 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake audio detection by speaker verification
Sep 28, 2022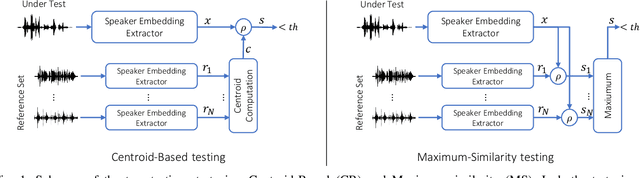
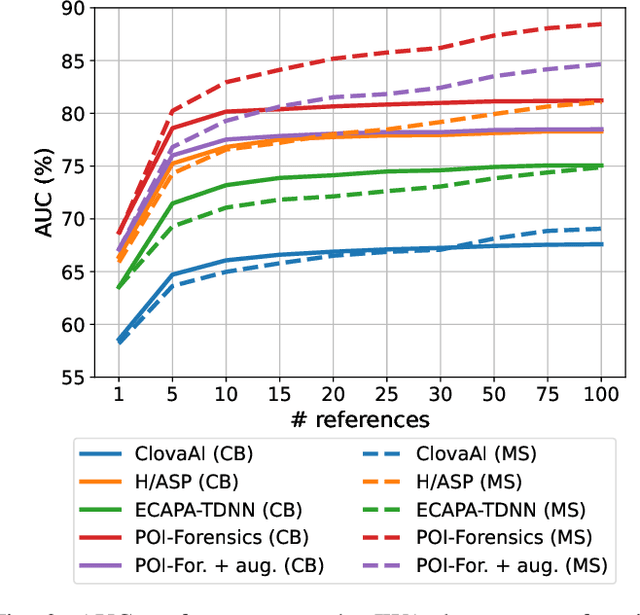
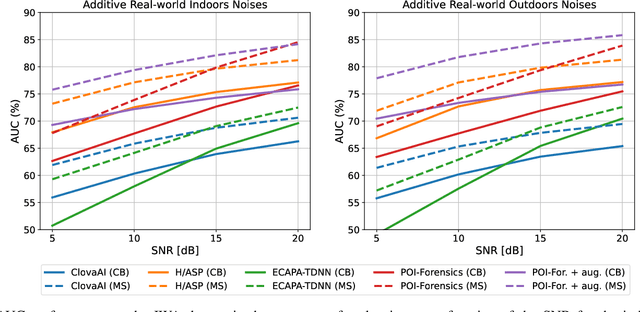

Thanks to recent advances in deep learning, sophisticated generation tools exist, nowadays, that produce extremely realistic synthetic speech. However, malicious uses of such tools are possible and likely, posing a serious threat to our society. Hence, synthetic voice detection has become a pressing research topic, and a large variety of detection methods have been recently proposed. Unfortunately, they hardly generalize to synthetic audios generated by tools never seen in the training phase, which makes them unfit to face real-world scenarios. In this work, we aim at overcoming this issue by proposing a new detection approach that leverages only the biometric characteristics of the speaker, with no reference to specific manipulations. Since the detector is trained only on real data, generalization is automatically ensured. The proposed approach can be implemented based on off-the-shelf speaker verification tools. We test several such solutions on three popular test sets, obtaining good performance, high generalization ability, and high robustness to audio impairment.
