 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Cascaded Multimodal Speech Translation
Nov 08, 2019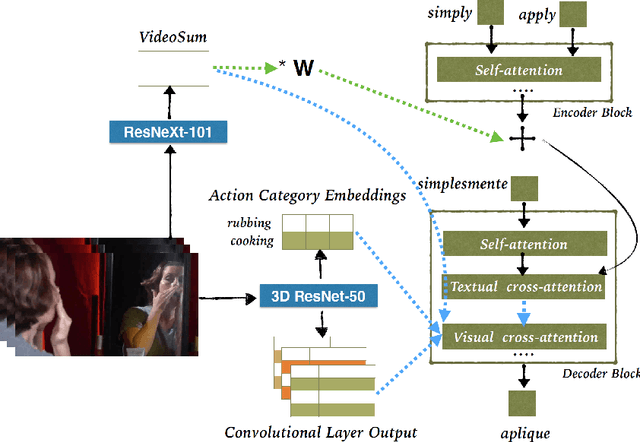
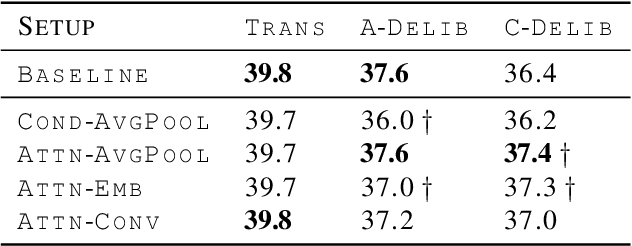
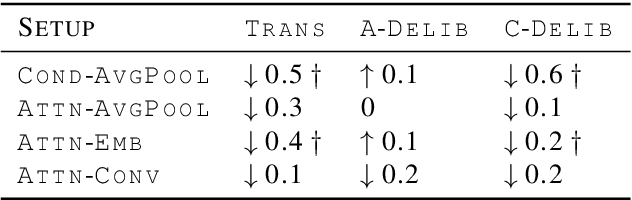
This paper describes the cascaded multimodal speech translation systems developed by Imperial College London for the IWSLT 2019 evaluation campaign. The architecture consists of an automatic speech recognition (ASR) system followed by a Transformer-based multimodal machine translation (MMT) system. While the ASR component is identical across the experiments, the MMT model varies in terms of the way of integrating the visual context (simple conditioning vs. attention), the type of visual features exploited (pooled, convolutional, action categories) and the underlying architecture. For the latter, we explore both the canonical transformer and its deliberation version with additive and cascade variants which differ in how they integrate the textual attention. Upon conducting extensive experiments, we found that (i) the explored visual integration schemes often harm the translation performance for the transformer and additive deliberation, but considerably improve the cascade deliberation; (ii) the transformer and cascade deliberation integrate the visual modality better than the additive deliberation, as shown by the incongruence analysis.
