 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Oct 23, 2023



Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics and benchmarks. This fragmented landscape makes it hard for the community to know, for instance, given a task, which is the best performing model and how it compares with others. To alleviate this issue, we introduce a unified benchmark for NLP evaluation in social media, SuperTweetEval, which includes a heterogeneous set of tasks and datasets combined, adapted and constructed from scratch. We benchmarked the performance of a wide range of models on SuperTweetEval and our results suggest that, despite the recent advances in language modelling, social media remains challenging.
RAGAS: Automated Evaluation of Retrieval Augmented Generation
Sep 26, 2023We introduce RAGAs (Retrieval Augmented Generation Assessment), a framework for reference-free evaluation of Retrieval Augmented Generation (RAG) pipelines. RAG systems are composed of a retrieval and an LLM based generation module, and provide LLMs with knowledge from a reference textual database, which enables them to act as a natural language layer between a user and textual databases, reducing the risk of hallucinations. Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself. With RAGAs, we put forward a suite of metrics which can be used to evaluate these different dimensions \textit{without having to rely on ground truth human annotations}. We posit that such a framework can crucially contribute to faster evaluation cycles of RAG architectures, which is especially important given the fast adoption of LLMs.
WIKITIDE: A Wikipedia-Based Timestamped Definition Pairs Dataset
Aug 18, 2023



A fundamental challenge in the current NLP context, dominated by language models, comes from the inflexibility of current architectures to 'learn' new information. While model-centric solutions like continual learning or parameter-efficient fine tuning are available, the question still remains of how to reliably identify changes in language or in the world. In this paper, we propose WikiTiDe, a dataset derived from pairs of timestamped definitions extracted from Wikipedia. We argue that such resource can be helpful for accelerating diachronic NLP, specifically, for training models able to scan knowledge resources for core updates concerning a concept, an event, or a named entity. Our proposed end-to-end method is fully automatic, and leverages a bootstrapping algorithm for gradually creating a high-quality dataset. Our results suggest that bootstrapping the seed version of WikiTiDe leads to better fine-tuned models. We also leverage fine-tuned models in a number of downstream tasks, showing promising results with respect to competitive baselines.
3D-EX : A Unified Dataset of Definitions and Dictionary Examples
Aug 11, 2023Definitions are a fundamental building block in lexicography, linguistics and computational semantics. In NLP, they have been used for retrofitting word embeddings or augmenting contextual representations in language models. However, lexical resources containing definitions exhibit a wide range of properties, which has implications in the behaviour of models trained and evaluated on them. In this paper, we introduce 3D- EX , a dataset that aims to fill this gap by combining well-known English resources into one centralized knowledge repository in the form of <term, definition, example> triples. 3D- EX is a unified evaluation framework with carefully pre-computed train/validation/test splits to prevent memorization. We report experimental results that suggest that this dataset could be effectively leveraged in downstream NLP tasks. Code and data are available at https://github.com/F-Almeman/3D-EX .