Audio-Visual Person-of-Interest DeepFake Detection
Apr 06, 2022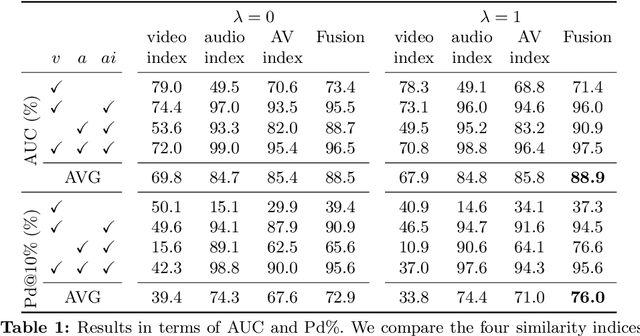

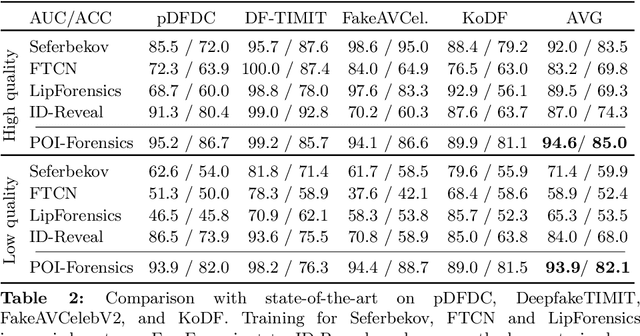
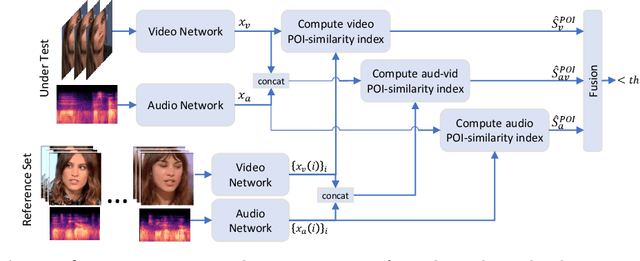
Face manipulation technology is advancing very rapidly, and new methods are being proposed day by day. The aim of this work is to propose a deepfake detector that can cope with the wide variety of manipulation methods and scenarios encountered in the real world. Our key insight is that each person has specific biometric characteristics that a synthetic generator cannot likely reproduce. Accordingly, we extract high-level audio-visual biometric features which characterize the identity of a person, and use them to create a person-of-interest (POI) deepfake detector. We leverage a contrastive learning paradigm to learn the moving-face and audio segments embeddings that are most discriminative for each identity. As a result, when the video and/or audio of a person is manipulated, its representation in the embedding space becomes inconsistent with the real identity, allowing reliable detection. Training is carried out exclusively on real talking-face videos, thus the detector does not depend on any specific manipulation method and yields the highest generalization ability. In addition, our method can detect both single-modality (audio-only, video-only) and multi-modality (audio-video) attacks, and is robust to low-quality or corrupted videos by building only on high-level semantic features. Experiments on a wide variety of datasets confirm that our method ensures a SOTA performance, with an average improvement in terms of AUC of around 3%, 10%, and 7% for high-quality, low quality and attacked videos, respectively.
Towards Universal GAN Image Detection
Dec 23, 2021
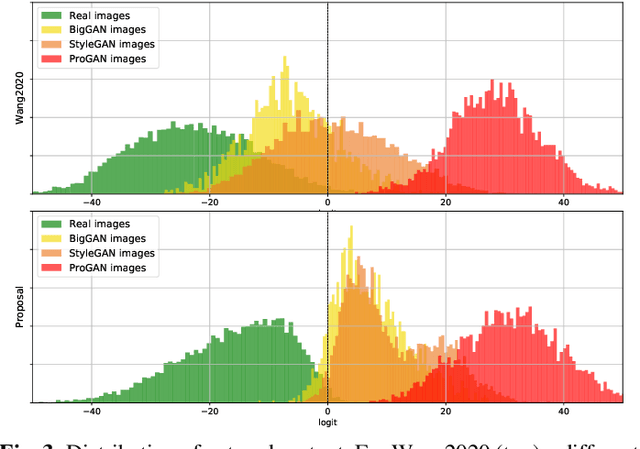
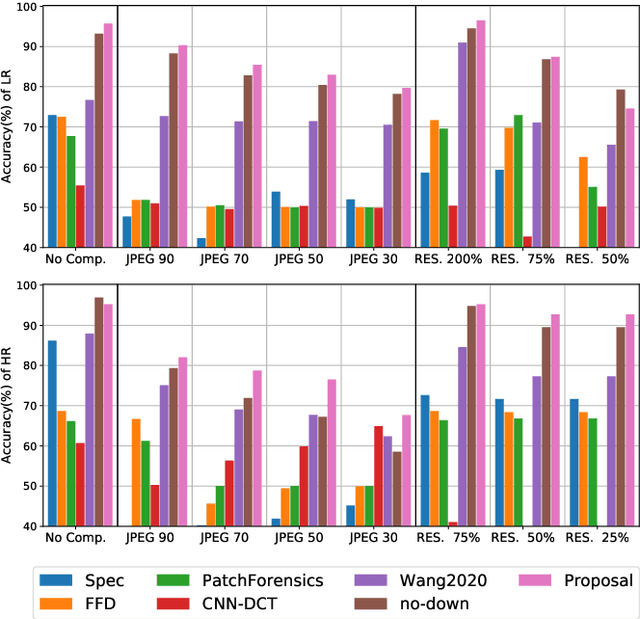
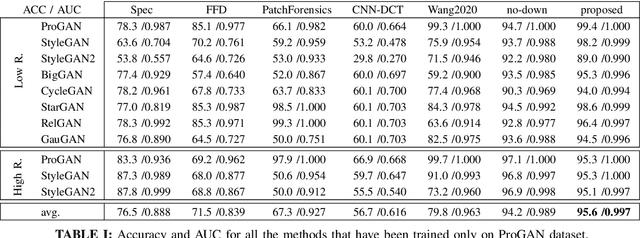