Imperial College London Submission to VATEX Video Captioning Task
Oct 16, 2019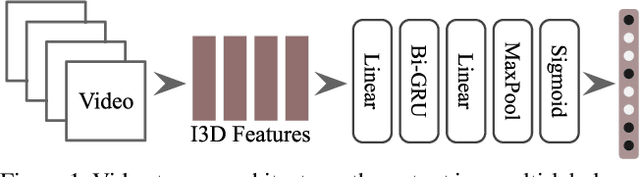
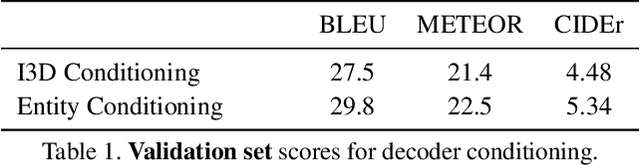
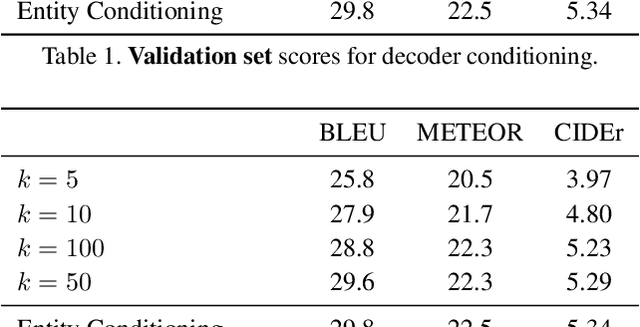
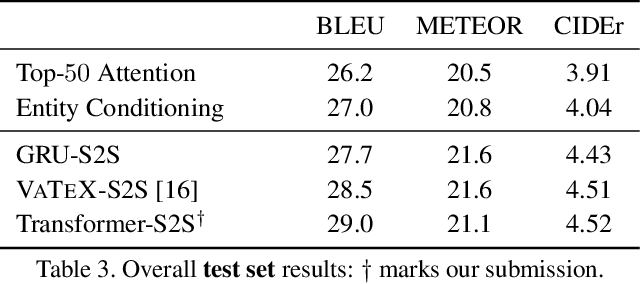
This paper describes the Imperial College London team's submission to the 2019' VATEX video captioning challenge, where we first explore two sequence-to-sequence models, namely a recurrent (GRU) model and a transformer model, which generate captions from the I3D action features. We then investigate the effect of dropping the encoder and the attention mechanism and instead conditioning the GRU decoder over two different vectorial representations: (i) a max-pooled action feature vector and (ii) the output of a multi-label classifier trained to predict visual entities from the action features. Our baselines achieved scores comparable to the official baseline. Conditioning over entity predictions performed substantially better than conditioning on the max-pooled feature vector, and only marginally worse than the GRU-based sequence-to-sequence baseline.
Improving Neural Machine Translation Robustness via Data Augmentation: Beyond Back Translation
Oct 14, 2019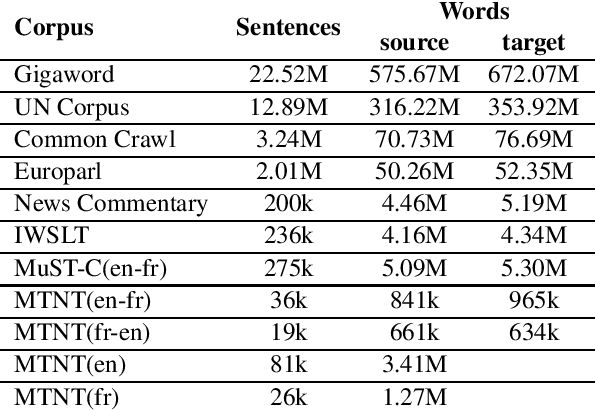
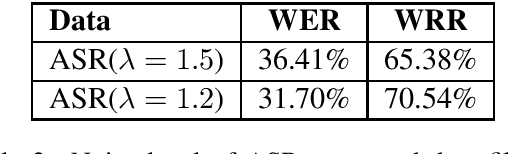
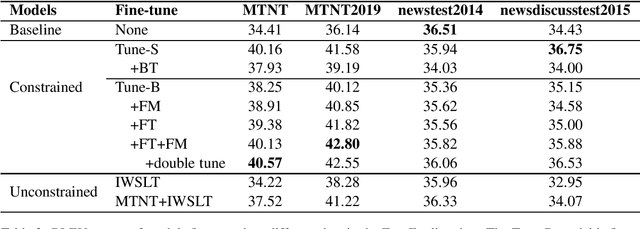
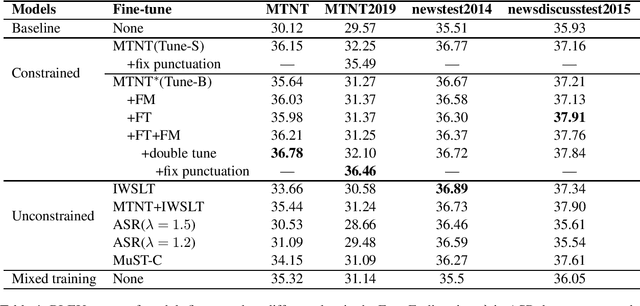
Neural Machine Translation (NMT) models have been proved strong when translating clean texts, but they are very sensitive to noise in the input. Improving NMT models robustness can be seen as a form of "domain" adaption to noise. The recently created Machine Translation on Noisy Text task corpus provides noisy-clean parallel data for a few language pairs, but this data is very limited in size and diversity. The state-of-the-art approaches are heavily dependent on large volumes of back-translated data. This paper has two main contributions: Firstly, we propose new data augmentation methods to extend limited noisy data and further improve NMT robustness to noise while keeping the models small. Secondly, we explore the effect of utilizing noise from external data in the form of speech transcripts and show that it could help robustness.