Modelling Commonsense Properties using Pre-Trained Bi-Encoders
Oct 06, 2022
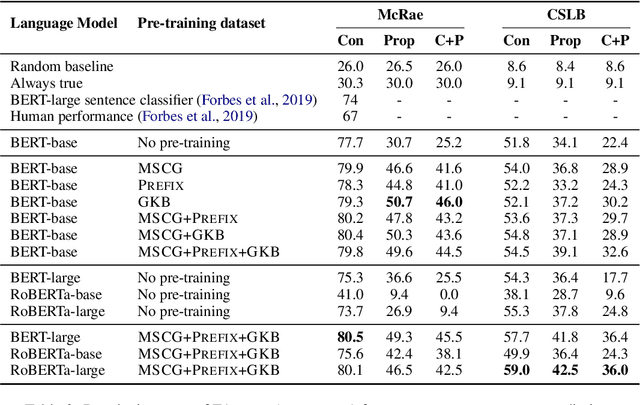
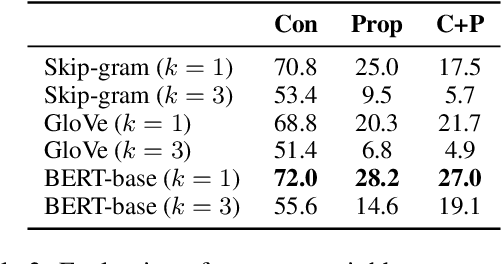
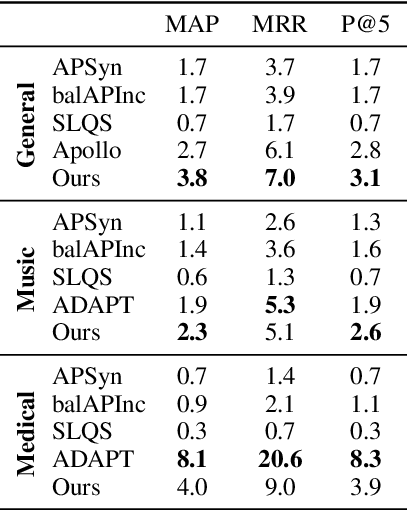
Grasping the commonsense properties of everyday concepts is an important prerequisite to language understanding. While contextualised language models are reportedly capable of predicting such commonsense properties with human-level accuracy, we argue that such results have been inflated because of the high similarity between training and test concepts. This means that models which capture concept similarity can perform well, even if they do not capture any knowledge of the commonsense properties themselves. In settings where there is no overlap between the properties that are considered during training and testing, we find that the empirical performance of standard language models drops dramatically. To address this, we study the possibility of fine-tuning language models to explicitly model concepts and their properties. In particular, we train separate concept and property encoders on two types of readily available data: extracted hyponym-hypernym pairs and generic sentences. Our experimental results show that the resulting encoders allow us to predict commonsense properties with much higher accuracy than is possible by directly fine-tuning language models. We also present experimental results for the related task of unsupervised hypernym discovery.
TweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022
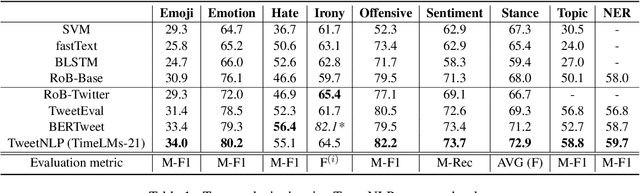
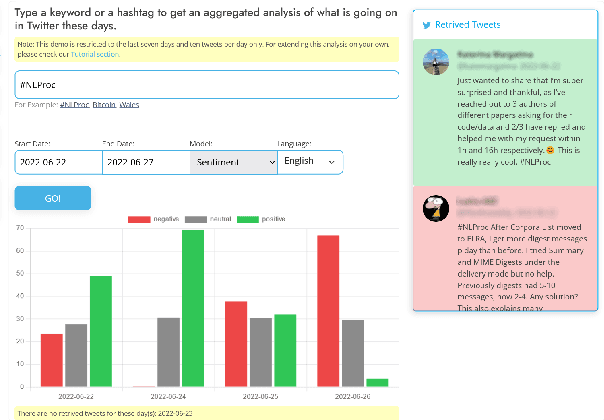

In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.