The ever higher quality and wide diffusion of fake images have spawn a quest for reliable forensic tools. Many GAN image detectors have been proposed, recently. In real world scenarios, however, most of them show limited robustness and generalization ability. Moreover, they often rely on side information not available at test time, that is, they are not universal. We investigate these problems and propose a new GAN image detector based on a limited sub-sampling architecture and a suitable contrastive learning paradigm. Experiments carried out in challenging conditions prove the proposed method to be a first step towards universal GAN image detection, ensuring also good robustness to common image impairments, and good generalization to unseen architectures.
Forensic Analysis of Synthetically Generated Scientific Images
Dec 16, 2021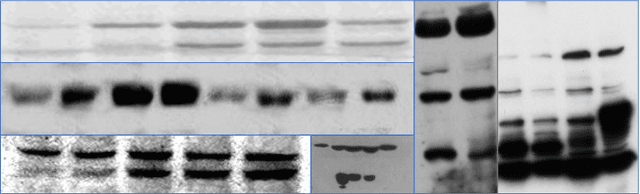
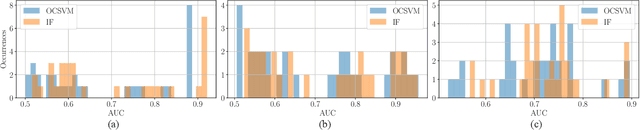
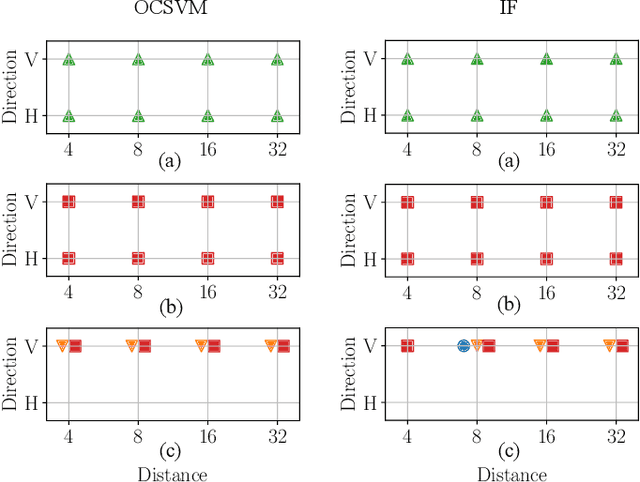

The widespread diffusion of synthetically generated content is a serious threat that needs urgent countermeasures. The generation of synthetic content is not restricted to multimedia data like videos, photographs, or audio sequences, but covers a significantly vast area that can include biological images as well, such as western-blot and microscopic images. In this paper, we focus on the detection of synthetically generated western-blot images. Western-blot images are largely explored in the biomedical literature and it has been already shown how these images can be easily counterfeited with few hope to spot manipulations by visual inspection or by standard forensics detectors. To overcome the absence of a publicly available dataset, we create a new dataset comprising more than 14K original western-blot images and 18K synthetic western-blot images, generated by three different state-of-the-art generation methods. Then, we investigate different strategies to detect synthetic western blots, exploring binary classification methods as well as one-class detectors. In both scenarios, we never exploit synthetic western-blot images at training stage. The achieved results show that synthetically generated western-blot images can be spot with good accuracy, even though the exploited detectors are not optimized over synthetic versions of these scientific images.