Estimating post-editing effort: a study on human judgements, task-based and reference-based metrics of MT quality
Oct 14, 2019
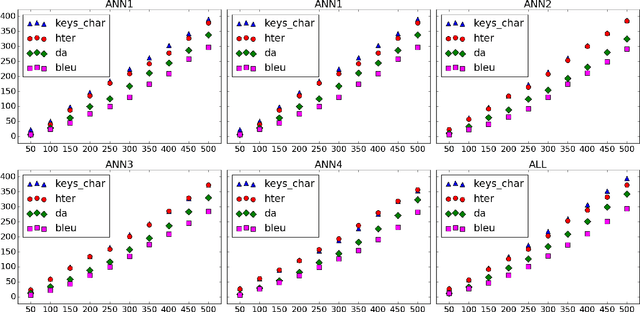

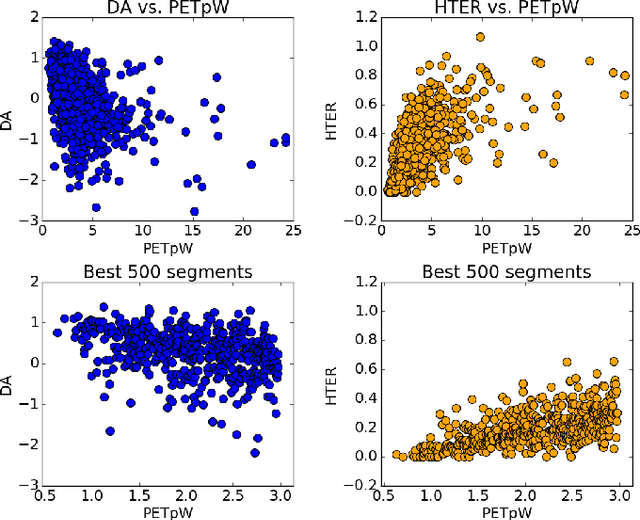
Devising metrics to assess translation quality has always been at the core of machine translation (MT) research. Traditional automatic reference-based metrics, such as BLEU, have shown correlations with human judgements of adequacy and fluency and have been paramount for the advancement of MT system development. Crowd-sourcing has popularised and enabled the scalability of metrics based on human judgements, such as subjective direct assessments (DA) of adequacy, that are believed to be more reliable than reference-based automatic metrics. Finally, task-based measurements, such as post-editing time, are expected to provide a more detailed evaluation of the usefulness of translations for a specific task. Therefore, while DA averages adequacy judgements to obtain an appraisal of (perceived) quality independently of the task, and reference-based automatic metrics try to objectively estimate quality also in a task-independent way, task-based metrics are measurements obtained either during or after performing a specific task. In this paper we argue that, although expensive, task-based measurements are the most reliable when estimating MT quality in a specific task; in our case, this task is post-editing. To that end, we report experiments on a dataset with newly-collected post-editing indicators and show their usefulness when estimating post-editing effort. Our results show that task-based metrics comparing machine-translated and post-edited versions are the best at tracking post-editing effort, as expected. These metrics are followed by DA, and then by metrics comparing the machine-translated version and independent references. We suggest that MT practitioners should be aware of these differences and acknowledge their implications when deciding how to evaluate MT for post-editing purposes.