Multilingual Extraction and Categorization of Lexical Collocations with Graph-aware Transformers
May 23, 2022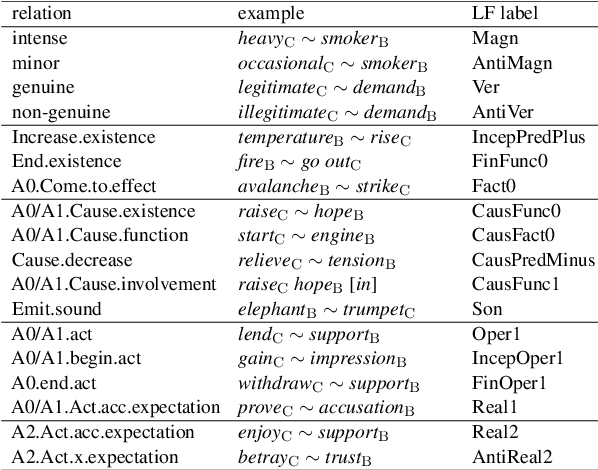
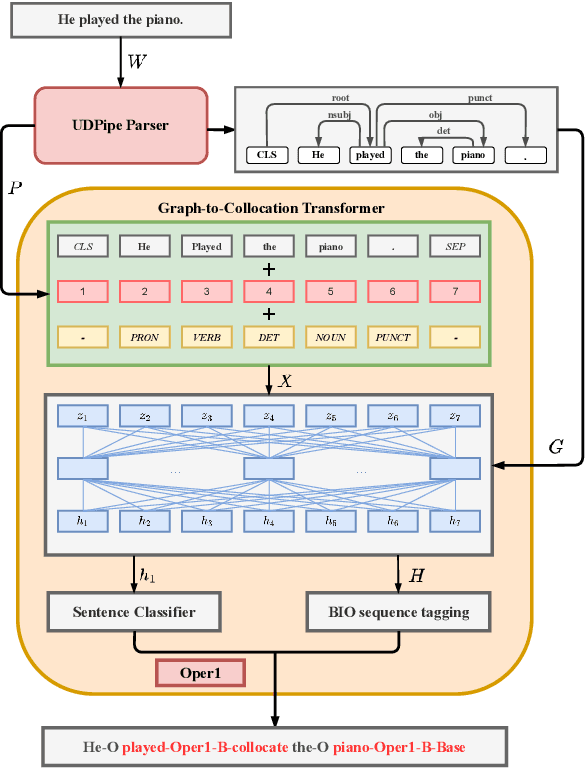
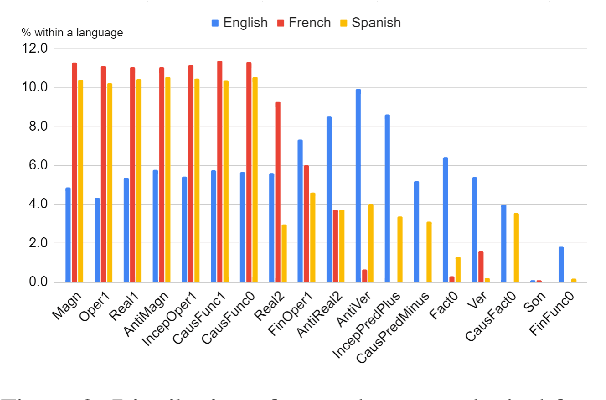
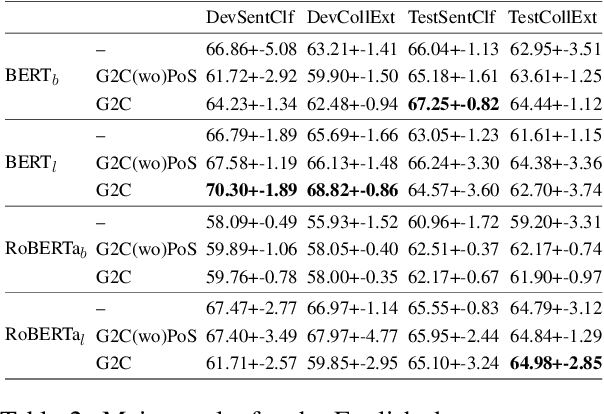
Recognizing and categorizing lexical collocations in context is useful for language learning, dictionary compilation and downstream NLP. However, it is a challenging task due to the varying degrees of frozenness lexical collocations exhibit. In this paper, we put forward a sequence tagging BERT-based model enhanced with a graph-aware transformer architecture, which we evaluate on the task of collocation recognition in context. Our results suggest that explicitly encoding syntactic dependencies in the model architecture is helpful, and provide insights on differences in collocation typification in English, Spanish and French.