Are GAN generated images easy to detect? A critical analysis of the state-of-the-art
Apr 06, 2021
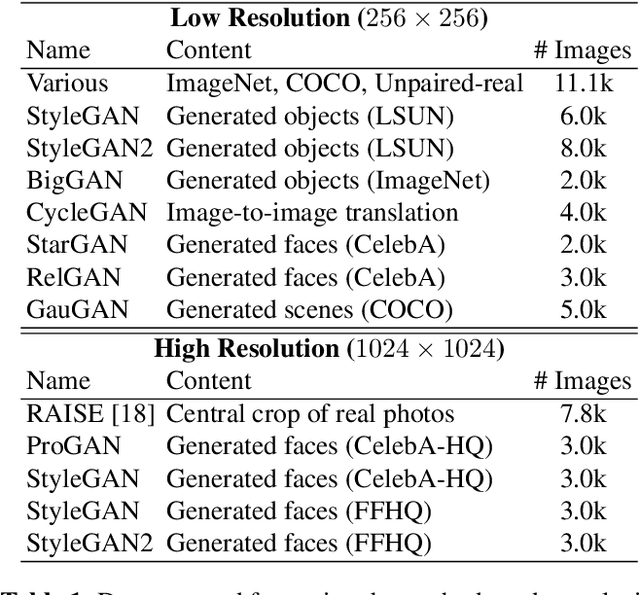

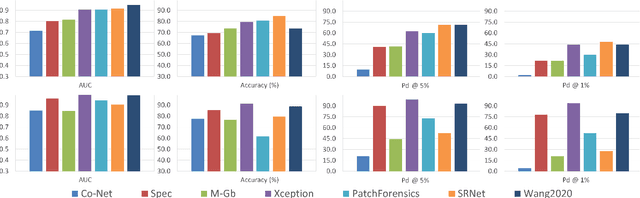
The advent of deep learning has brought a significant improvement in the quality of generated media. However, with the increased level of photorealism, synthetic media are becoming hardly distinguishable from real ones, raising serious concerns about the spread of fake or manipulated information over the Internet. In this context, it is important to develop automated tools to reliably and timely detect synthetic media. In this work, we analyze the state-of-the-art methods for the detection of synthetic images, highlighting the key ingredients of the most successful approaches, and comparing their performance over existing generative architectures. We will devote special attention to realistic and challenging scenarios, like media uploaded on social networks or generated by new and unseen architectures, analyzing the impact of suitable augmentation and training strategies on the detectors' generalization ability.
