 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Image-to-image Translation and Image Compression
Nov 25, 2021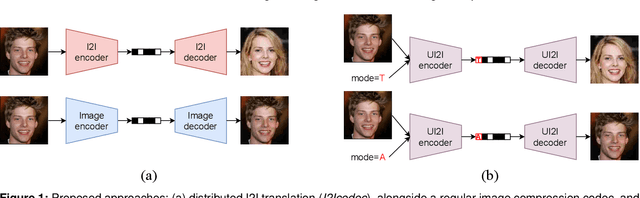
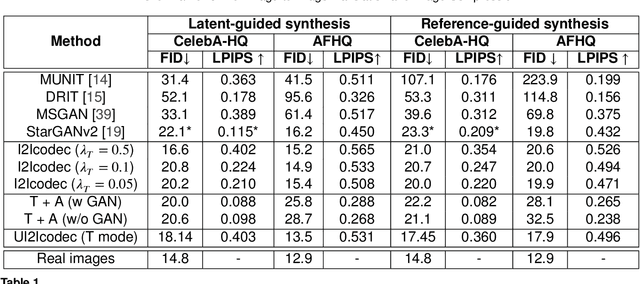
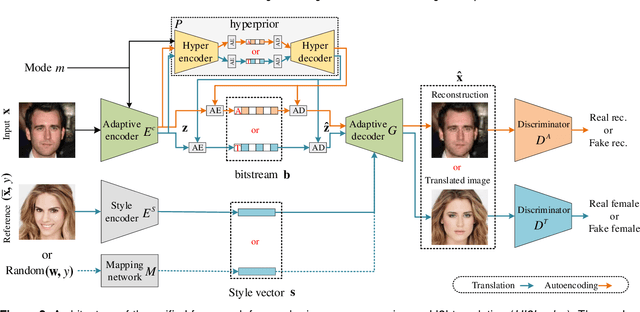

Data-driven paradigms using machine learning are becoming ubiquitous in image processing and communications. In particular, image-to-image (I2I) translation is a generic and widely used approach to image processing problems, such as image synthesis, style transfer, and image restoration. At the same time, neural image compression has emerged as a data-driven alternative to traditional coding approaches in visual communications. In this paper, we study the combination of these two paradigms into a joint I2I compression and translation framework, focusing on multi-domain image synthesis. We first propose distributed I2I translation by integrating quantization and entropy coding into an I2I translation framework (i.e. I2Icodec). In practice, the image compression functionality (i.e. autoencoding) is also desirable, requiring to deploy alongside I2Icodec a regular image codec. Thus, we further propose a unified framework that allows both translation and autoencoding capabilities in a single codec. Adaptive residual blocks conditioned on the translation/compression mode provide flexible adaptation to the desired functionality. The experiments show promising results in both I2I translation and image compression using a single model.