Deriving Disinformation Insights from Geolocalized Twitter Callouts
Aug 06, 2021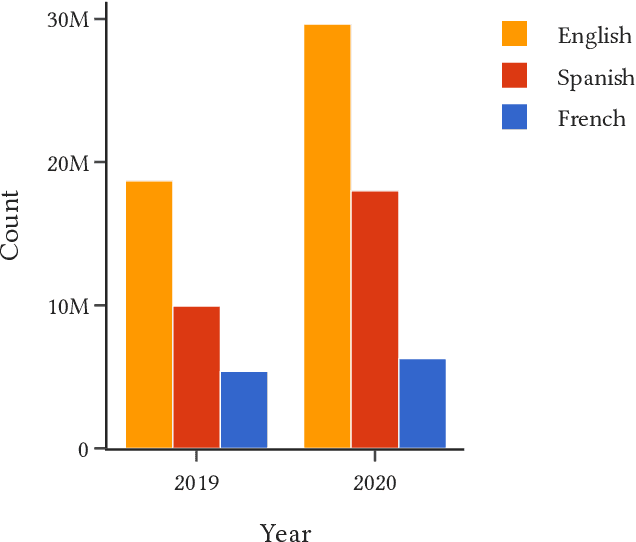


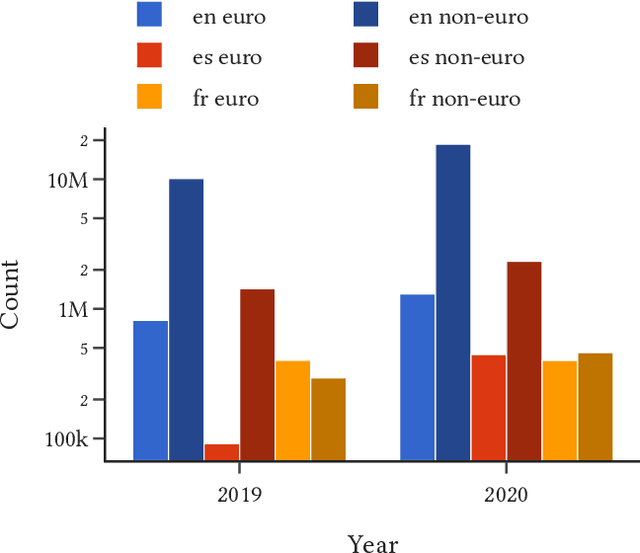
This paper demonstrates a two-stage method for deriving insights from social media data relating to disinformation by applying a combination of geospatial classification and embedding-based language modelling across multiple languages. In particular, the analysis in centered on Twitter and disinformation for three European languages: English, French and Spanish. Firstly, Twitter data is classified into European and non-European sets using BERT. Secondly, Word2vec is applied to the classified texts resulting in Eurocentric, non-Eurocentric and global representations of the data for the three target languages. This comparative analysis demonstrates not only the efficacy of the classification method but also highlights geographic, temporal and linguistic differences in the disinformation-related media. Thus, the contributions of the work are threefold: (i) a novel language-independent transformer-based geolocation method; (ii) an analytical approach that exploits lexical specificity and word embeddings to interrogate user-generated content; and (iii) a dataset of 36 million disinformation related tweets in English, French and Spanish.