Deep learning methods for SAR image despeckling: trends and perspectives
Dec 10, 2020
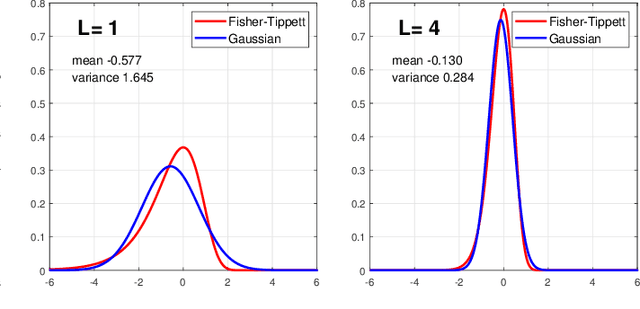


Synthetic aperture radar (SAR) images are affected by a spatially-correlated and signal-dependent noise called speckle, which is very severe and may hinder image exploitation. Despeckling is an important task that aims at removing such noise, so as to improve the accuracy of all downstream image processing tasks. The first despeckling methods date back to the 1970's, and several model-based algorithms have been developed in the subsequent years. The field has received growing attention, sparkled by the availability of powerful deep learning models that have yielded excellent performance for inverse problems in image processing. This paper surveys the literature on deep learning methods applied to SAR despeckling, covering both the supervised and the more recent self-supervised approaches. We provide a critical analysis of existing methods with the objective to recognize the most promising research lines, to identify the factors that have limited the success of deep models, and to propose ways forward in an attempt to fully exploit the potential of deep learning for SAR despeckling.
ID-Reveal: Identity-aware DeepFake Video Detection
Dec 04, 2020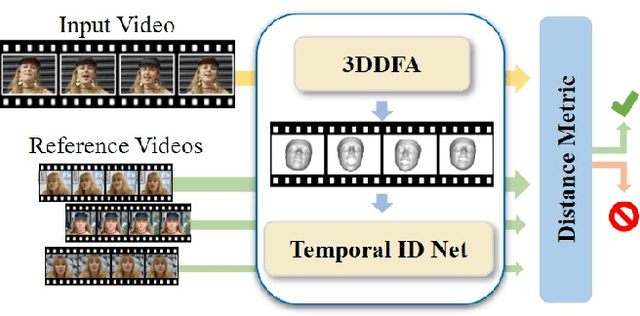
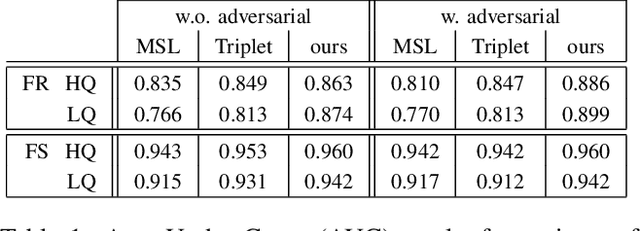
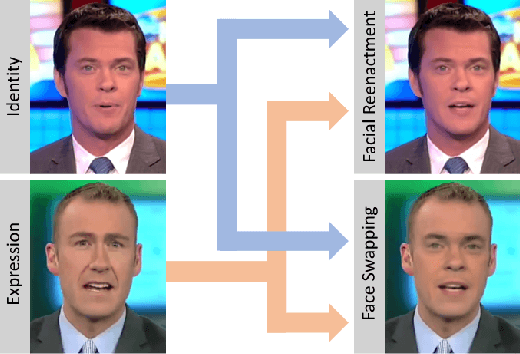
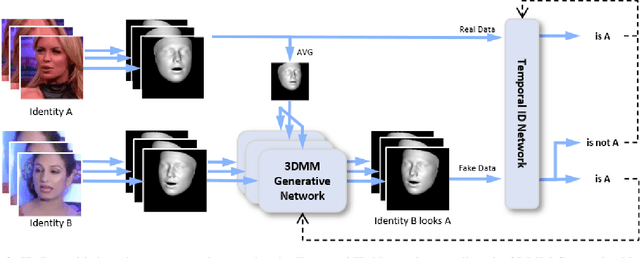
State-of-the-art DeepFake forgery detectors are trained in a supervised fashion to answer the question 'is this video real or fake?'. Given that their training is typically method-specific, these approaches show poor generalization across different types of facial manipulations, e.g., face swapping or facial reenactment. In this work, we look at the problem from a different perspective by focusing on the facial characteristics of a specific identity; i.e., we want to answer the question 'Is this the person who is claimed to be?'. To this end, we introduce ID-Reveal, a new approach that learns temporal facial features, specific of how each person moves while talking, by means of metric learning coupled with an adversarial training strategy. Our method is independent of the specific type of manipulation since it is trained only on real videos. Moreover, relying on high-level semantic features, it is robust to widespread and disruptive forms of post-processing. We performed a thorough experimental analysis on several publicly available benchmarks, such as FaceForensics++, Google's DFD, and Celeb-DF. Compared to state of the art, our method improves generalization and is more robust to low-quality videos, that are usually spread over social networks. In particular, we obtain an average improvement of more than 15% in terms of accuracy for facial reenactment on high compressed videos.
