 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix and match networks: encoder-decoder alignment for zero-pair image translation
Apr 06, 2018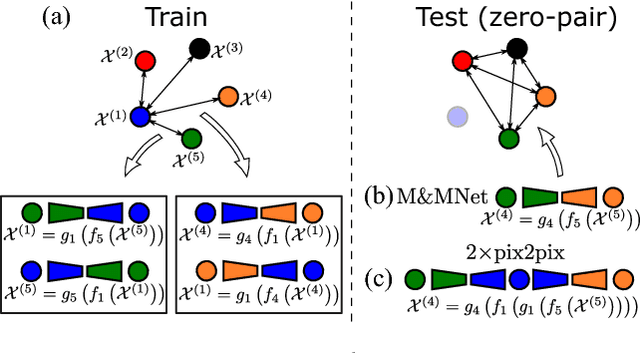
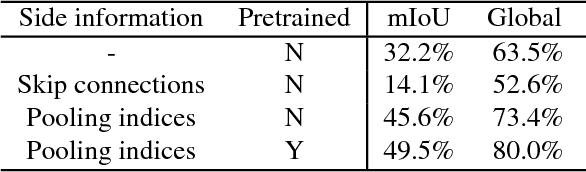
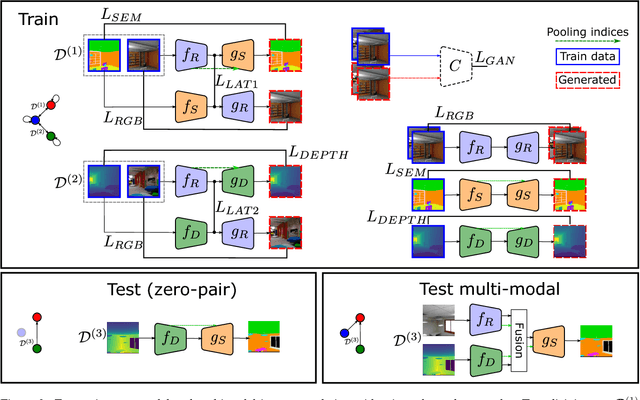
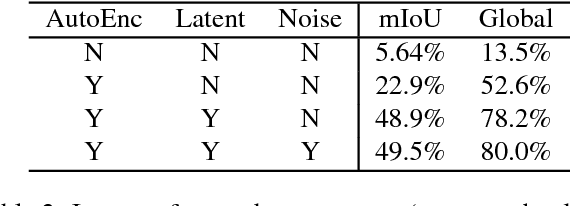
We address the problem of image translation between domains or modalities for which no direct paired data is available (i.e. zero-pair translation). We propose mix and match networks, based on multiple encoders and decoders aligned in such a way that other encoder-decoder pairs can be composed at test time to perform unseen image translation tasks between domains or modalities for which explicit paired samples were not seen during training. We study the impact of autoencoders, side information and losses in improving the alignment and transferability of trained pairwise translation models to unseen translations. We show our approach is scalable and can perform colorization and style transfer between unseen combinations of domains. We evaluate our system in a challenging cross-modal setting where semantic segmentation is estimated from depth images, without explicit access to any depth-semantic segmentation training pairs. Our model outperforms baselines based on pix2pix and CycleGAN models.