Incremental Meta-Learning via Episodic Replay Distillation for Few-Shot Image Recognition
Nov 11, 2021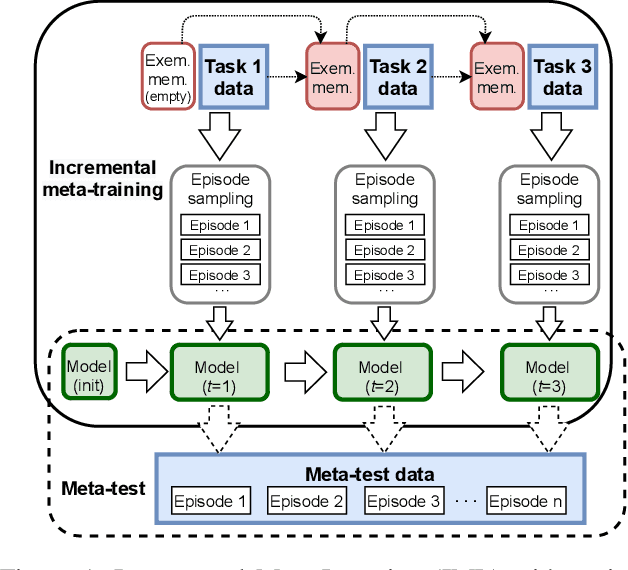
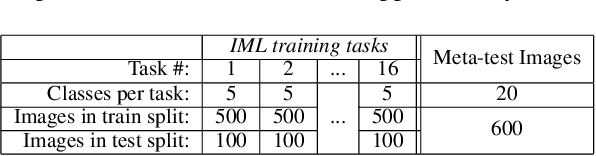
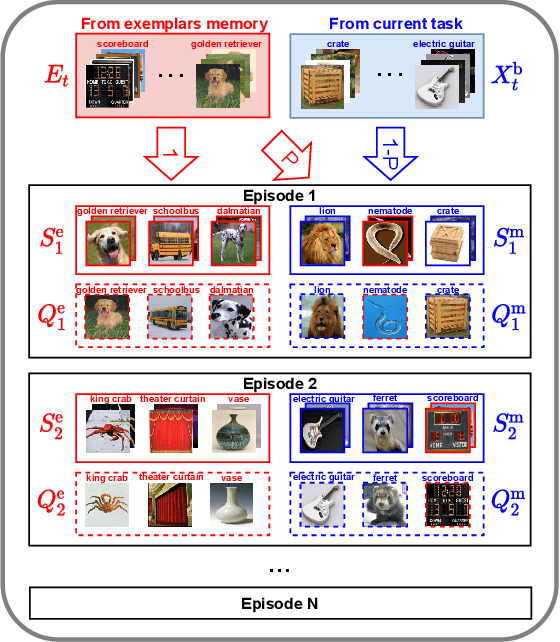
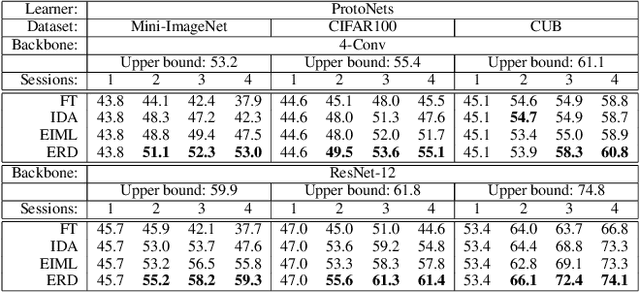
Most meta-learning approaches assume the existence of a very large set of labeled data available for episodic meta-learning of base knowledge. This contrasts with the more realistic continual learning paradigm in which data arrives incrementally in the form of tasks containing disjoint classes. In this paper we consider this problem of Incremental Meta-Learning (IML) in which classes are presented incrementally in discrete tasks. We propose an approach to IML, which we call Episodic Replay Distillation (ERD), that mixes classes from the current task with class exemplars from previous tasks when sampling episodes for meta-learning. These episodes are then used for knowledge distillation to minimize catastrophic forgetting. Experiments on four datasets demonstrate that ERD surpasses the state-of-the-art. In particular, on the more challenging one-shot, long task sequence incremental meta-learning scenarios, we reduce the gap between IML and the joint-training upper bound from 3.5% / 10.1% / 13.4% with the current state-of-the-art to 2.6% / 2.9% / 5.0% with our method on Tiered-ImageNet / Mini-ImageNet / CIFAR100, respectively.