Deep learning in the ultrasound evaluation of neonatal respiratory status
Oct 31, 2020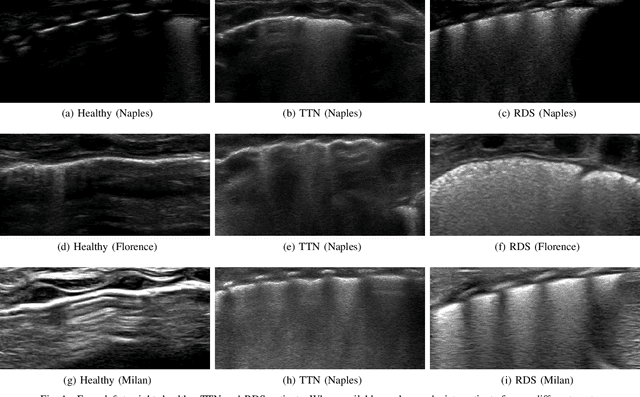
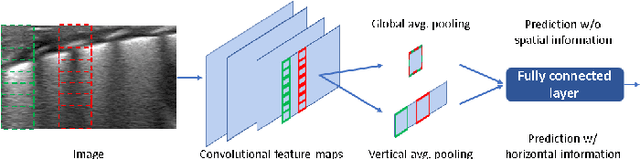
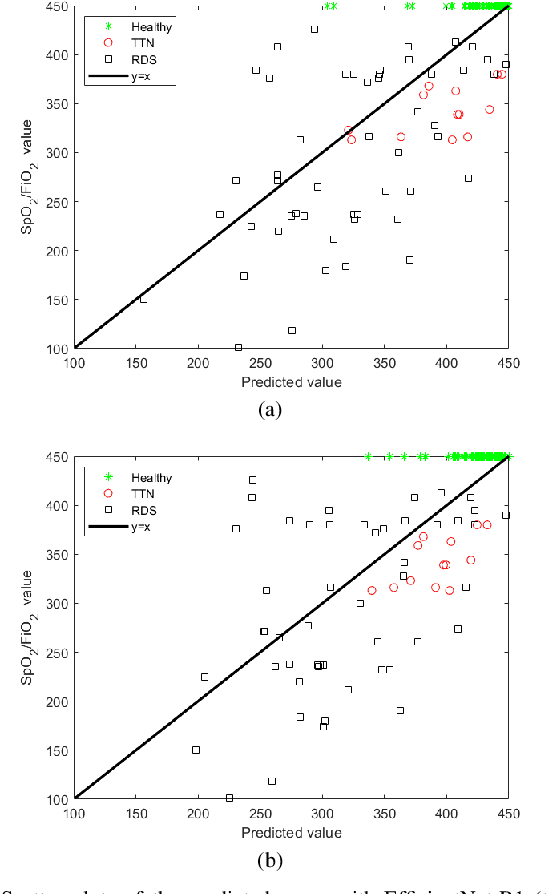
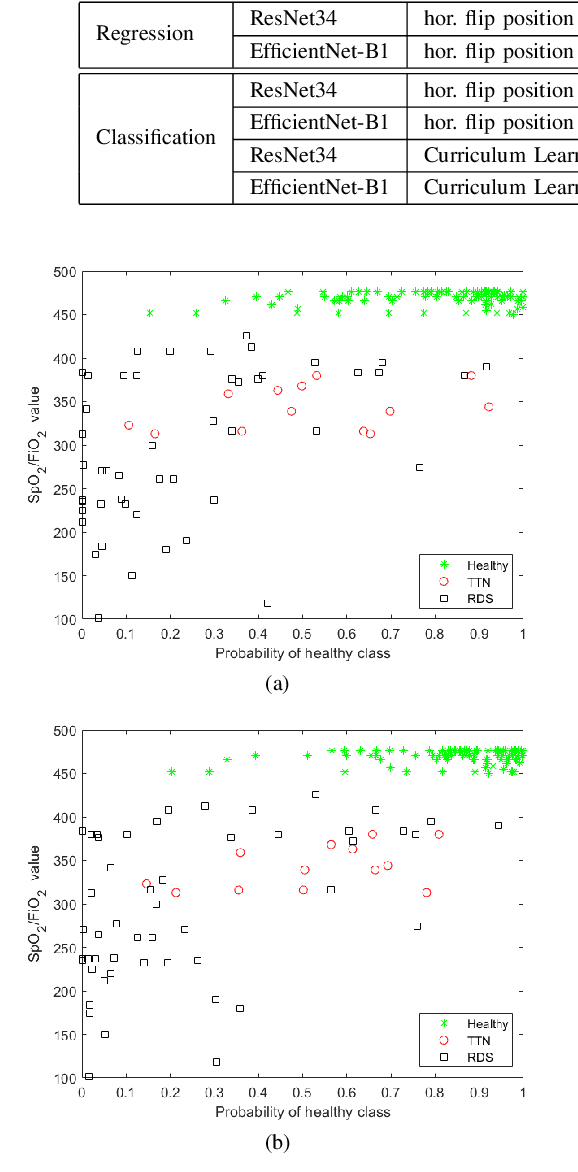
Lung ultrasound imaging is reaching growing interest from the scientific community. On one side, thanks to its harmlessness and high descriptive power, this kind of diagnostic imaging has been largely adopted in sensitive applications, like the diagnosis and follow-up of preterm newborns in neonatal intensive care units. On the other side, state-of-the-art image analysis and pattern recognition approaches have recently proven their ability to fully exploit the rich information contained in these data, making them attractive for the research community. In this work, we present a thorough analysis of recent deep learning networks and training strategies carried out on a vast and challenging multicenter dataset comprising 87 patients with different diseases and gestational ages. These approaches are employed to assess the lung respiratory status from ultrasound images and are evaluated against a reference marker. The conducted analysis sheds some light on this problem by showing the critical points that can mislead the training procedure and proposes some adaptations to the specific data and task. The achieved results sensibly outperform those obtained by a previous work, which is based on textural features, and narrow the gap with the visual score predicted by the human experts.
