 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSat: Self-Supervised Modality Fusion for Earth Observation
Apr 12, 2024



The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024



Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
Scalable 3D Panoptic Segmentation With Superpoint Graph Clustering
Jan 12, 2024



We introduce a highly efficient method for panoptic segmentation of large 3D point clouds by redefining this task as a scalable graph clustering problem. This approach can be trained using only local auxiliary tasks, thereby eliminating the resource-intensive instance-matching step during training. Moreover, our formulation can easily be adapted to the superpoint paradigm, further increasing its efficiency. This allows our model to process scenes with millions of points and thousands of objects in a single inference. Our method, called SuperCluster, achieves a new state-of-the-art panoptic segmentation performance for two indoor scanning datasets: $50.1$ PQ ($+7.8$) for S3DIS Area~5, and $58.7$ PQ ($+25.2$) for ScanNetV2. We also set the first state-of-the-art for two large-scale mobile mapping benchmarks: KITTI-360 and DALES. With only $209$k parameters, our model is over $30$ times smaller than the best-competing method and trains up to $15$ times faster. Our code and pretrained models are available at https://github.com/drprojects/superpoint_transformer.
FLAIR: a Country-Scale Land Cover Semantic Segmentation Dataset From Multi-Source Optical Imagery
Oct 20, 2023



We introduce the French Land cover from Aerospace ImageRy (FLAIR), an extensive dataset from the French National Institute of Geographical and Forest Information (IGN) that provides a unique and rich resource for large-scale geospatial analysis. FLAIR contains high-resolution aerial imagery with a ground sample distance of 20 cm and over 20 billion individually labeled pixels for precise land-cover classification. The dataset also integrates temporal and spectral data from optical satellite time series. FLAIR thus combines data with varying spatial, spectral, and temporal resolutions across over 817 km2 of acquisitions representing the full landscape diversity of France. This diversity makes FLAIR a valuable resource for the development and evaluation of novel methods for large-scale land-cover semantic segmentation and raises significant challenges in terms of computer vision, data fusion, and geospatial analysis. We also provide powerful uni- and multi-sensor baseline models that can be employed to assess algorithm's performance and for downstream applications. Through its extent and the quality of its annotation, FLAIR aims to spur improvements in monitoring and understanding key anthropogenic development indicators such as urban growth, deforestation, and soil artificialization. Dataset and codes can be accessed at https://ignf.github.io/FLAIR/
Efficient 3D Semantic Segmentation with Superpoint Transformer
Jun 13, 2023



We introduce a novel superpoint-based transformer architecture for efficient semantic segmentation of large-scale 3D scenes. Our method incorporates a fast algorithm to partition point clouds into a hierarchical superpoint structure, which makes our preprocessing 7 times times faster than existing superpoint-based approaches. Additionally, we leverage a self-attention mechanism to capture the relationships between superpoints at multiple scales, leading to state-of-the-art performance on three challenging benchmark datasets: S3DIS (76.0% mIoU 6-fold validation), KITTI-360 (63.5% on Val), and DALES (79.6%). With only 212k parameters, our approach is up to 200 times more compact than other state-of-the-art models while maintaining similar performance. Furthermore, our model can be trained on a single GPU in 3 hours for a fold of the S3DIS dataset, which is 7x to 70x fewer GPU-hours than the best-performing methods. Our code and models are accessible at github.com/drprojects/superpoint_transformer.
Learnable Earth Parser: Discovering 3D Prototypes in Aerial Scans
Apr 19, 2023