HCV: Hierarchy-Consistency Verification for Incremental Implicitly-Refined Classification
Oct 22, 2021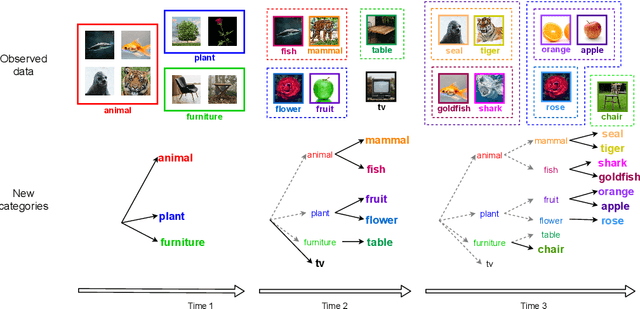
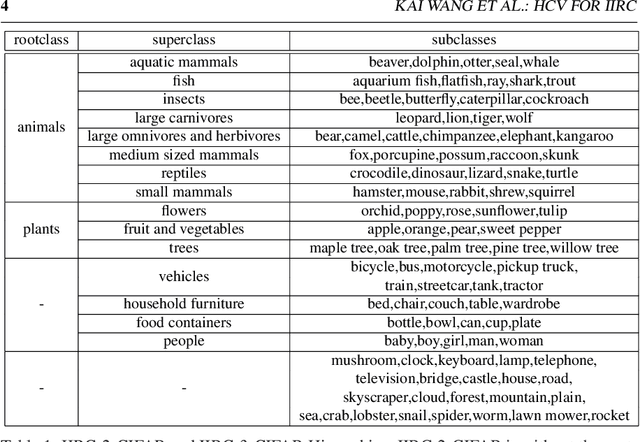
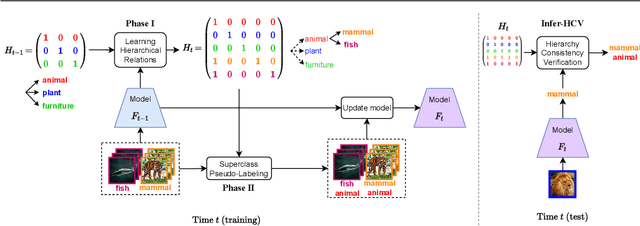
Human beings learn and accumulate hierarchical knowledge over their lifetime. This knowledge is associated with previous concepts for consolidation and hierarchical construction. However, current incremental learning methods lack the ability to build a concept hierarchy by associating new concepts to old ones. A more realistic setting tackling this problem is referred to as Incremental Implicitly-Refined Classification (IIRC), which simulates the recognition process from coarse-grained categories to fine-grained categories. To overcome forgetting in this benchmark, we propose Hierarchy-Consistency Verification (HCV) as an enhancement to existing continual learning methods. Our method incrementally discovers the hierarchical relations between classes. We then show how this knowledge can be exploited during both training and inference. Experiments on three setups of varying difficulty demonstrate that our HCV module improves performance of existing continual learning methods under this IIRC setting by a large margin. Code is available in https://github.com/wangkai930418/HCV_IIRC.
DVC-P: Deep Video Compression with Perceptual Optimizations
Oct 08, 2021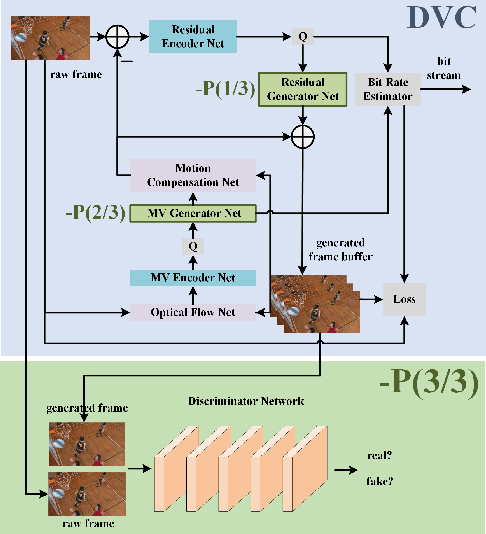
