 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiachronic Stereo Matching for Multi-Date Satellite Imagery
Jan 30, 2026Recent advances in image-based satellite 3D reconstruction have progressed along two complementary directions. On one hand, multi-date approaches using NeRF or Gaussian-splatting jointly model appearance and geometry across many acquisitions, achieving accurate reconstructions on opportunistic imagery with numerous observations. On the other hand, classical stereoscopic reconstruction pipelines deliver robust and scalable results for simultaneous or quasi-simultaneous image pairs. However, when the two images are captured months apart, strong seasonal, illumination, and shadow changes violate standard stereoscopic assumptions, causing existing pipelines to fail. This work presents the first Diachronic Stereo Matching method for satellite imagery, enabling reliable 3D reconstruction from temporally distant pairs. Two advances make this possible: (1) fine-tuning a state-of-the-art deep stereo network that leverages monocular depth priors, and (2) exposing it to a dataset specifically curated to include a diverse set of diachronic image pairs. In particular, we start from a pretrained MonSter model, trained initially on a mix of synthetic and real datasets such as SceneFlow and KITTI, and fine-tune it on a set of stereo pairs derived from the DFC2019 remote sensing challenge. This dataset contains both synchronic and diachronic pairs under diverse seasonal and illumination conditions. Experiments on multi-date WorldView-3 imagery demonstrate that our approach consistently surpasses classical pipelines and unadapted deep stereo models on both synchronic and diachronic settings. Fine-tuning on temporally diverse images, together with monocular priors, proves essential for enabling 3D reconstruction from previously incompatible acquisition dates. Left image (winter) Right image (autumn) DSM geometry Ours (1.23 m) Zero-shot (3.99 m) LiDAR GT Figure 1. Output geometry for a winter-autumn image pair from Omaha (OMA 331 test scene). Our method recovers accurate geometry despite the diachronic nature of the pair, exhibiting strong appearance changes, which cause existing zero-shot methods to fail. Missing values due to perspective shown in black. Mean altitude error in parentheses; lower is better.
EOGS: Gaussian Splatting for Earth Observation
Dec 17, 2024



Recently, Gaussian splatting has emerged as a strong alternative to NeRF, demonstrating impressive 3D modeling capabilities while requiring only a fraction of the training and rendering time. In this paper, we show how the standard Gaussian splatting framework can be adapted for remote sensing, retaining its high efficiency. This enables us to achieve state-of-the-art performance in just a few minutes, compared to the day-long optimization required by the best-performing NeRF-based Earth observation methods. The proposed framework incorporates remote-sensing improvements from EO-NeRF, such as radiometric correction and shadow modeling, while introducing novel components, including sparsity, view consistency, and opacity regularizations.
MotionCraft: Physics-based Zero-Shot Video Generation
May 22, 2024



Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
Deep 3D World Models for Multi-Image Super-Resolution Beyond Optical Flow
Jan 30, 2024



Multi-image super-resolution (MISR) allows to increase the spatial resolution of a low-resolution (LR) acquisition by combining multiple images carrying complementary information in the form of sub-pixel offsets in the scene sampling, and can be significantly more effective than its single-image counterpart. Its main difficulty lies in accurately registering and fusing the multi-image information. Currently studied settings, such as burst photography, typically involve assumptions of small geometric disparity between the LR images and rely on optical flow for image registration. We study a MISR method that can increase the resolution of sets of images acquired with arbitrary, and potentially wildly different, camera positions and orientations, generalizing the currently studied MISR settings. Our proposed model, called EpiMISR, moves away from optical flow and explicitly uses the epipolar geometry of the acquisition process, together with transformer-based processing of radiance feature fields to substantially improve over state-of-the-art MISR methods in presence of large disparities in the LR images.
Improving Neural Predictivity in the Visual Cortex with Gated Recurrent Connections
Mar 22, 2022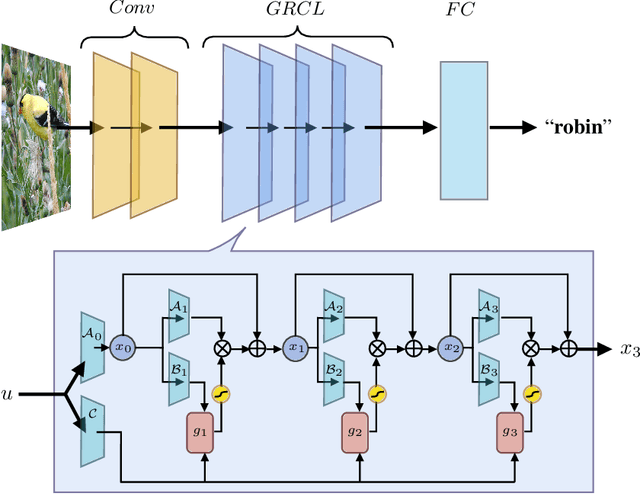
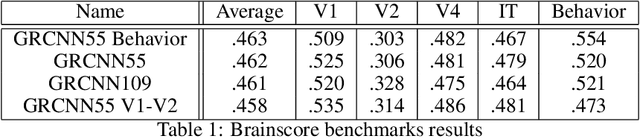
Computational models of vision have traditionally been developed in a bottom-up fashion, by hierarchically composing a series of straightforward operations - i.e. convolution and pooling - with the aim of emulating simple and complex cells in the visual cortex, resulting in the introduction of deep convolutional neural networks (CNNs). Nevertheless, data obtained with recent neuronal recording techniques support that the nature of the computations carried out in the ventral visual stream is not completely captured by current deep CNN models. To fill the gap between the ventral visual stream and deep models, several benchmarks have been designed and organized into the Brain-Score platform, granting a way to perform multi-layer (V1, V2, V4, IT) and behavioral comparisons between the two counterparts. In our work, we aim to shift the focus on architectures that take into account lateral recurrent connections, a ubiquitous feature of the ventral visual stream, to devise adaptive receptive fields. Through recurrent connections, the input s long-range spatial dependencies can be captured in a local multi-step fashion and, as introduced with Gated Recurrent CNNs (GRCNN), the unbounded expansion of the neuron s receptive fields can be modulated through the use of gates. In order to increase the robustness of our approach and the biological fidelity of the activations, we employ specific data augmentation techniques in line with several of the scoring benchmarks. Enforcing some form of invariance, through heuristics, was found to be beneficial for better neural predictivity.