EASSE: Easier Automatic Sentence Simplification Evaluation
Sep 13, 2019

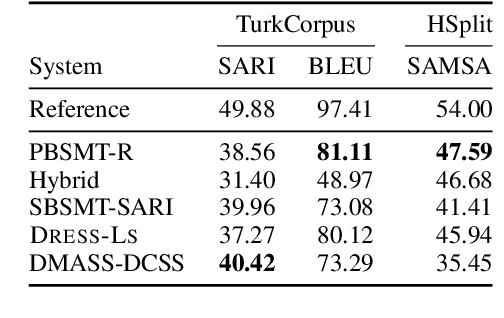
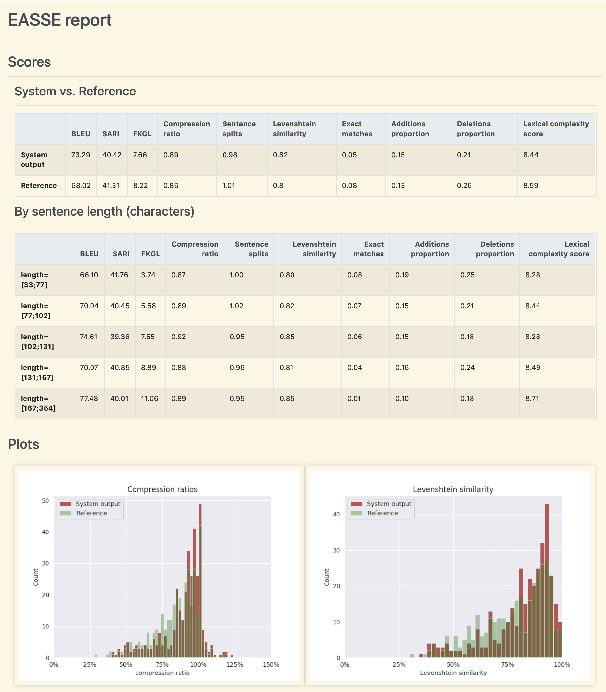
We introduce EASSE, a Python package aiming to facilitate and standardise automatic evaluation and comparison of Sentence Simplification (SS) systems. EASSE provides a single access point to a broad range of evaluation resources: standard automatic metrics for assessing SS outputs (e.g. SARI), word-level accuracy scores for certain simplification transformations, reference-independent quality estimation features (e.g. compression ratio), and standard test data for SS evaluation (e.g. TurkCorpus). Finally, EASSE generates easy-to-visualise reports on the various metrics and features above and on how a particular SS output fares against reference simplifications. Through experiments, we show that these functionalities allow for better comparison and understanding of the performance of SS systems.
