 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Leveraging Industrial Equipment Structure: An application to Remaining Useful Life Estimation
Jun 30, 2020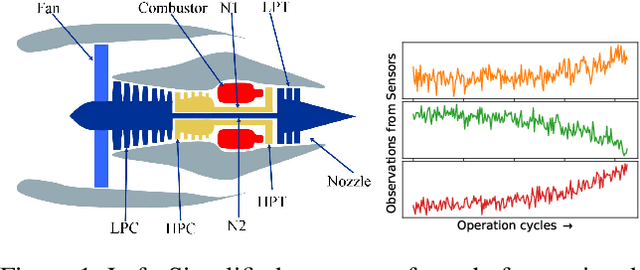
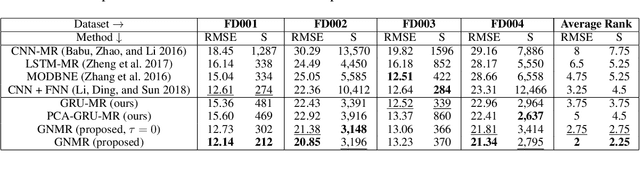
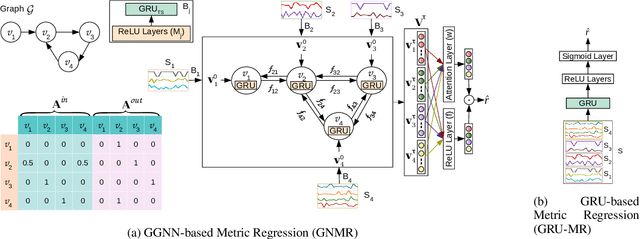

Automated equipment health monitoring from streaming multisensor time-series data can be used to enable condition-based maintenance, avoid sudden catastrophic failures, and ensure high operational availability. We note that most complex machinery has a well-documented and readily accessible underlying structure capturing the inter-dependencies between sub-systems or modules. Deep learning models such as those based on recurrent neural networks (RNNs) or convolutional neural networks (CNNs) fail to explicitly leverage this potentially rich source of domain-knowledge into the learning procedure. In this work, we propose to capture the structure of a complex equipment in the form of a graph, and use graph neural networks (GNNs) to model multi-sensor time-series data. Using remaining useful life estimation as an application task, we evaluate the advantage of incorporating the graph structure via GNNs on the publicly available turbofan engine benchmark dataset. We observe that the proposed GNN-based RUL estimation model compares favorably to several strong baselines from literature such as those based on RNNs and CNNs. Additionally, we observe that the learned network is able to focus on the module (node) with impending failure through a simple attention mechanism, potentially paving the way for actionable diagnosis.
MultiMBNN: Matched and Balanced Causal Inference with Neural Networks
Apr 29, 2020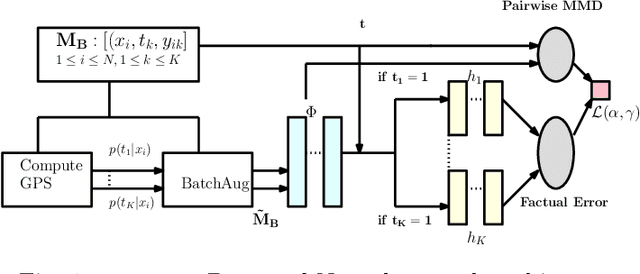
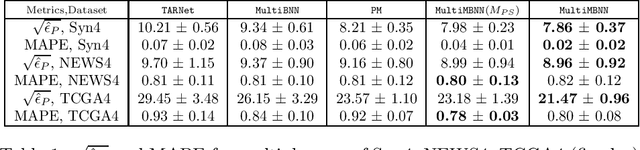
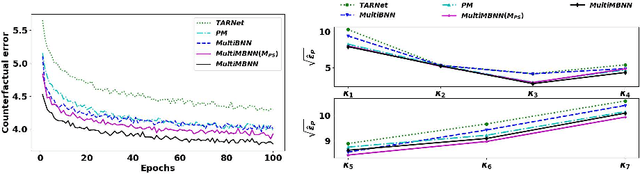
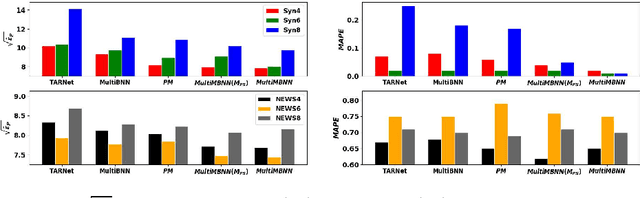
Causal inference (CI) in observational studies has received a lot of attention in healthcare, education, ad attribution, policy evaluation, etc. Confounding is a typical hazard, where the context affects both, the treatment assignment and response. In a multiple treatment scenario, we propose the neural network based MultiMBNN, where we overcome confounding by employing generalized propensity score based matching, and learning balanced representations. We benchmark the performance on synthetic and real-world datasets using PEHE, and mean absolute percentage error over ATE as metrics. MultiMBNN outperforms the state-of-the-art algorithms for CI such as TARNet and Perfect Match (PM).
TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Jan 06, 2020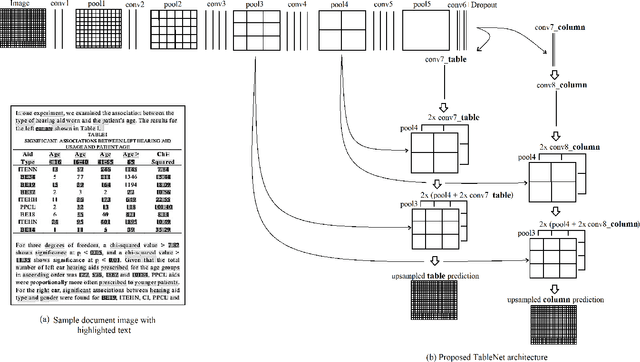

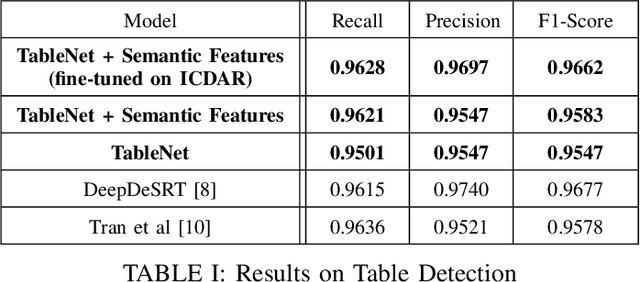
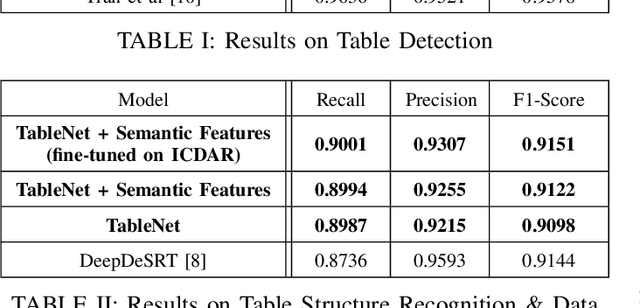
With the widespread use of mobile phones and scanners to photograph and upload documents, the need for extracting the information trapped in unstructured document images such as retail receipts, insurance claim forms and financial invoices is becoming more acute. A major hurdle to this objective is that these images often contain information in the form of tables and extracting data from tabular sub-images presents a unique set of challenges. This includes accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table. While some progress has been made in table detection, extracting the table contents is still a challenge since this involves more fine grained table structure(rows & columns) recognition. Prior approaches have attempted to solve the table detection and structure recognition problems independently using two separate models. In this paper, we propose TableNet: a novel end-to-end deep learning model for both table detection and structure recognition. The model exploits the interdependence between the twin tasks of table detection and table structure recognition to segment out the table and column regions. This is followed by semantic rule-based row extraction from the identified tabular sub-regions. The proposed model and extraction approach was evaluated on the publicly available ICDAR 2013 and Marmot Table datasets obtaining state of the art results. Additionally, we demonstrate that feeding additional semantic features further improves model performance and that the model exhibits transfer learning across datasets. Another contribution of this paper is to provide additional table structure annotations for the Marmot data, which currently only has annotations for table detection.
