfulness of the learning material would reflect on the learners' performance. Thus, we propose the inference-based learner-like agent to mimic learner behavior and identify good learning materials by examining the agent's performance. To enable the agent to behave like a learner, we leverage entailment modeling's capability of inferring answers from the provided materials. Experimental results show that the proposed agent is equipped with good learner-like behavior to achieve the best performance in both fill-in-the-blank (FITB) and good example sentence selection tasks. We further conduct a classroom user study with college ESL learners. The results of the user study show that the proposed agent can find out example sentences that help students learn more easily and efficiently. Compared to other models, the proposed agent improves the score of more than 17% of students after learning.
Reactive Supervision: A New Method for Collecting Sarcasm Data
Sep 28, 2020
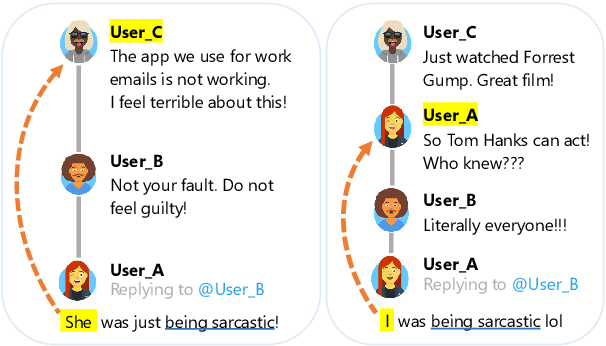
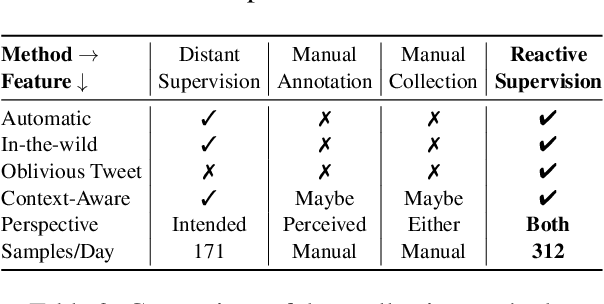
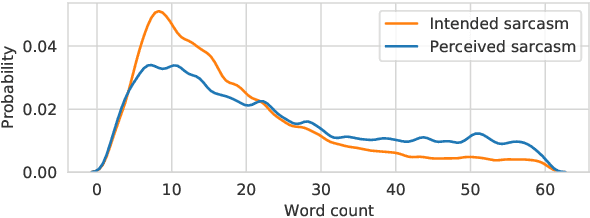
Sarcasm detection is an important task in affective computing, requiring large amounts of labeled data. We introduce reactive supervision, a novel data collection method that utilizes the dynamics of online conversations to overcome the limitations of existing data collection techniques. We use the new method to create and release a first-of-its-kind large dataset of tweets with sarcasm perspective labels and new contextual features. The dataset is expected to advance sarcasm detection research. Our method can be adapted to other affective computing domains, thus opening up new research opportunities.