 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpora deduplication or duplication in Natural Language Processing of few resourced languages ? A case of study: The Mexico's Nahuatl
Apr 08, 2026In this article, we seek to answer the following question: could data duplication be useful in Natural Language Processing (NLP) for languages with limited computational resources? In this type of languages (or $π$-languages), corpora available for training Large Language Models are virtually non-existent. In particular, we will study the impact of corpora expansion in Nawatl, an agglutinative and polysynthetic $π$-language spoken by over 2 million people, with a large number of dialectal varieties. The aim is to expand the new $π$-yalli corpus, which contains a limited number of Nawatl texts, by duplicating it in a controlled way. In our experiments, we will use the incremental duplication technique. The aim is to learn embeddings that are well-suited to NLP tasks. Thus, static embeddings were trained and evaluated in a sentence-level semantic similarity task. Our results show a moderate improvement in performance when using incremental duplication compared to the results obtained using only the corpus without expansion. Furthermore, to our knowledge, this technique has not yet been used in the literature.
A Preliminary Study for Literary Rhyme Generation based on Neuronal Representation, Semantics and Shallow Parsing
Dec 25, 2021

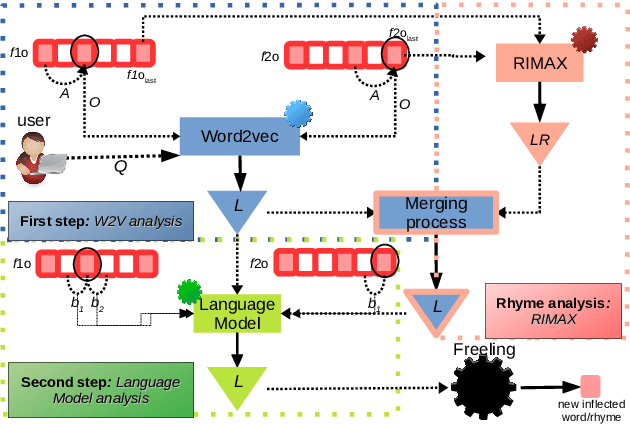
In recent years, researchers in the area of Computational Creativity have studied the human creative process proposing different approaches to reproduce it with a formal procedure. In this paper, we introduce a model for the generation of literary rhymes in Spanish, combining structures of language and neural network models %(\textit{Word2vec}).%, into a structure for semantic assimilation. The results obtained with a manual evaluation of the texts generated by our algorithm are encouraging.
* 7 pages, 2 figures
LiSSS: A toy corpus of Spanish Literary Sentences for Emotions detection
Jun 06, 2020

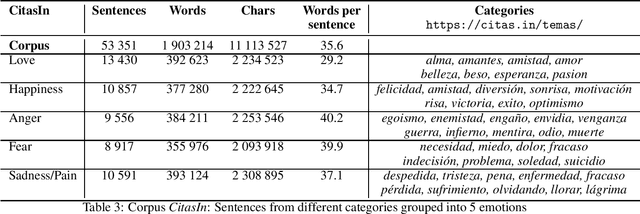
In this work we present a new small data-set in Computational Creativity (CC) field, the Spanish Literary Sentences for emotions detection corpus (LISSS). We address this corpus of literary sentences in order to evaluate or design algorithms of emotions classification and detection. We have constitute this corpus by manually classifying the sentences in a set of emotions: Love, Fear, Happiness, Anger and Sadness/Pain. We also present some baseline classification algorithms applied on our corpus. The LISSS corpus will be available to the community as a free resource to evaluate or create CC-like algorithms.
Generación automática de frases literarias en español
Jan 17, 2020
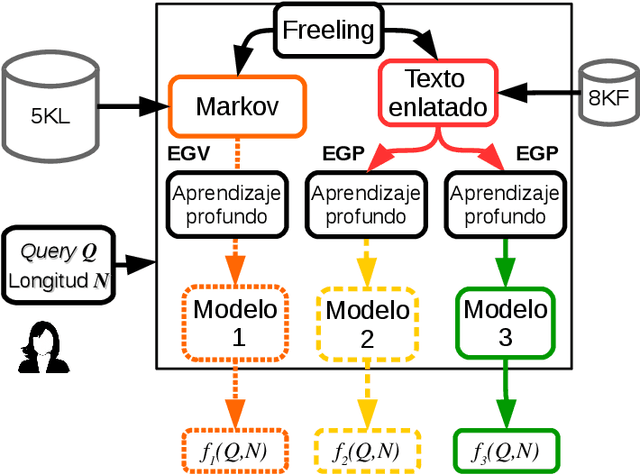

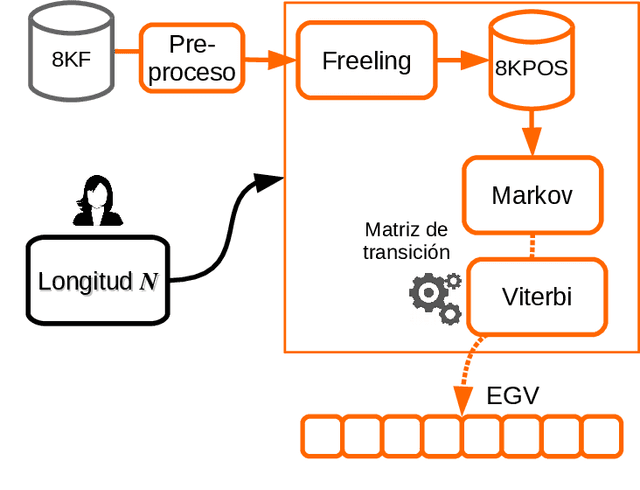
In this work we present a state of the art in the area of Computational Creativity (CC). In particular, we address the automatic generation of literary sentences in Spanish. We propose three models of text generation based mainly on statistical algorithms and shallow parsing analysis. We also present some rather encouraging preliminary results.