Phrase Localization Without Paired Training Examples
Aug 20, 2019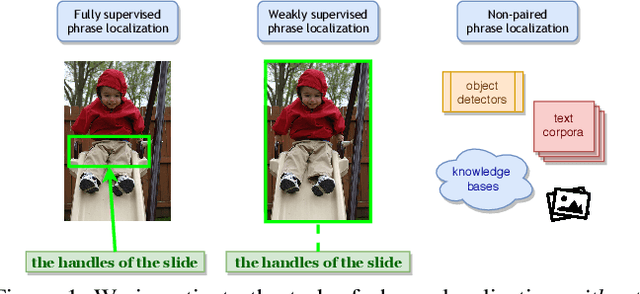
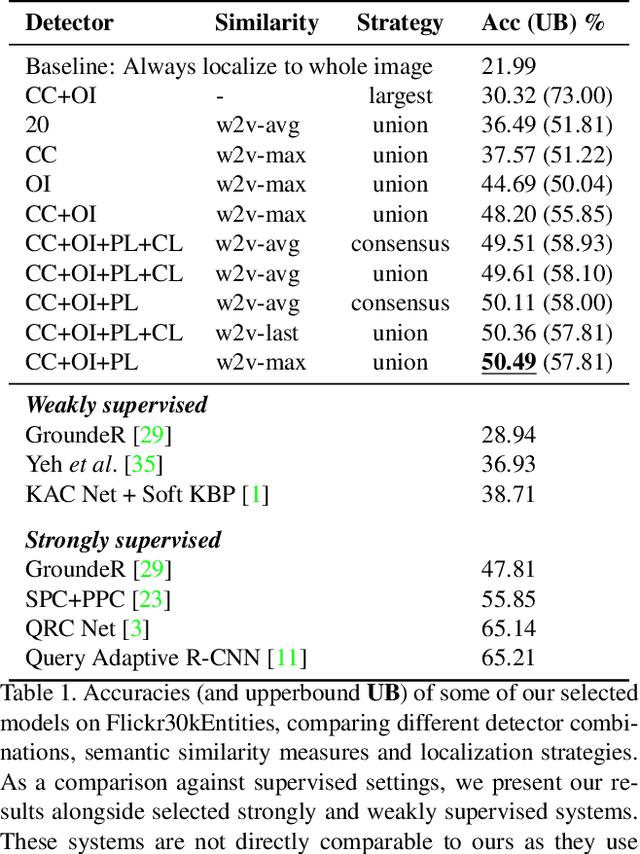
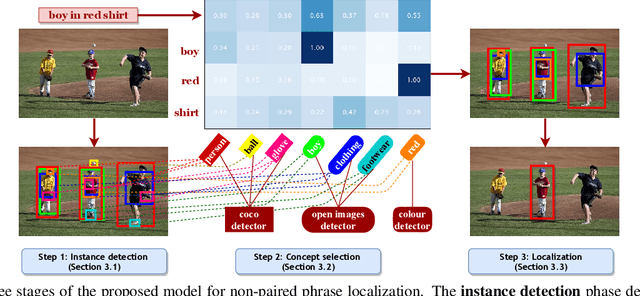
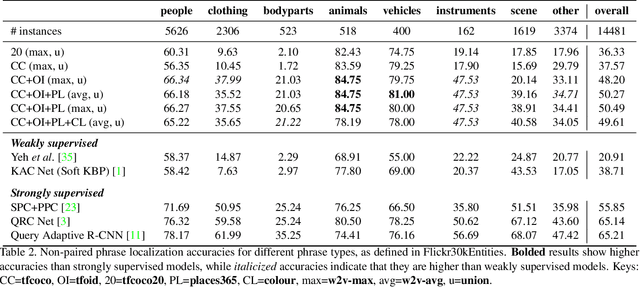
Localizing phrases in images is an important part of image understanding and can be useful in many applications that require mappings between textual and visual information. Existing work attempts to learn these mappings from examples of phrase-image region correspondences (strong supervision) or from phrase-image pairs (weak supervision). We postulate that such paired annotations are unnecessary, and propose the first method for the phrase localization problem where neither training procedure nor paired, task-specific data is required. Our method is simple but effective: we use off-the-shelf approaches to detect objects, scenes and colours in images, and explore different approaches to measure semantic similarity between the categories of detected visual elements and words in phrases. Experiments on two well-known phrase localization datasets show that this approach surpasses all weakly supervised methods by a large margin and performs very competitively to strongly supervised methods, and can thus be considered a strong baseline to the task. The non-paired nature of our method makes it applicable to any domain and where no paired phrase localization annotation is available.
Predicting Actions to Help Predict Translations
Aug 18, 2019
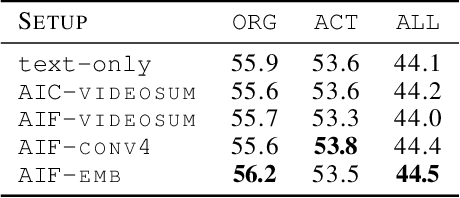


We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.