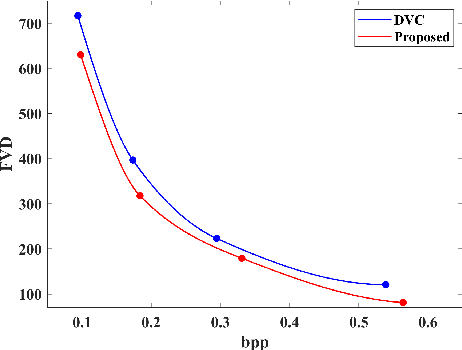
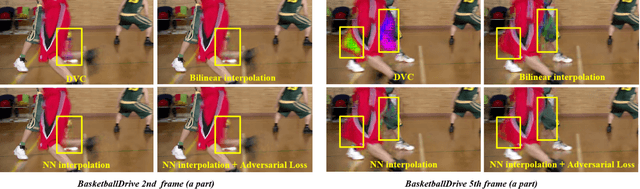

Recent years have witnessed the significant development of learning-based video compression methods, which aim at optimizing objective or perceptual quality and bit rates. In this paper, we introduce deep video compression with perceptual optimizations (DVC-P), which aims at increasing perceptual quality of decoded videos. Our proposed DVC-P is based on Deep Video Compression (DVC) network, but improves it with perceptual optimizations. Specifically, a discriminator network and a mixed loss are employed to help our network trade off among distortion, perception and rate. Furthermore, nearest-neighbor interpolation is used to eliminate checkerboard artifacts which can appear in sequences encoded with DVC frameworks. Thanks to these two improvements, the perceptual quality of decoded sequences is improved. Experimental results demonstrate that, compared with the baseline DVC, our proposed method can generate videos with higher perceptual quality achieving 12.27% reduction in a perceptual BD-rate equivalent, on average.
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021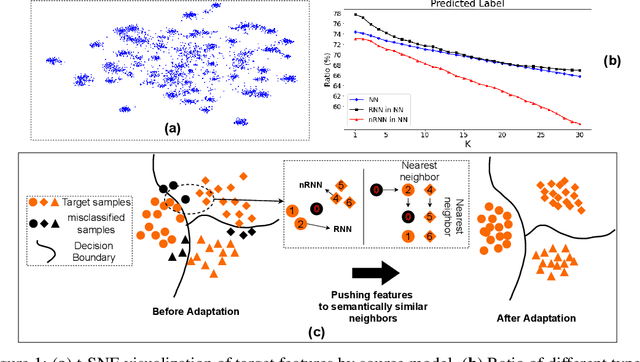
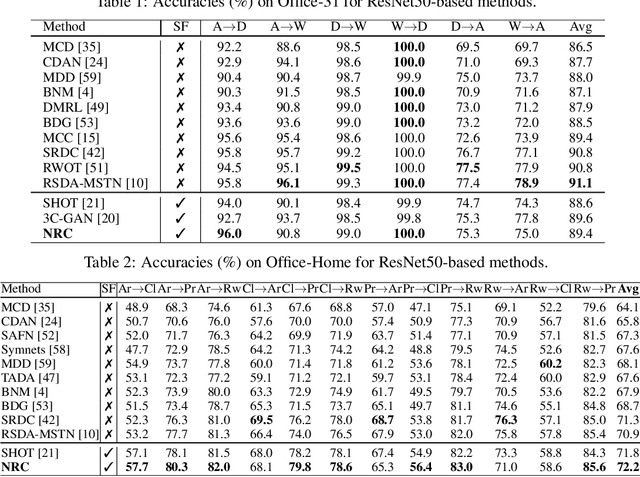
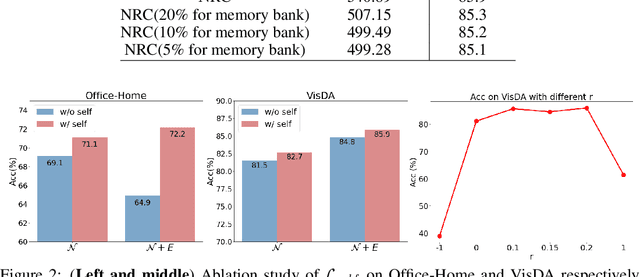
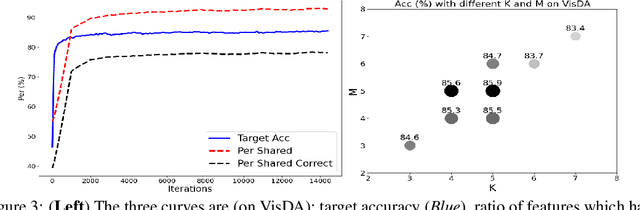
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.