We propose an unsupervised method for parsing large 3D scans of real-world scenes into interpretable parts. Our goal is to provide a practical tool for analyzing 3D scenes with unique characteristics in the context of aerial surveying and mapping, without relying on application-specific user annotations. Our approach is based on a probabilistic reconstruction model that decomposes an input 3D point cloud into a small set of learned prototypical shapes. Our model provides an interpretable reconstruction of complex scenes and leads to relevant instance and semantic segmentations. To demonstrate the usefulness of our results, we introduce a novel dataset of seven diverse aerial LiDAR scans. We show that our method outperforms state-of-the-art unsupervised methods in terms of decomposition accuracy while remaining visually interpretable. Our method offers significant advantage over existing approaches, as it does not require any manual annotations, making it a practical and efficient tool for 3D scene analysis. Our code and dataset are available at https://imagine.enpc.fr/~loiseaur/learnable-earth-parser
A Survey and Benchmark of Automatic Surface Reconstruction from Point Clouds
Jan 31, 2023We survey and benchmark traditional and novel learning-based algorithms that address the problem of surface reconstruction from point clouds. Surface reconstruction from point clouds is particularly challenging when applied to real-world acquisitions, due to noise, outliers, non-uniform sampling and missing data. Traditionally, different handcrafted priors of the input points or the output surface have been proposed to make the problem more tractable. However, hyperparameter tuning for adjusting priors to different acquisition defects can be a tedious task. To this end, the deep learning community has recently addressed the surface reconstruction problem. In contrast to traditional approaches, deep surface reconstruction methods can learn priors directly from a training set of point clouds and corresponding true surfaces. In our survey, we detail how different handcrafted and learned priors affect the robustness of methods to defect-laden input and their capability to generate geometric and topologically accurate reconstructions. In our benchmark, we evaluate the reconstructions of several traditional and learning-based methods on the same grounds. We show that learning-based methods can generalize to unseen shape categories, but their training and test sets must share the same point cloud characteristics. We also provide the code and data to compete in our benchmark and to further stimulate the development of learning-based surface reconstruction https://github.com/raphaelsulzer/dsr-benchmark.
A Model You Can Hear: Audio Identification with Playable Prototypes
Aug 05, 2022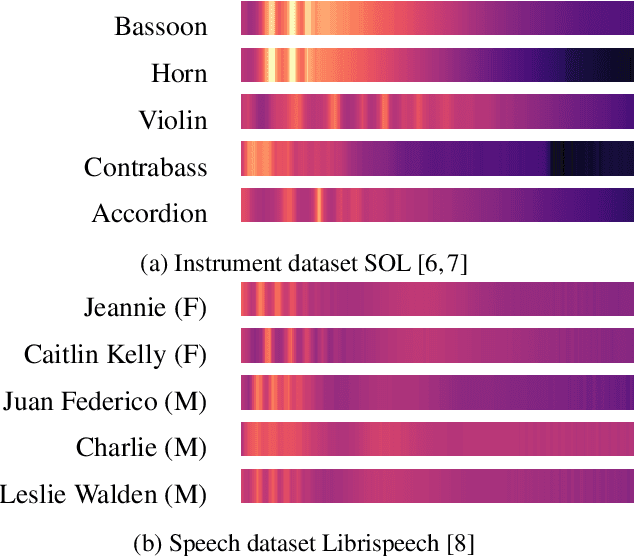
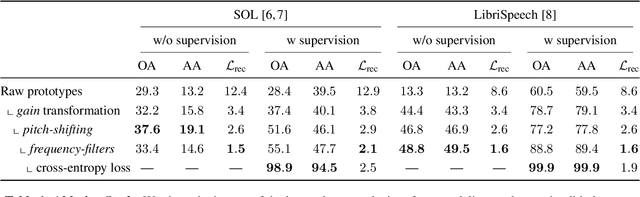
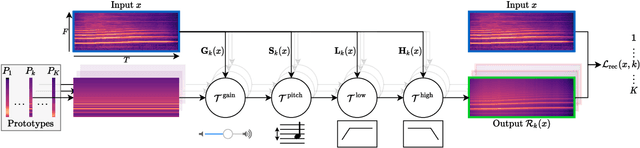
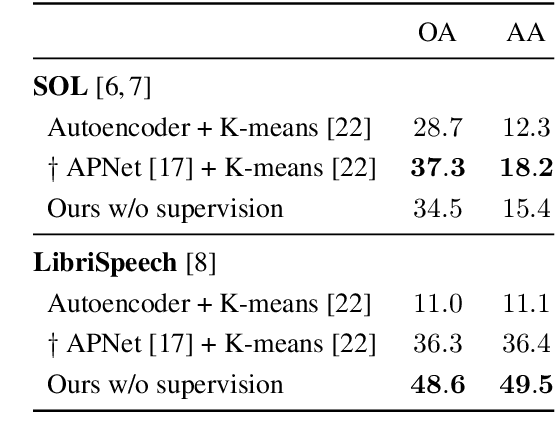
Machine learning techniques have proved useful for classifying and analyzing audio content. However, recent methods typically rely on abstract and high-dimensional representations that are difficult to interpret. Inspired by transformation-invariant approaches developed for image and 3D data, we propose an audio identification model based on learnable spectral prototypes. Equipped with dedicated transformation networks, these prototypes can be used to cluster and classify input audio samples from large collections of sounds. Our model can be trained with or without supervision and reaches state-of-the-art results for speaker and instrument identification, while remaining easily interpretable. The code is available at: https://github.com/romainloiseau/a-model-you-can-hear
Multi-Layer Modeling of Dense Vegetation from Aerial LiDAR Scans
Apr 25, 2022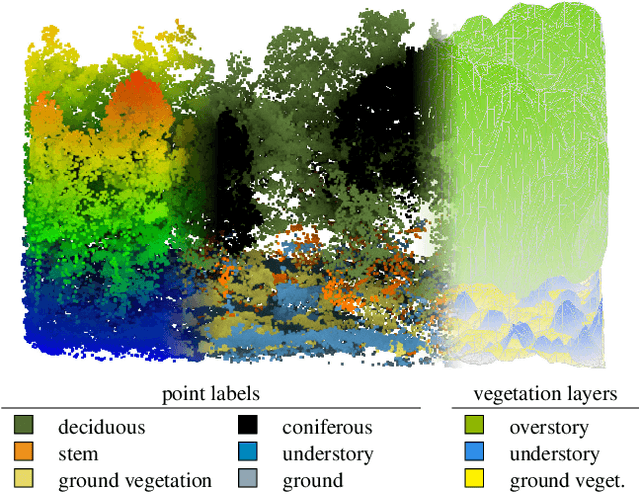