Food recognition and recipe analysis: integrating visual content, context and external knowledge
Jan 22, 2018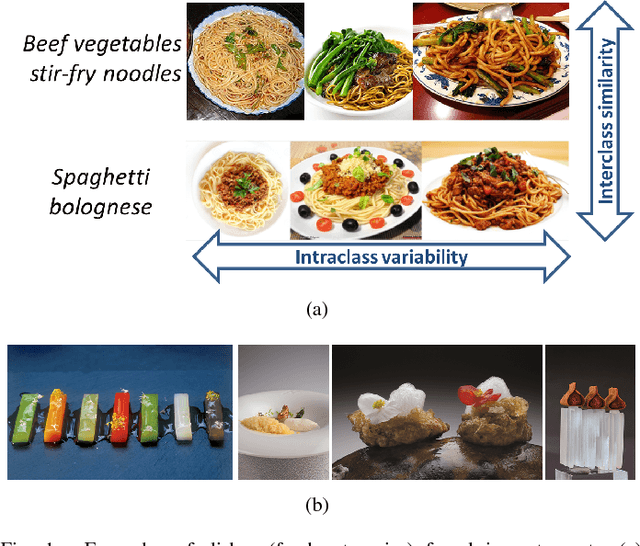
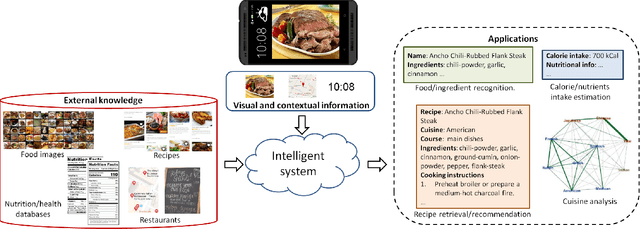
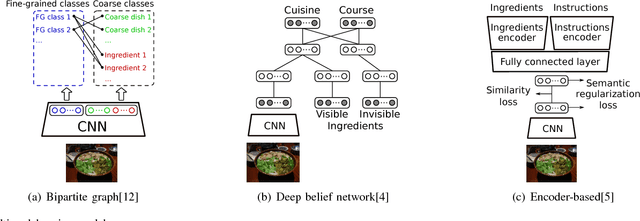
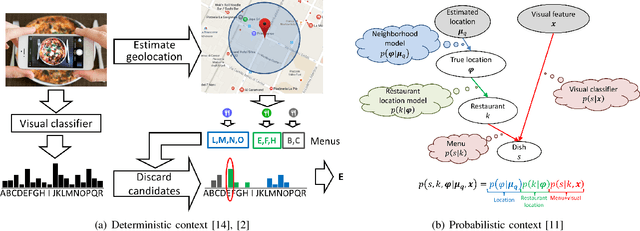
The central role of food in our individual and social life, combined with recent technological advances, has motivated a growing interest in applications that help to better monitor dietary habits as well as the exploration and retrieval of food-related information. We review how visual content, context and external knowledge can be integrated effectively into food-oriented applications, with special focus on recipe analysis and retrieval, food recommendation, and the restaurant context as emerging directions.
Scene recognition with CNNs: objects, scales and dataset bias
Jan 21, 2018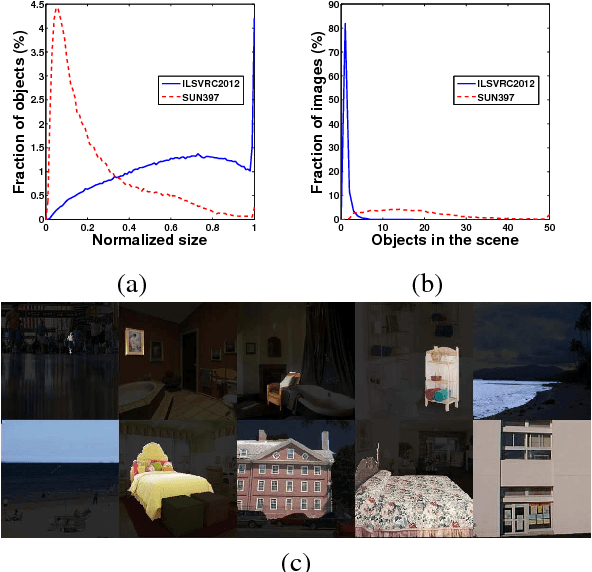
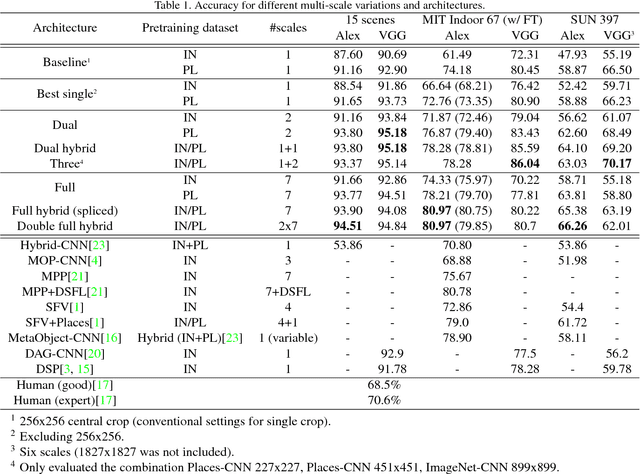

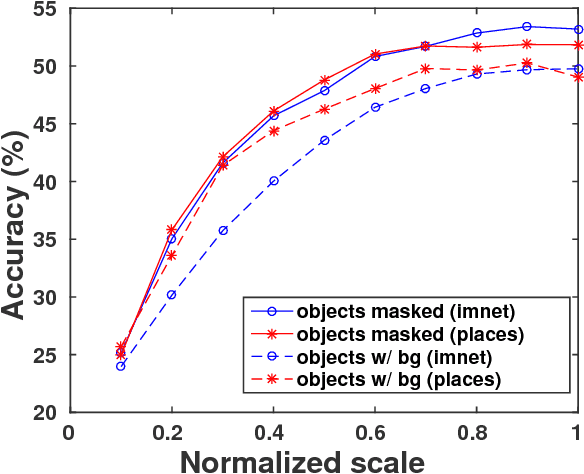
Since scenes are composed in part of objects, accurate recognition of scenes requires knowledge about both scenes and objects. In this paper we address two related problems: 1) scale induced dataset bias in multi-scale convolutional neural network (CNN) architectures, and 2) how to combine effectively scene-centric and object-centric knowledge (i.e. Places and ImageNet) in CNNs. An earlier attempt, Hybrid-CNN, showed that incorporating ImageNet did not help much. Here we propose an alternative method taking the scale into account, resulting in significant recognition gains. By analyzing the