Generalized Source-free Domain Adaptation
Aug 03, 2021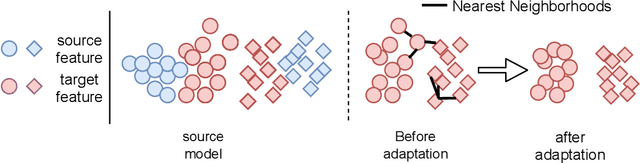
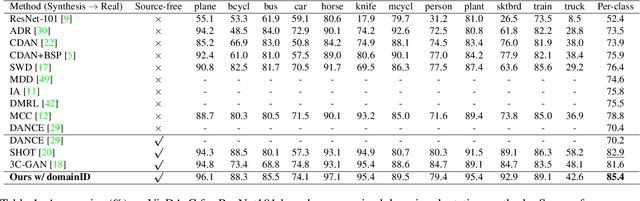
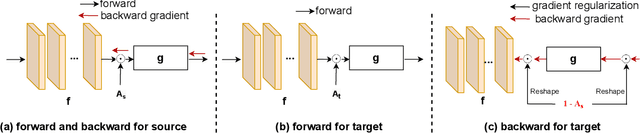
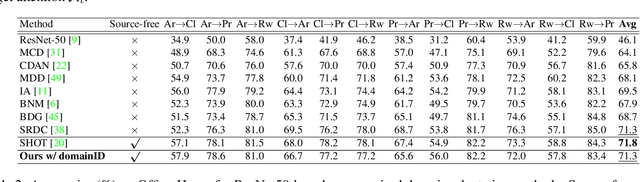
Domain adaptation (DA) aims to transfer the knowledge learned from a source domain to an unlabeled target domain. Some recent works tackle source-free domain adaptation (SFDA) where only a source pre-trained model is available for adaptation to the target domain. However, those methods do not consider keeping source performance which is of high practical value in real world applications. In this paper, we propose a new domain adaptation paradigm called Generalized Source-free Domain Adaptation (G-SFDA), where the learned model needs to perform well on both the target and source domains, with only access to current unlabeled target data during adaptation. First, we propose local structure clustering (LSC), aiming to cluster the target features with its semantically similar neighbors, which successfully adapts the model to the target domain in the absence of source data. Second, we propose sparse domain attention (SDA), it produces a binary domain specific attention to activate different feature channels for different domains, meanwhile the domain attention will be utilized to regularize the gradient during adaptation to keep source information. In the experiments, for target performance our method is on par with or better than existing DA and SFDA methods, specifically it achieves state-of-the-art performance (85.4%) on VisDA, and our method works well for all domains after adapting to single or multiple target domains. Code is available in https://github.com/Albert0147/G-SFDA.
