 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucas Liebenwein
Data-Dependent Coresets for Compressing Neural Networks with Applications to Generalization Bounds
Sep 05, 2018
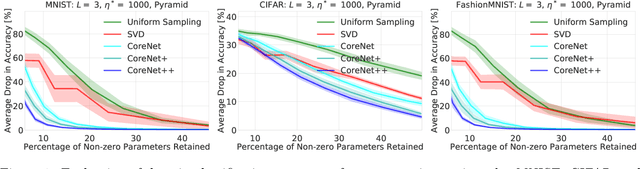
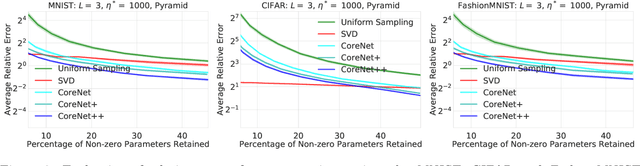
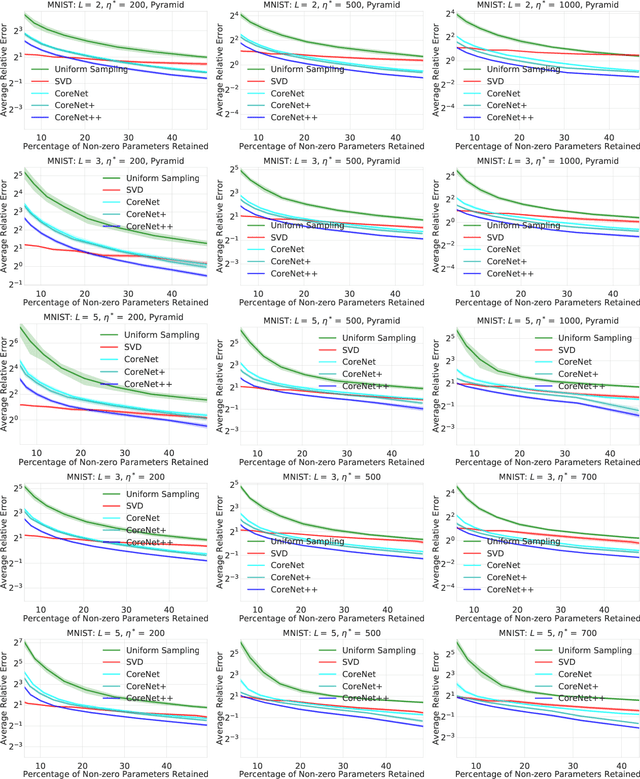
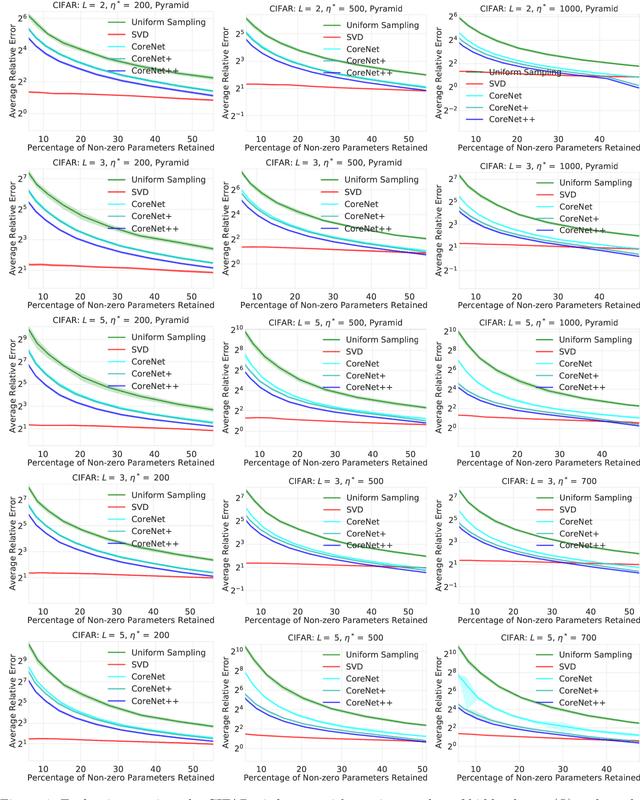
We present an efficient coresets-based neural network compression algorithm that provably sparsifies the parameters of a trained fully-connected neural network in a manner that approximately preserves the network's output. Our approach is based on an importance sampling scheme that judiciously defines a sampling distribution over the neural network parameters, and as a result, retains parameters of high importance while discarding redundant ones. We leverage a novel, empirical notion of sensitivity and extend traditional coreset constructions to the application of compressing parameters. Our theoretical analysis establishes guarantees on the size and accuracy of the resulting compressed neural network and gives rise to new generalization bounds that may provide novel insights on the generalization properties of neural networks. We demonstrate the practical effectiveness of our algorithm on a variety of neural network configurations and real-world data sets.