Is artificial data useful for biomedical Natural Language Processing algorithms?
Aug 07, 2019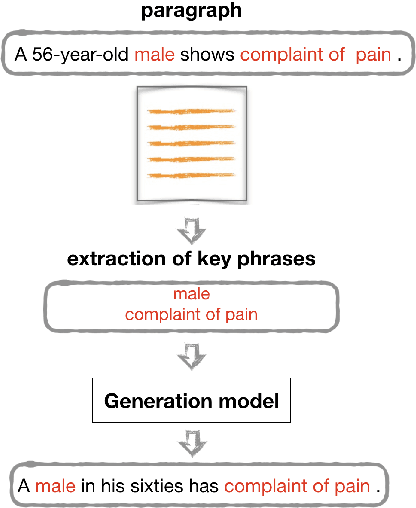

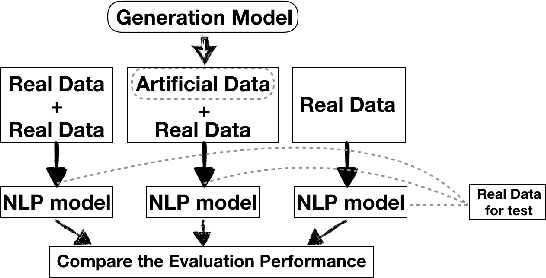

A major obstacle to the development of Natural Language Processing (NLP) methods in the biomedical domain is data accessibility. This problem can be addressed by generating medical data artificially. Most previous studies have focused on the generation of short clinical text, and evaluation of the data utility has been limited. We propose a generic methodology to guide the generation of clinical text with key phrases. We use the artificial data as additional training data in two key biomedical NLP tasks: text classification and temporal relation extraction. We show that artificially generated training data used in conjunction with real training data can lead to performance boosts for data-greedy neural network algorithms. We also demonstrate the usefulness of the generated data for NLP setups where it fully replaces real training data.
VIFIDEL: Evaluating the Visual Fidelity of Image Descriptions
Jul 22, 2019
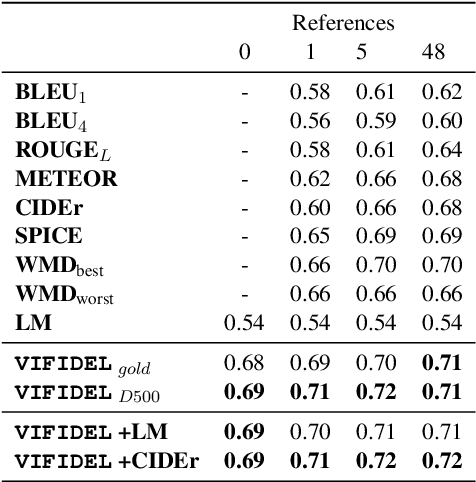
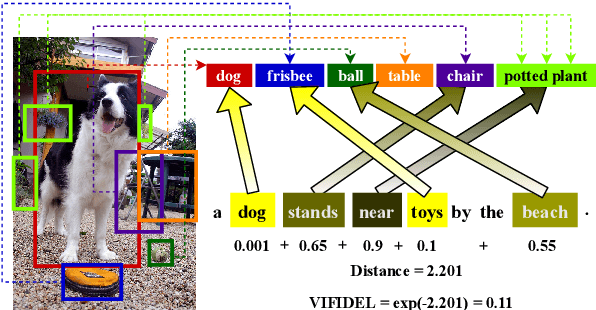
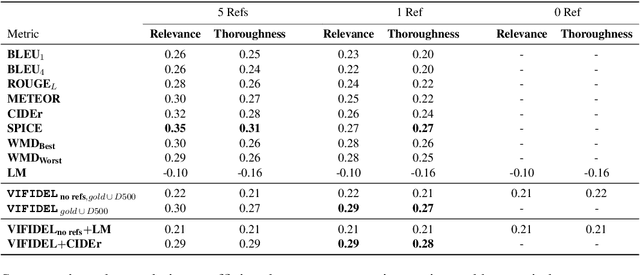
We address the task of evaluating image description generation systems. We propose a novel image-aware metric for this task: VIFIDEL. It estimates the faithfulness of a generated caption with respect to the content of the actual image, based on the semantic