ACAE-REMIND for Online Continual Learning with Compressed Feature Replay
May 18, 2021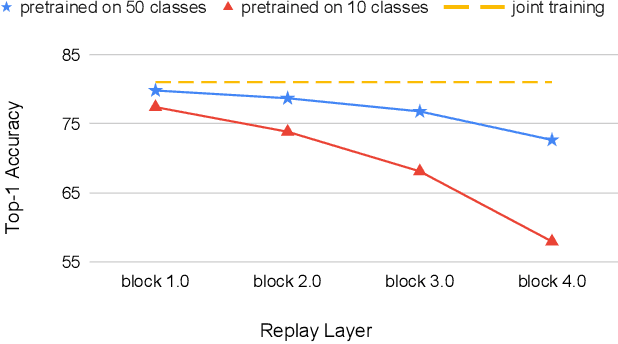

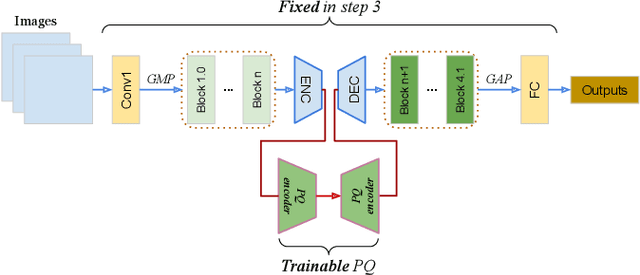
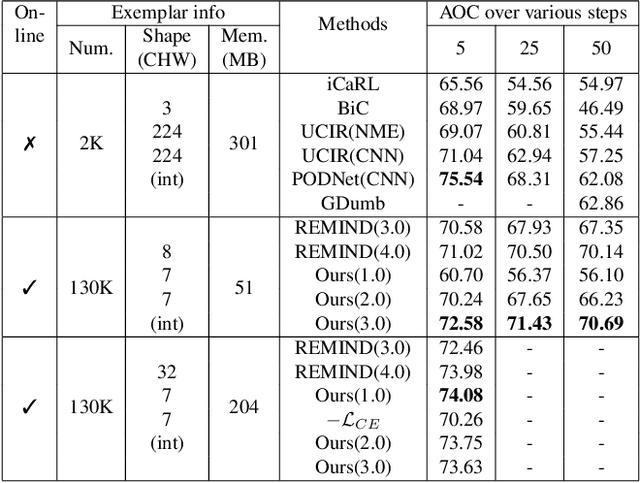
Online continual learning aims to learn from a non-IID stream of data from a number of different tasks, where the learner is only allowed to consider data once. Methods are typically allowed to use a limited buffer to store some of the images in the stream. Recently, it was found that feature replay, where an intermediate layer representation of the image is stored (or generated) leads to superior results than image replay, while requiring less memory. Quantized exemplars can further reduce the memory usage. However, a drawback of these methods is that they use a fixed (or very intransigent) backbone network. This significantly limits the learning of representations that can discriminate between all tasks. To address this problem, we propose an auxiliary classifier auto-encoder (ACAE) module for feature replay at intermediate layers with high compression rates. The reduced memory footprint per image allows us to save more exemplars for replay. In our experiments, we conduct task-agnostic evaluation under online continual learning setting and get state-of-the-art performance on ImageNet-Subset, CIFAR100 and CIFAR10 dataset.
MineGAN++: Mining Generative Models for Efficient Knowledge Transfer to Limited Data Domains
Apr 28, 2021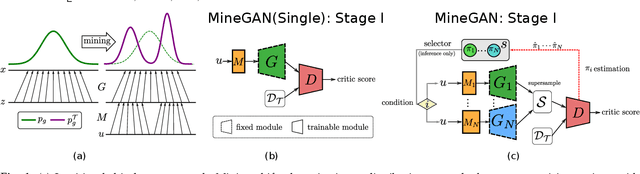
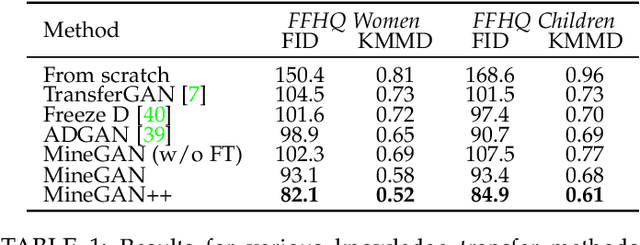
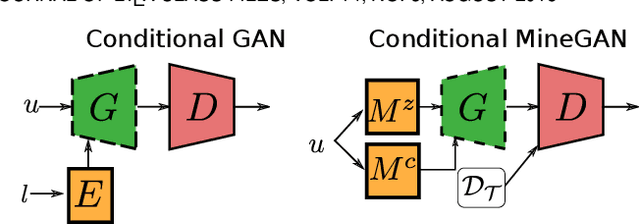
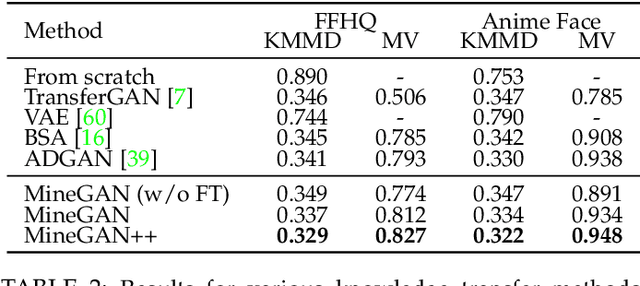