MetaCI: Meta-Learning for Causal Inference in a Heterogeneous Population
Dec 09, 2019
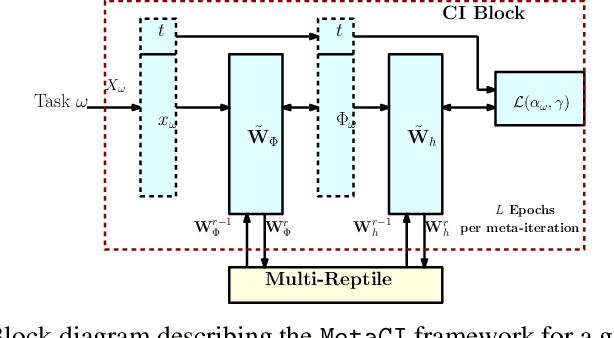
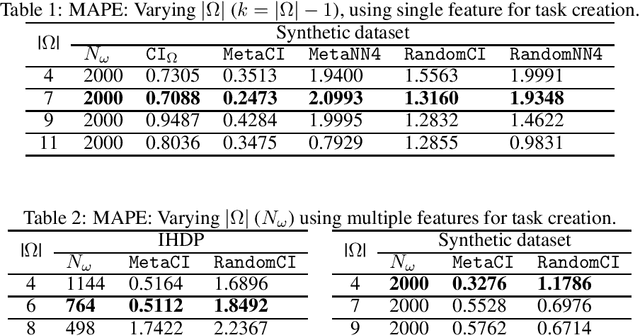
Performing inference on data obtained through observational studies is becoming extremely relevant due to the widespread availability of data in fields such as healthcare, education, retail, etc. Furthermore, this data is accrued from multiple homogeneous subgroups of a heterogeneous population, and hence, generalizing the inference mechanism over such data is essential. We propose the MetaCI framework with the goal of answering counterfactual questions in the context of causal inference (CI), where the factual observations are obtained from several homogeneous subgroups. While the CI network is designed to generalize from factual to counterfactual distribution in order to tackle covariate shift, MetaCI employs the meta-learning paradigm to tackle the shift in data distributions between training and test phase due to the presence of heterogeneity in the population, and due to drifts in the target distribution, also known as concept shift. We benchmark the performance of the MetaCI algorithm using the mean absolute percentage error over the average treatment effect as the metric, and demonstrate that meta initialization has significant gains compared to randomly initialized networks, and other methods.
ChartNet: Visual Reasoning over Statistical Charts using MAC-Networks
Nov 21, 2019



Despite the improvements in perception accuracies brought about via deep learning, developing systems combining accurate visual perception with the ability to reason over the visual percepts remains extremely challenging. A particular application area of interest from an accessibility perspective is that of reasoning over statistical charts such as bar and pie charts. To this end, we formulate the problem of reasoning over statistical charts as a classification task using MAC-Networks to give answers from a predefined vocabulary of generic answers. Additionally, we enhance the capabilities of MAC-Networks to give chart-specific answers to open-ended questions by replacing the classification layer by a regression layer to localize the textual answers present over the images. We call our network ChartNet, and demonstrate its efficacy on predicting both in vocabulary and out of vocabulary answers. To test our methods, we generated our own dataset of statistical chart images and corresponding question answer pairs. Results show that ChartNet consistently outperform other state-of-the-art methods on reasoning over these questions and may be a viable candidate for applications containing images of statistical charts.