response of ImageNet-CNNs and Places-CNNs at different scales we find that both operate in different scale ranges, so using the same network for all the scales induces dataset bias resulting in limited performance. Thus, adapting the feature extractor to each particular scale (i.e. scale-specific CNNs) is crucial to improve recognition, since the objects in the scenes have their specific range of scales. Experimental results show that the recognition accuracy highly depends on the scale, and that simple yet carefully chosen multi-scale combinations of ImageNet-CNNs and Places-CNNs, can push the state-of-the-art recognition accuracy in SUN397 up to 66.26% (and even 70.17% with deeper architectures, comparable to human performance).
* CVPR 2016
Depth CNNs for RGB-D scene recognition: learning from scratch better than transferring from RGB-CNNs
Jan 21, 2018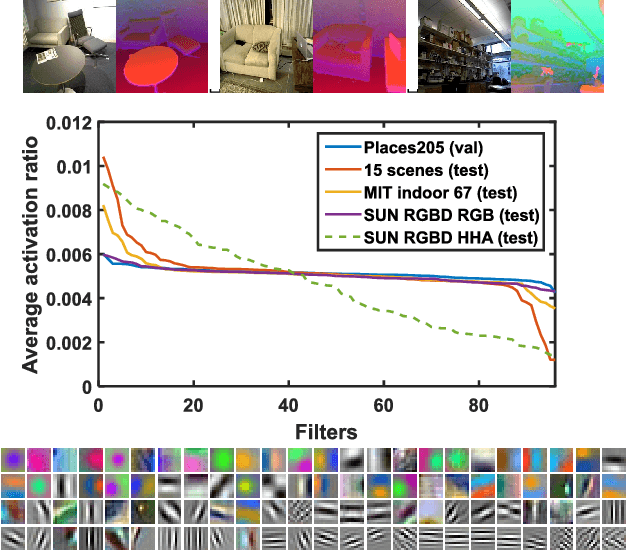
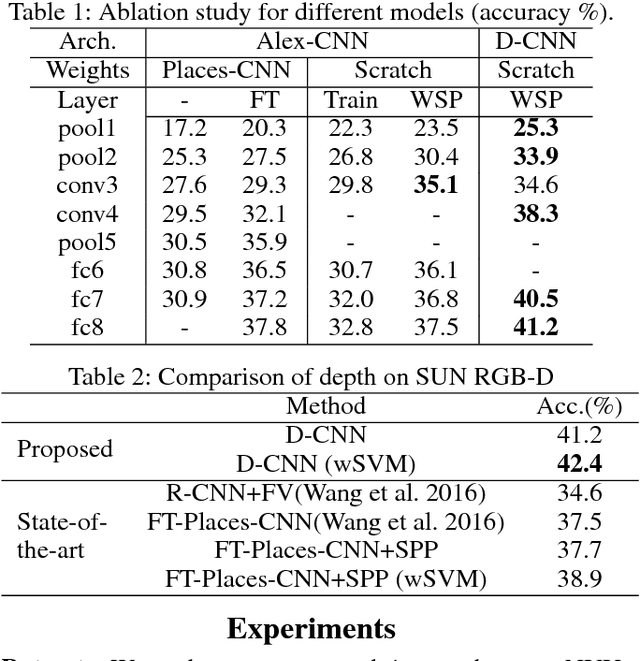
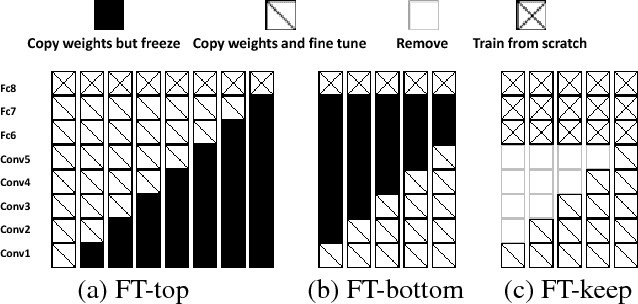
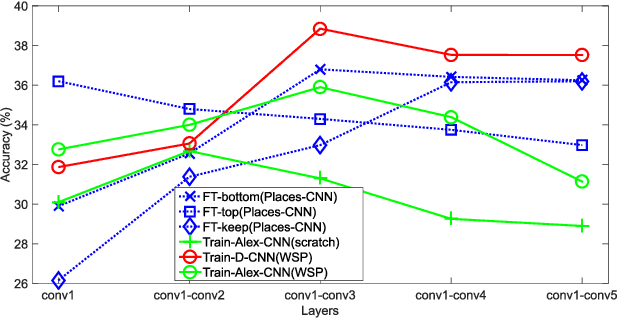
Scene recognition with RGB images has been extensively studied and has reached very remarkable recognition levels, thanks to convolutional neural networks (CNN) and large scene datasets. In contrast, current RGB-D scene data is much more limited, so often leverages RGB large datasets, by transferring pretrained RGB CNN models and fine-tuning with the target RGB-D dataset. However, we show that this approach has the limitation of hardly reaching bottom layers, which is key to learn modality-specific features. In contrast, we focus on the bottom layers, and