GANs largely increases the potential impact of generative models. Therefore, we propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods, such as mode collapse and lack of flexibility. Furthermore, to prevent overfitting on small target domains, we introduce sparse subnetwork selection, that restricts the set of trainable neurons to those that are relevant for the target dataset. We perform comprehensive experiments on several challenging datasets using various GAN architectures (BigGAN, Progressive GAN, and StyleGAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
DANICE: Domain adaptation without forgetting in neural image compression
Apr 19, 2021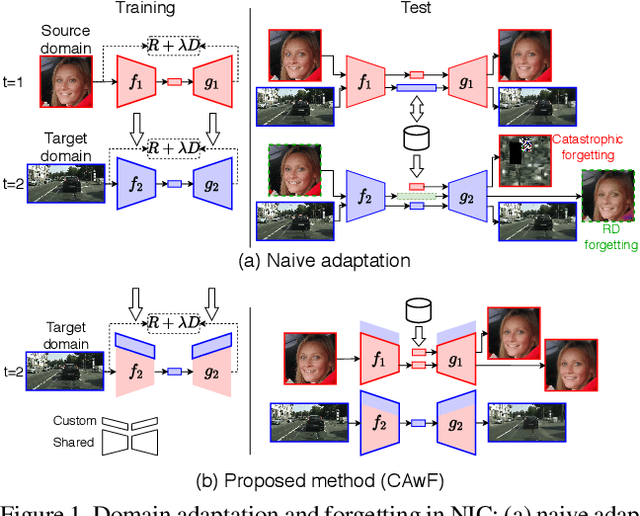

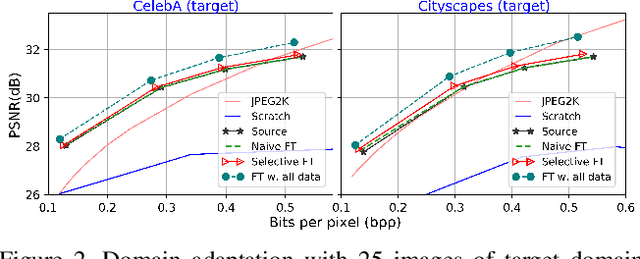
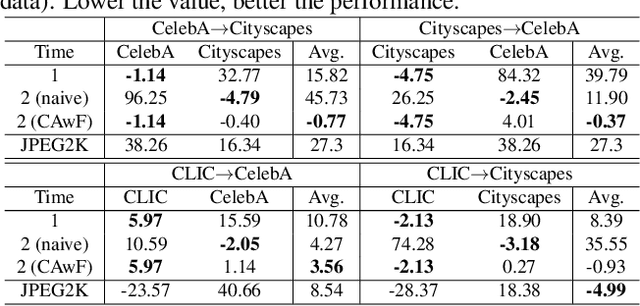
Neural image compression (NIC) is a new coding paradigm where coding capabilities are captured by deep models learned from data. This data-driven nature enables new potential functionalities. In this paper, we study the adaptability of codecs to custom domains of interest. We show that NIC codecs are transferable and that they can be adapted with relatively few target domain images. However, naive adaptation interferes with the solution optimized for the original source domain, resulting in forgetting the original coding capabilities in that domain, and may even break the compatibility with previously encoded bitstreams. Addressing these problems, we propose Codec Adaptation without Forgetting (CAwF), a framework that can avoid these problems by adding a small amount of custom parameters, where the source codec remains embedded and unchanged during the adaptation process. Experiments demonstrate its effectiveness and provide useful insights on the characteristics of catastrophic interference in NIC.