Character Keypoint-based Homography Estimation in Scanned Documents for Efficient Information Extraction
Nov 14, 2019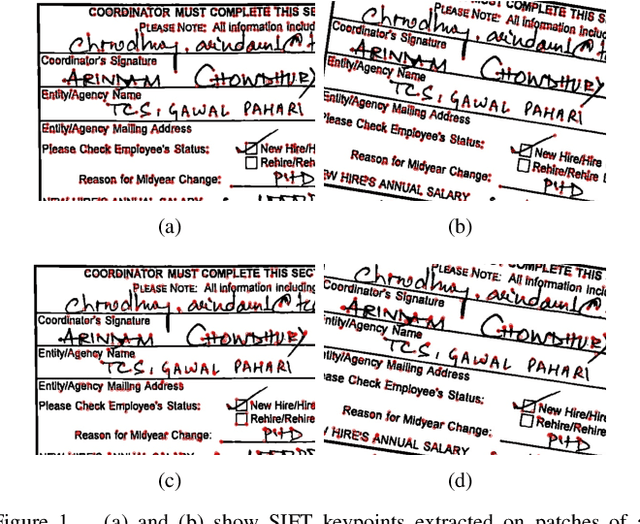
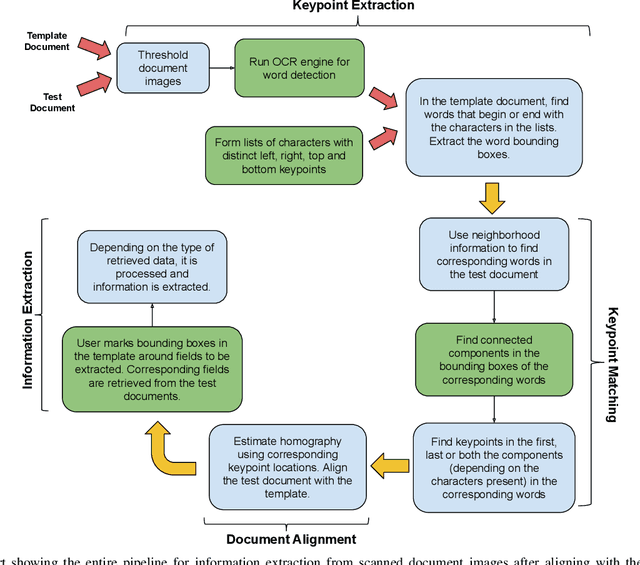
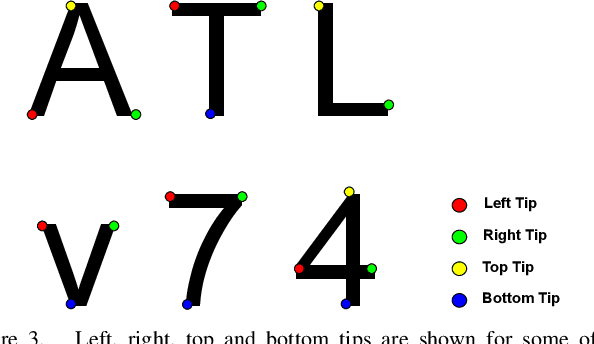

Precise homography estimation between multiple images is a pre-requisite for many computer vision applications. One application that is particularly relevant in today's digital era is the alignment of scanned or camera-captured document images such as insurance claim forms for information extraction. Traditional learning based approaches perform poorly due to the absence of an appropriate gradient. Feature based keypoint extraction techniques for homography estimation in real scene images either detect an extremely large number of inconsistent keypoints due to sharp textual edges, or produce inaccurate keypoint correspondences due to variations in illumination and viewpoint differences between document images. In this paper, we propose a novel algorithm for aligning scanned or camera-captured document images using character based keypoints and a reference template. The algorithm is both fast and accurate and utilizes a standard Optical character recognition (OCR) engine such as Tesseract to find character based unambiguous keypoints, which are utilized to identify precise keypoint correspondences between two images. Finally, the keypoints are used to compute the homography mapping between a test document and a template. We evaluated the proposed approach for information extraction on two real world anonymized datasets comprised of health insurance claim forms and the results support the viability of the proposed technique.