propose an alternative strategy to learn depth features combining local weakly supervised training from patches followed by global fine tuning with images. This strategy is capable of learning very discriminative depth-specific features with limited depth images, without resorting to Places-CNN. In addition we propose a modified CNN architecture to further match the complexity of the model and the amount of data available. For RGB-D scene recognition, depth and RGB features are combined by projecting them in a common space and further leaning a multilayer classifier, which is jointly optimized in an end-to-end network. Our framework achieves state-of-the-art accuracy on NYU2 and SUN RGB-D in both depth only and combined RGB-D data.
* AAAI Conference on Artificial Intelligence 2017
Domain-adaptive deep network compression
Sep 06, 2017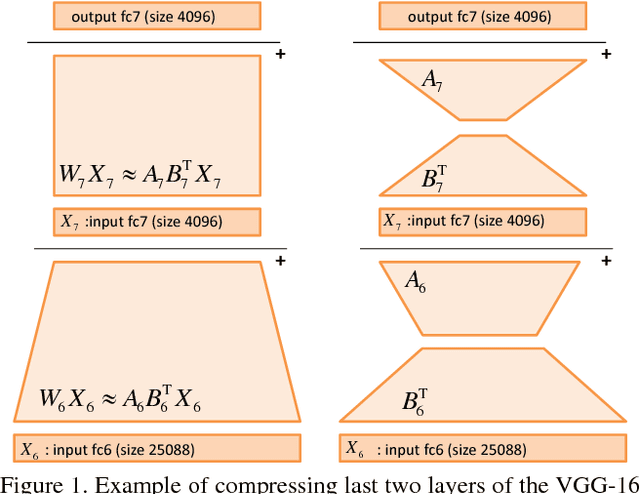
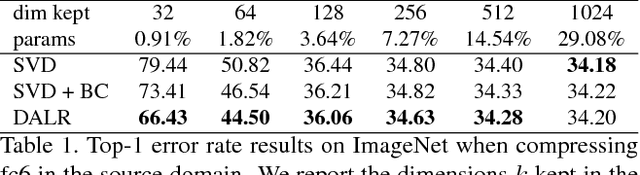
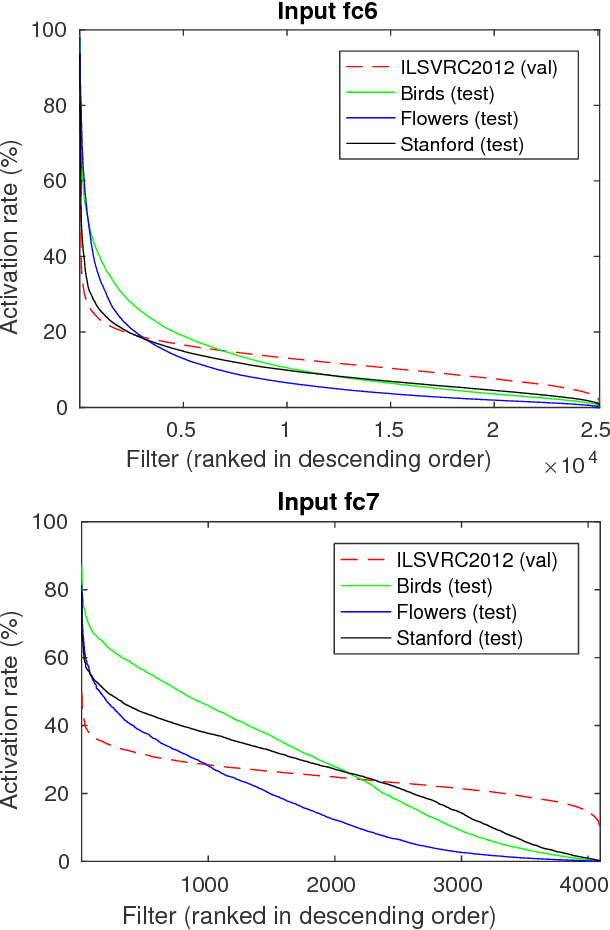
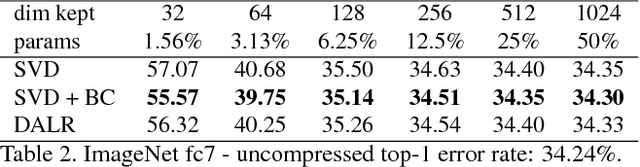
Deep Neural Networks trained on large datasets can be easily transferred to new domains with far fewer labeled examples by a process called fine-tuning. This has the advantage that representations learned in the large source domain can be exploited on smaller target domains. However, networks designed to be optimal for the source task are often prohibitively large for the target task. In this work we address the compression of networks after domain transfer. We focus on compression algorithms based on low-rank matrix decomposition. Existing methods base compression