similarity between labels of objects depicted in images and words in the description. The metric is also able to take into account the relative importance of objects mentioned in human reference descriptions during evaluation. Even if these human reference descriptions are not available, VIFIDEL can still reliably evaluate system descriptions. The metric achieves high correlation with human judgments on two well-known datasets and is competitive with metrics that depend on human references
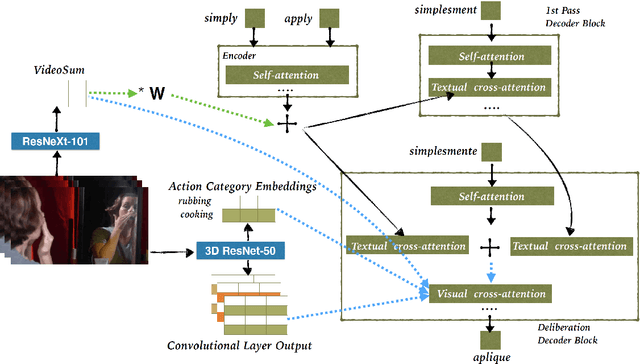
Distilling Translations with Visual Awareness
Jun 18, 2019

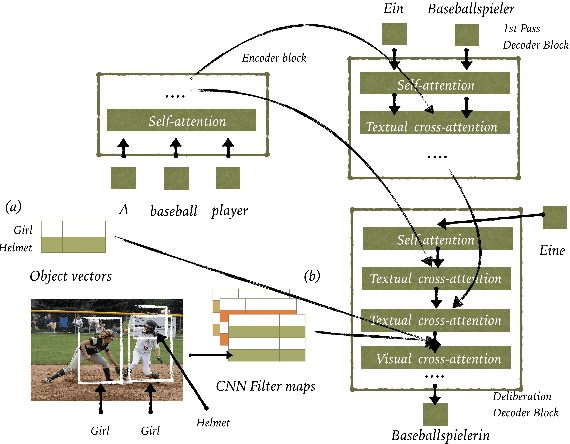
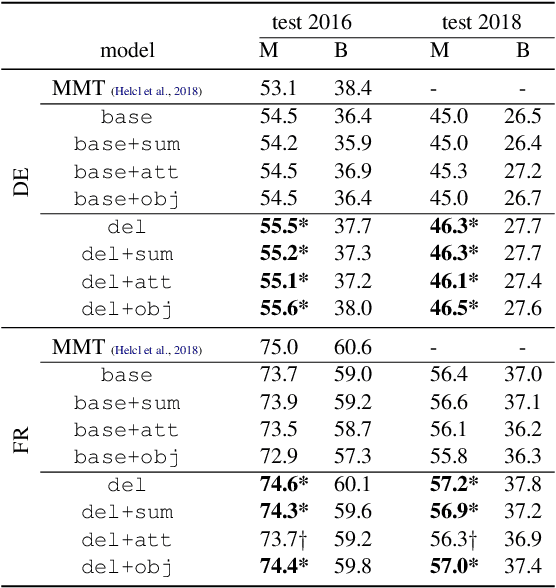
Previous work on multimodal machine translation has shown that visual information is only needed in very specific cases, for example in the presence of ambiguous words where the textual context is not sufficient. As a consequence, models tend to learn to ignore this information. We propose a translate-and-refine approach to this problem where images are only used by a second stage decoder. This approach is trained jointly to generate a good first draft translation and to improve over this draft by (i) making better use of the target language textual context (both left and right-side contexts) and (ii) making use of visual context. This approach leads to the state of the art results. Additionally, we show that it has the ability to recover from erroneous or missing words in the source language.