 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision and Gender Biases in Large Language Models: A Behavioral Economic Perspective
Nov 15, 2025Large language models (LLMs) increasingly mediate economic and organisational processes, from automated customer support and recruitment to investment advice and policy analysis. These systems are often assumed to embody rational decision making free from human error; yet they are trained on human language corpora that may embed cognitive and social biases. This study investigates whether advanced LLMs behave as rational agents or whether they reproduce human behavioural tendencies when faced with classic decision problems. Using two canonical experiments in behavioural economics, the ultimatum game and a gambling game, we elicit decisions from two state of the art models, Google Gemma7B and Qwen, under neutral and gender conditioned prompts. We estimate parameters of inequity aversion and loss-aversion and compare them with human benchmarks. The models display attenuated but persistent deviations from rationality, including moderate fairness concerns, mild loss aversion, and subtle gender conditioned differences.
Drift Estimation with Graphical Models
Feb 02, 2021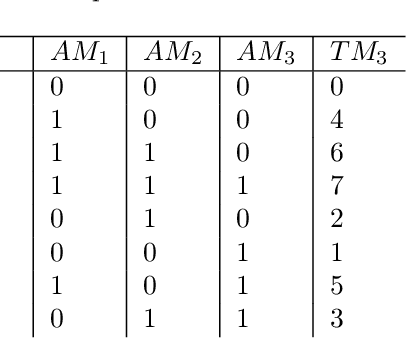
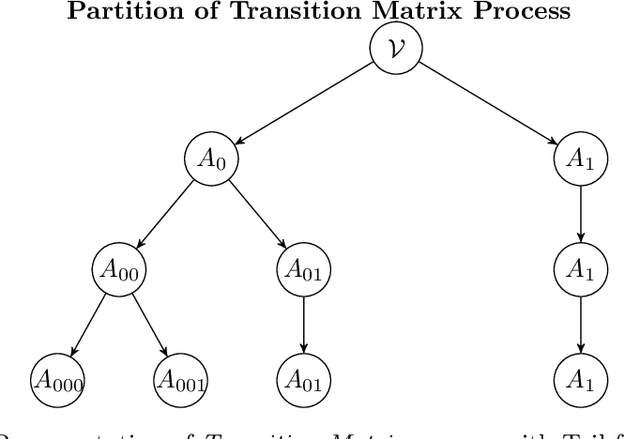
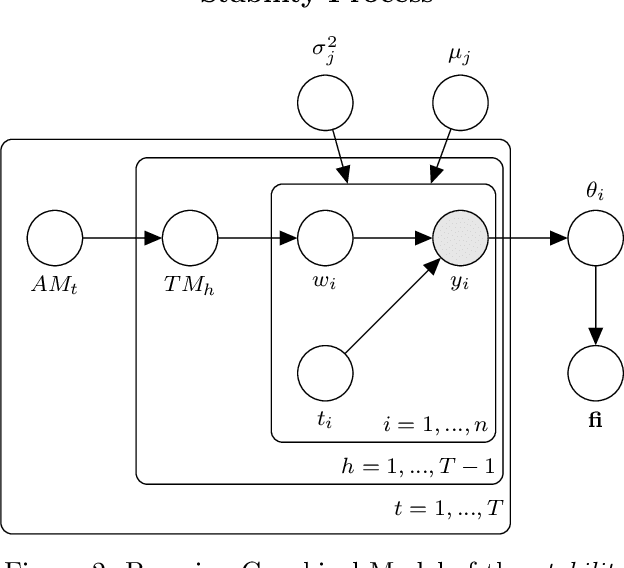

This paper deals with the issue of concept drift in supervised machine learn-ing. We make use of graphical models to elicit the visible structure of the dataand we infer from there changes in the hidden context. Differently from previous concept-drift detection methods, this application does not depend on the supervised machine learning model in use for a specific target variable, but it tries to assess the concept drift as independent characteristic of the evolution of a dataset. Specifically, we investigate how a graphical model evolves by looking at the creation of new links and the disappearing of existing ones in different time periods. The paper suggests a method that highlights the changes and eventually produce a metric to evaluate the stability over time. The paper evaluate the method with real world data on the Australian Electric market.
A Bimodal Network Approach to Model Topic Dynamics
Sep 27, 2017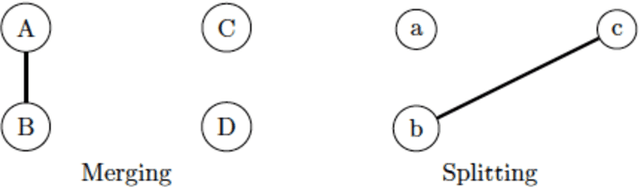
This paper presents an intertemporal bimodal network to analyze the evolution of the semantic content of a scientific field within the framework of topic modeling, namely using the Latent Dirichlet Allocation (LDA). The main contribution is the conceptualization of the topic dynamics and its formalization and codification into an algorithm. To benchmark the effectiveness of this approach, we propose three indexes which track the transformation of topics over time, their rate of birth and death, and the novelty of their content. Applying the LDA, we test the algorithm both on a controlled experiment and on a corpus of several thousands of scientific papers over a period of more than 100 years which account for the history of the economic thought.