solely on learned network weights and ignore the statistics of network activations. We show that domain transfer leads to large shifts in network activations and that it is desirable to take this into account when compressing. We demonstrate that considering activation statistics when compressing weights leads to a rank-constrained regression problem with a closed-form solution. Because our method takes into account the target domain, it can more optimally remove the redundancy in the weights. Experiments show that our Domain Adaptive Low Rank (DALR) method significantly outperforms existing low-rank compression techniques. With our approach, the fc6 layer of VGG19 can be compressed more than 4x more than using truncated SVD alone -- with only a minor or no loss in accuracy. When applied to domain-transferred networks it allows for compression down to only 5-20% of the original number of parameters with only a minor drop in performance.
LIUM-CVC Submissions for WMT17 Multimodal Translation Task
Jul 14, 2017
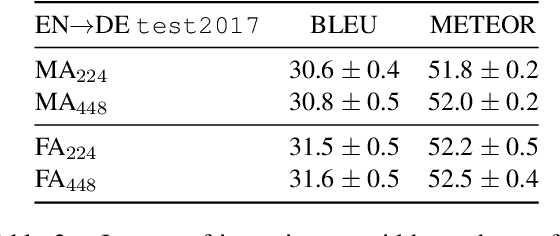
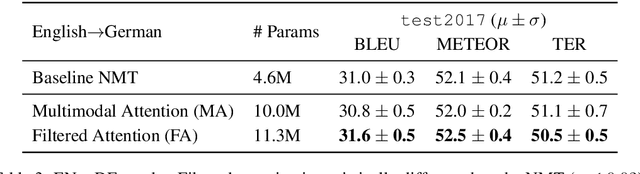
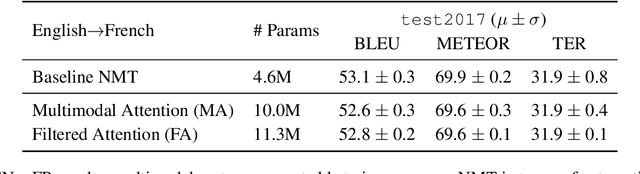
This paper describes the monomodal and multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT17 Shared Task on Multimodal Translation. We mainly explored two multimodal architectures where either global visual features or convolutional feature maps are integrated in order to benefit from visual context. Our final systems ranked first for both En-De and En-Fr language pairs according to the automatic evaluation metrics METEOR and BLEU.