CNN-based fast source device identification
Jan 31, 2020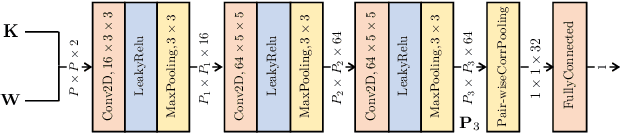
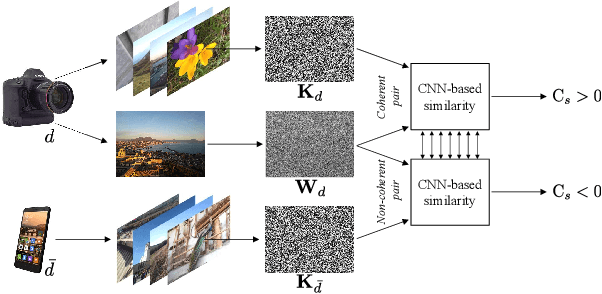
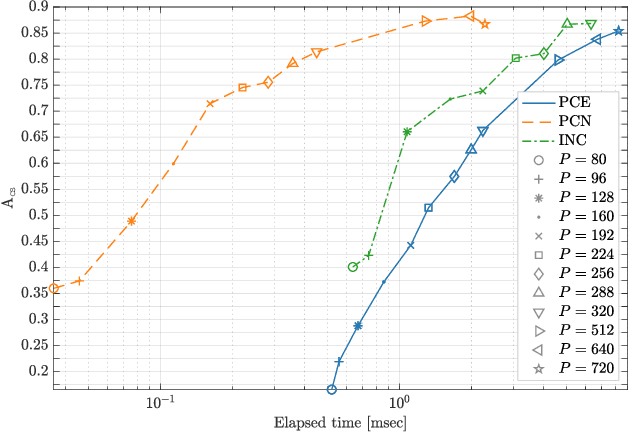
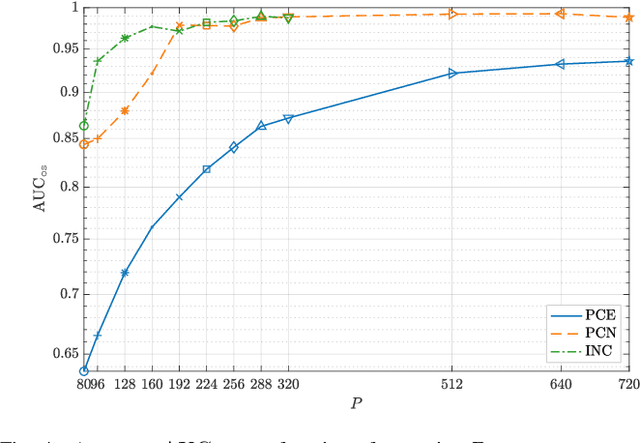
Source identification is an important topic in image forensics, since it allows to trace back the origin of an image. This represents a precious information to claim intellectual property but also to reveal the authors of illicit materials. In this paper we address the problem of device identification based on sensor noise and propose a fast and accurate solution using convolutional neural networks (CNNs). Specifically, we propose a 2-channel-based CNN that learns a way of comparing camera fingerprint and image noise at patch level. The proposed solution turns out to be much faster than the conventional approach and to ensure an increased accuracy. This makes the approach particularly suitable in scenarios where large databases of images are analyzed, like over social networks. In this vein, since images uploaded on social media usually undergo at least two compression stages, we include investigations on double JPEG compressed images, always reporting higher accuracy than standard approaches.
Media Forensics and DeepFakes: an overview
Jan 18, 2020



With the rapid progress of recent years, techniques that generate and manipulate multimedia content can now guarantee a very advanced level of realism. The boundary between real and synthetic media has become very thin. On the one hand, this opens the door to a series of exciting applications in different fields such as creative arts, advertising, film production, video games. On the other hand, it poses enormous security threats. Software packages freely available on the web allow any individual, without special skills, to create very realistic fake images and videos. So-called deepfakes can be used to manipulate public opinion during elections, commit fraud, discredit or blackmail people. Potential abuses are limited only by human imagination. Therefore, there is an urgent need for automated tools capable of detecting false multimedia content and avoiding the spread of dangerous false information. This review paper aims to present an analysis of the methods for visual media integrity verification, that is, the detection of manipulated images and videos. Special emphasis will be placed on the emerging phenomenon of deepfakes and, from the point of view of the forensic analyst, on modern data-driven forensic methods. The analysis will help to highlight the limits of current forensic tools, the most relevant issues, the upcoming challenges, and suggest future directions for research.