Meta-Learning for Few-Shot Time Series Classification
Sep 25, 2019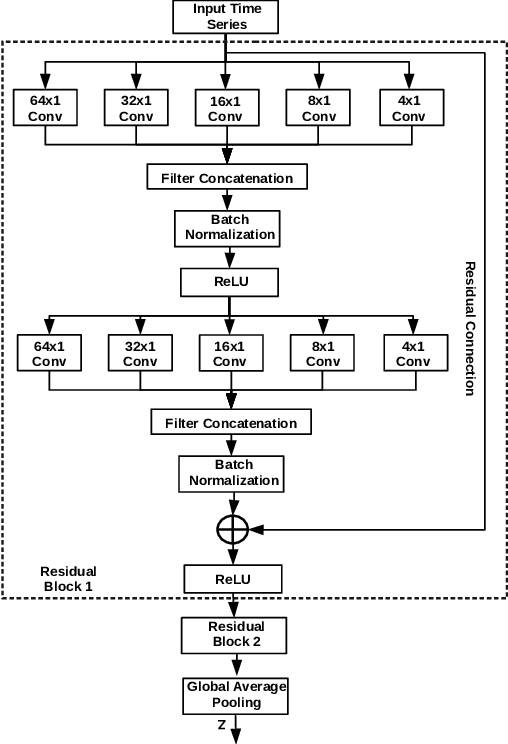
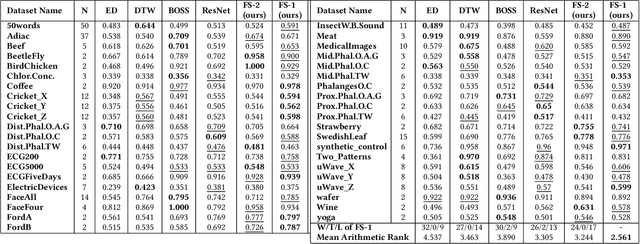
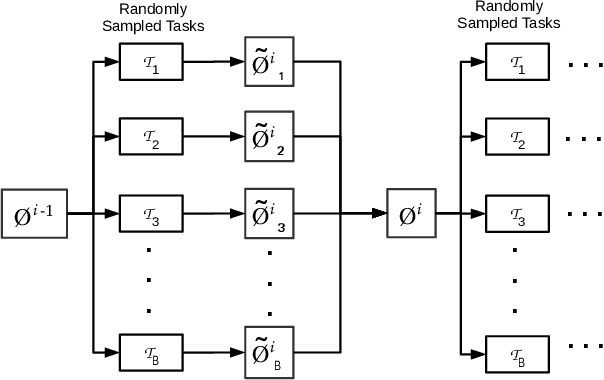
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.
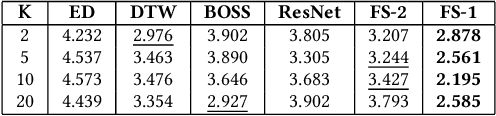
NISER: Normalized Item and Session Representations with Graph Neural Networks
Sep 13, 2019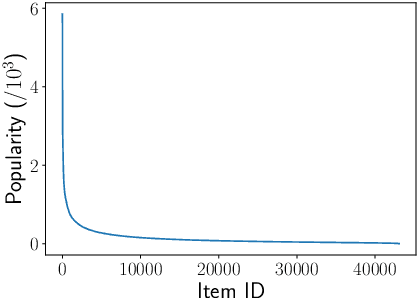
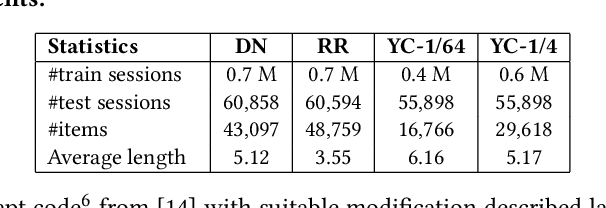
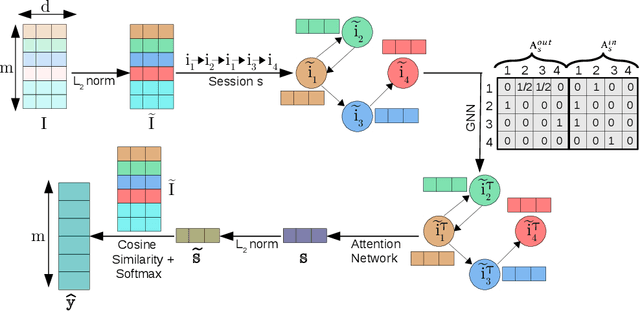

The goal of session-based recommendation (SR) models is to utilize the information from past actions (e.g. item/product clicks) in a session to recommend items that a user is likely to click next. Recently it has been shown that the sequence of item interactions in a session can be modeled as graph-structured data to better account for complex item transitions. Graph neural networks (GNNs) can learn useful representations for such session-graphs, and have been shown to improve over sequential models such as recurrent neural networks [14]. However, we note that these GNN-based recommendation models suffer from popularity bias: the models are biased towards recommending popular items, and fail to recommend relevant long-tail items (less popular or less frequent items). Therefore, these models perform poorly for the less popular new items arriving daily in a practical online setting. We demonstrate that this issue is, in part, related to the magnitude or norm of the learned item and session-graph representations (embedding vectors). We propose a training procedure that mitigates this issue by using normalized representations. The models using normalized item and session-graph representations perform significantly better: i. for the less popular long-tail items in the offline setting, and ii. for the less popular newly introduced items in the online setting. Furthermore, our approach significantly improves upon existing state-of-the-art on three benchmark datasets.