Training Support Vector Machines using Coresets
Nov 10, 2017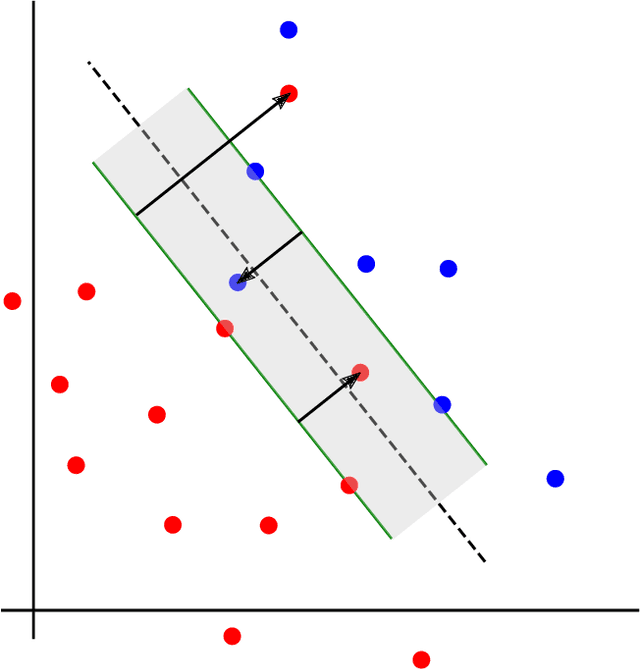
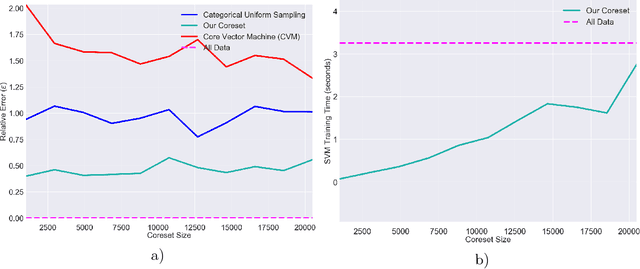
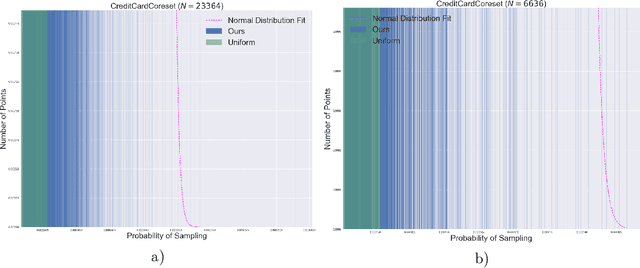
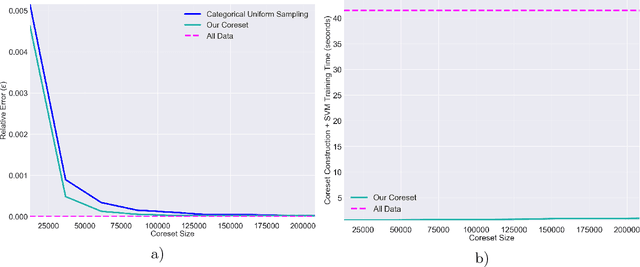
We present a novel coreset construction algorithm for solving classification tasks using Support Vector Machines (SVMs) in a computationally efficient manner. A coreset is a weighted subset of the original data points that provably approximates the original set. We show that coresets of size polylogarithmic in $n$ and polynomial in $d$ exist for a set of $n$ input points with $d$ features and present an $(\epsilon,\delta)$-FPRAS for constructing coresets for scalable SVM training. Our method leverages the insight that data points are often redundant and uses an importance sampling scheme based on the sensitivity of each data point to construct coresets efficiently. We evaluate the performance of our algorithm in accelerating SVM training against real-world data sets and compare our algorithm to state-of-the-art coreset approaches. Our empirical results show that our approach outperforms a state-of-the-art coreset approach and uniform sampling in enabling computational speedups while achieving low approximation error.