Probing Pre-Trained Language Models for Disease Knowledge
Jun 14, 2021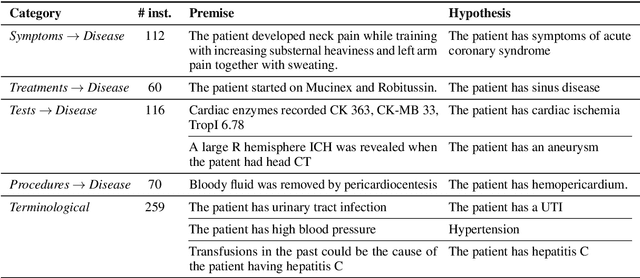
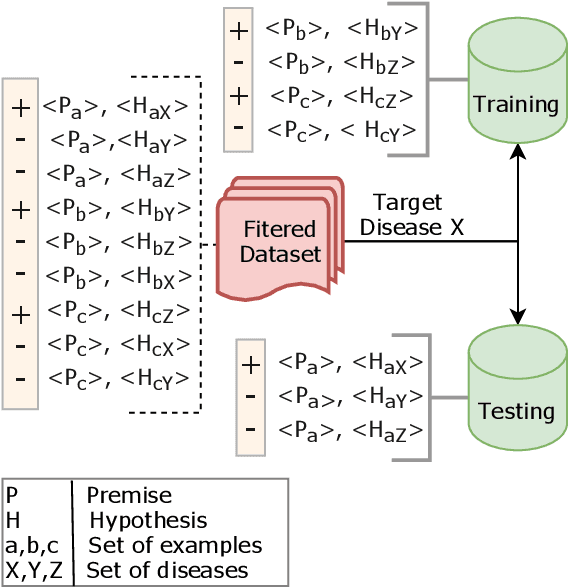
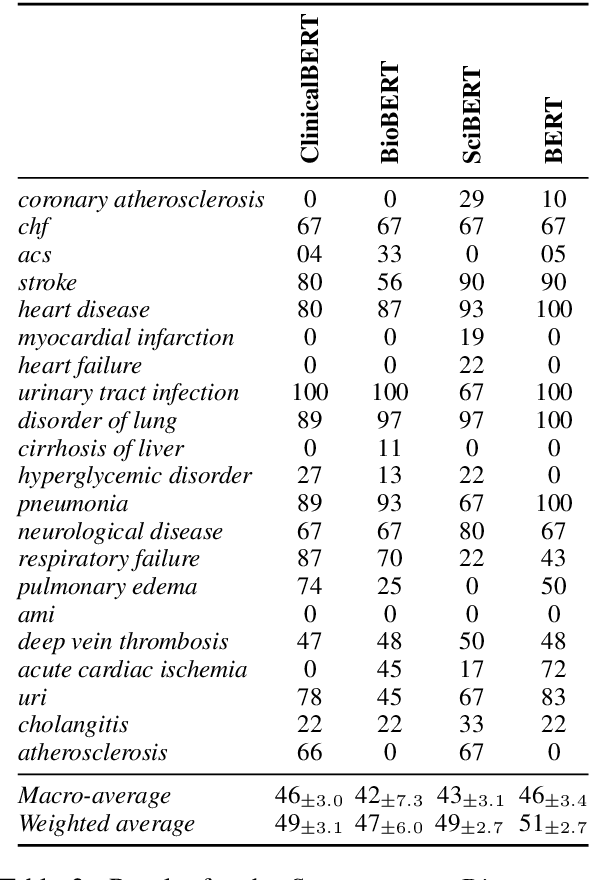
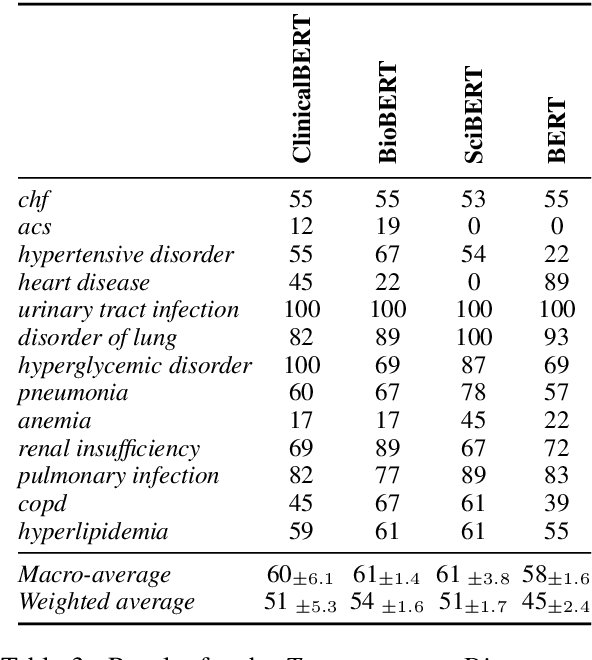
Pre-trained language models such as ClinicalBERT have achieved impressive results on tasks such as medical Natural Language Inference. At first glance, this may suggest that these models are able to perform medical reasoning tasks, such as mapping symptoms to diseases. However, we find that standard benchmarks such as MedNLI contain relatively few examples that require such forms of reasoning. To better understand the medical reasoning capabilities of existing language models, in this paper we introduce DisKnE, a new benchmark for Disease Knowledge Evaluation. To construct this benchmark, we annotated each positive MedNLI example with the types of medical reasoning that are needed. We then created negative examples by corrupting these positive examples in an adversarial way. Furthermore, we define training-test splits per disease, ensuring that no knowledge about test diseases can be learned from the training data, and we canonicalize the formulation of the hypotheses to avoid the presence of artefacts. This leads to a number of binary classification problems, one for each type of reasoning and each disease. When analysing pre-trained models for the clinical/biomedical domain on the proposed benchmark, we find that their performance drops considerably.
BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?
Jun 03, 2021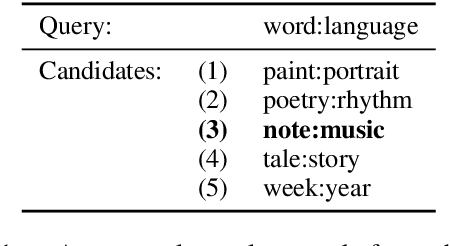
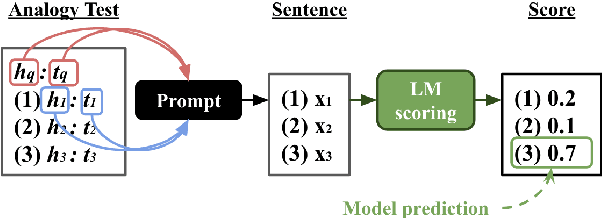
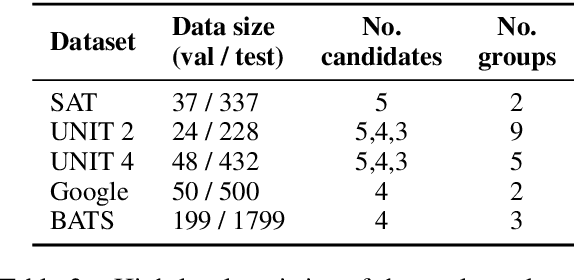

Analogies play a central role in human commonsense reasoning. The ability to recognize analogies such as "eye is to seeing what ear is to hearing", sometimes referred to as analogical proportions, shape how we structure knowledge and understand language. Surprisingly, however, the task of identifying such analogies has not yet received much attention in the language model era. In this paper, we analyze the capabilities of transformer-based language models on this unsupervised task, using benchmarks obtained from educational settings, as well as more commonly used datasets. We find that off-the-shelf language models can identify analogies to a certain extent, but struggle with abstract and complex relations, and results are highly sensitive to model architecture and hyperparameters. Overall the best results were obtained with GPT-2 and RoBERTa, while configurations using BERT were not able to outperform word embedding models. Our results raise important questions for future work about how, and to what extent, pre-trained language models capture knowledge about abstract semantic relations.