Meta-Learning for Black-box Optimization
Jul 16, 2019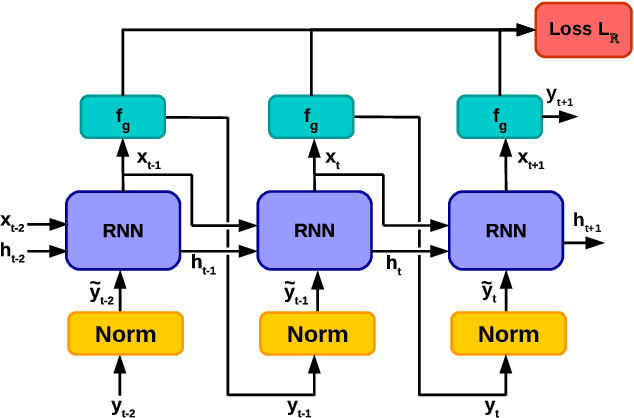
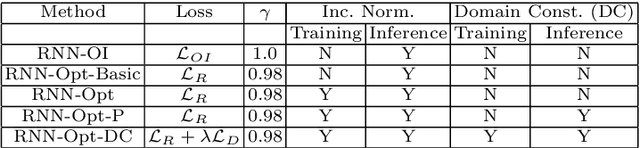
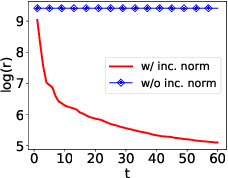
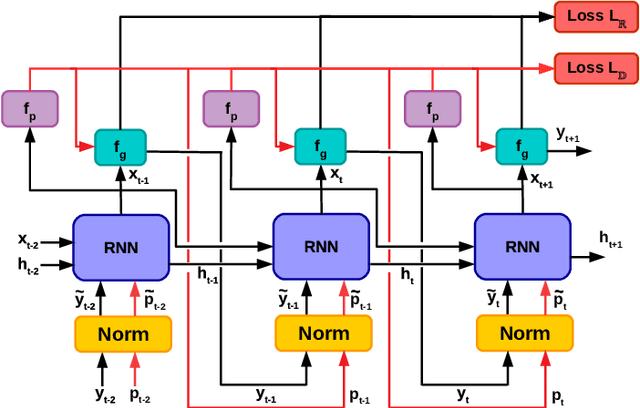
Recently, neural networks trained as optimizers under the "learning to learn" or meta-learning framework have been shown to be effective for a broad range of optimization tasks including derivative-free black-box function optimization. Recurrent neural networks (RNNs) trained to optimize a diverse set of synthetic non-convex differentiable functions via gradient descent have been effective at optimizing derivative-free black-box functions. In this work, we propose RNN-Opt: an approach for learning RNN-based optimizers for optimizing real-parameter single-objective continuous functions under limited budget constraints. Existing approaches utilize an observed improvement based meta-learning loss function for training such models. We propose training RNN-Opt by using synthetic non-convex functions with known (approximate) optimal values by directly using discounted regret as our meta-learning loss function. We hypothesize that a regret-based loss function mimics typical testing scenarios, and would therefore lead to better optimizers compared to optimizers trained only to propose queries that improve over previous queries. Further, RNN-Opt incorporates simple yet effective enhancements during training and inference procedures to deal with the following practical challenges: i) Unknown range of possible values for the black-box function to be optimized, and ii) Practical and domain-knowledge based constraints on the input parameters. We demonstrate the efficacy of RNN-Opt in comparison to existing methods on several synthetic as well as standard benchmark black-box functions along with an anonymized industrial constrained optimization problem.