Continual learning in cross-modal retrieval
Apr 19, 2021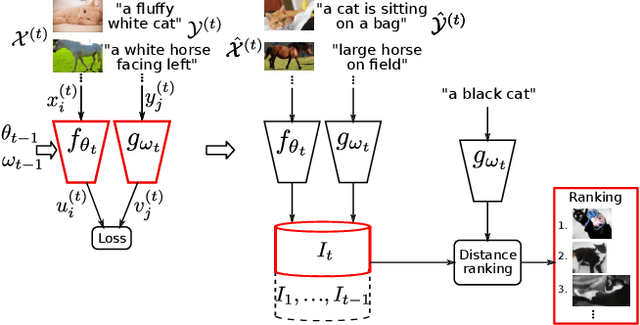
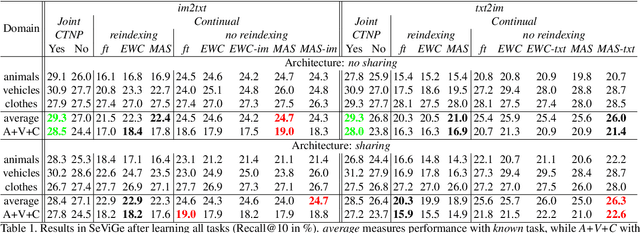
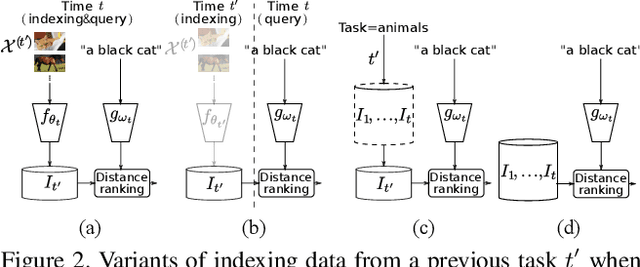
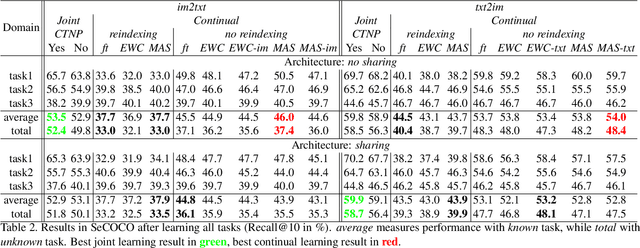
Multimodal representations and continual learning are two areas closely related to human intelligence. The former considers the learning of shared representation spaces where information from different modalities can be compared and integrated (we focus on cross-modal retrieval between language and visual representations). The latter studies how to prevent forgetting a previously learned task when learning a new one. While humans excel in these two aspects, deep neural networks are still quite limited. In this paper, we propose a combination of both problems into a continual cross-modal retrieval setting, where we study how the catastrophic interference caused by new tasks impacts the embedding spaces and their cross-modal alignment required for effective retrieval. We propose a general framework that decouples the training, indexing and querying stages. We also identify and study different factors that may lead to forgetting, and propose tools to alleviate it. We found that the indexing stage pays an important role and that simply avoiding reindexing the database with updated embedding networks can lead to significant gains. We evaluated our methods in two image-text retrieval datasets, obtaining significant gains with respect to the fine tuning baseline.