 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise LoRA fine-tuning: a similarity metric approach
Feb 05, 2026Pre-training Large Language Models (LLMs) on web-scale datasets becomes fundamental for advancing general-purpose AI. In contrast, enhancing their predictive performance on downstream tasks typically involves adapting their knowledge through fine-tuning. Parameter-efficient fine-tuning techniques, such as Low-Rank Adaptation (LoRA), aim to reduce the computational cost of this process by freezing the pre-trained model and updating a smaller number of parameters. In comparison to full fine-tuning, these methods achieve over 99\% reduction in trainable parameter count, depending on the configuration. Unfortunately, such a reduction may prove insufficient as LLMs continue to grow in scale. In this work, we address the previous problem by systematically selecting only a few layers to fine-tune using LoRA or its variants. We argue that not all layers contribute equally to the model adaptation. Leveraging this, we identify the most relevant layers to fine-tune by measuring their contribution to changes in internal representations. Our method is orthogonal to and readily compatible with existing low-rank adaptation techniques. We reduce the trainable parameters in LoRA-based techniques by up to 50\%, while maintaining the predictive performance across different models and tasks. Specifically, on encoder-only architectures, this reduction in trainable parameters leads to a negligible predictive performance drop on the GLUE benchmark. On decoder-only architectures, we achieve a small drop or even improvements in the predictive performance on mathematical problem-solving capabilities and coding tasks. Finally, this effectiveness extends to multimodal models, for which we also observe competitive results relative to fine-tuning with LoRA modules in all layers. Code is available at: https://github.com/c2d-usp/Layer-wise-LoRA-with-CKA
Compressing LLMs with MoP: Mixture of Pruners
Feb 05, 2026The high computational demands of Large Language Models (LLMs) motivate methods that reduce parameter count and accelerate inference. In response, model pruning emerges as an effective strategy, yet current methods typically focus on a single dimension-depth or width. We introduce MoP (Mixture of Pruners), an iterative framework that unifies these dimensions. At each iteration, MoP generates two branches-pruning in depth versus pruning in width-and selects a candidate to advance the path. On LLaMA-2 and LLaMA-3, MoP advances the frontier of structured pruning, exceeding the accuracy of competing methods across a broad set of compression regimes. It also consistently outperforms depth-only and width-only pruning. Furthermore, MoP translates structural pruning into real speedup, reducing end-to-end latency by 39% at 40% compression. Finally, extending MoP to the vision-language model LLaVA-1.5, we notably improve computational efficiency and demonstrate that text-only recovery fine-tuning can restore performance even on visual tasks.
Efficient LLMs with AMP: Attention Heads and MLP Pruning
Apr 29, 2025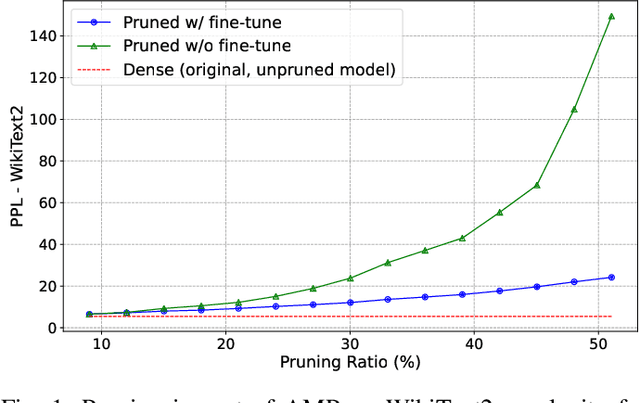
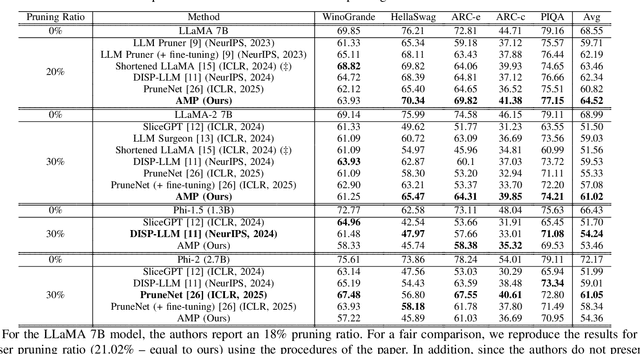
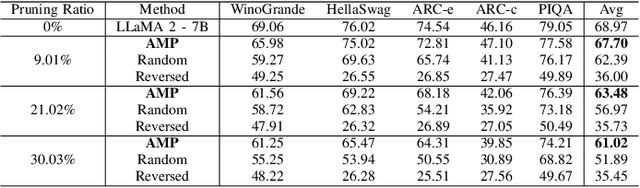

Deep learning drives a new wave in computing systems and triggers the automation of increasingly complex problems. In particular, Large Language Models (LLMs) have significantly advanced cognitive tasks, often matching or even surpassing human-level performance. However, their extensive parameters result in high computational costs and slow inference, posing challenges for deployment in resource-limited settings. Among the strategies to overcome the aforementioned challenges, pruning emerges as a successful mechanism since it reduces model size while maintaining predictive ability. In this paper, we introduce AMP: Attention Heads and MLP Pruning, a novel structured pruning method that efficiently compresses LLMs by removing less critical structures within Multi-Head Attention (MHA) and Multilayer Perceptron (MLP). By projecting the input data onto weights, AMP assesses structural importance and overcomes the limitations of existing techniques, which often fall short in flexibility or efficiency. In particular, AMP surpasses the current state-of-the-art on commonsense reasoning tasks by up to 1.49 percentage points, achieving a 30% pruning ratio with minimal impact on zero-shot task performance. Moreover, AMP also improves inference speeds, making it well-suited for deployment in resource-constrained environments. We confirm the flexibility of AMP on different families of LLMs, including LLaMA and Phi.