One-shot Information Extraction from Document Images using Neuro-Deductive Program Synthesis
Jun 06, 2019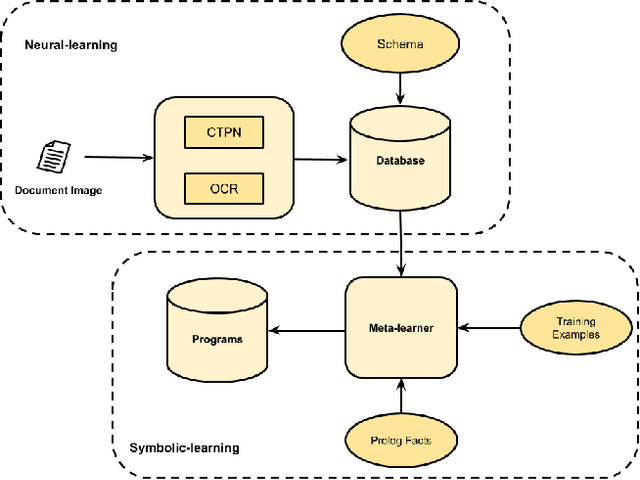


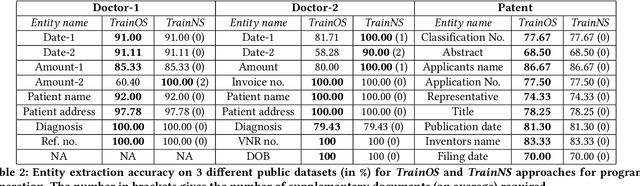
Our interest in this paper is in meeting a rapidly growing industrial demand for information extraction from images of documents such as invoices, bills, receipts etc. In practice users are able to provide a very small number of example images labeled with the information that needs to be extracted. We adopt a novel two-level neuro-deductive, approach where (a) we use pre-trained deep neural networks to populate a relational database with facts about each document-image; and (b) we use a form of deductive reasoning, related to meta-interpretive learning of transition systems to learn extraction programs: Given task-specific transitions defined using the entities and relations identified by the neural detectors and a small number of instances (usually 1, sometimes 2) of images and the desired outputs, a resource-bounded meta-interpreter constructs proofs for the instance(s) via logical deduction; a set of logic programs that extract each desired entity is easily synthesized from such proofs. In most cases a single training example together with a noisy-clone of itself suffices to learn a program-set that generalizes well on test documents, at which time the value of each entity is determined by a majority vote across its program-set. We demonstrate our two-level neuro-deductive approach on publicly available datasets ("Patent" and "Doctor's Bills") and also describe its use in a real-life industrial problem.