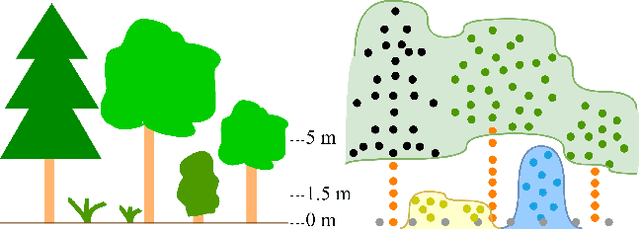
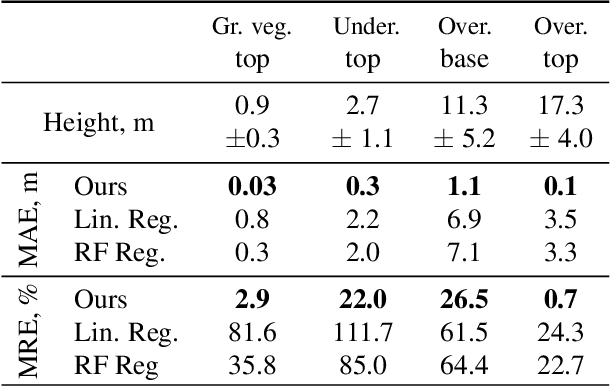
The analysis of the multi-layer structure of wild forests is an important challenge of automated large-scale forestry. While modern aerial LiDARs offer geometric information across all vegetation layers, most datasets and methods focus only on the segmentation and reconstruction of the top of canopy. We release WildForest3D, which consists of 29 study plots and over 2000 individual trees across 47 000m2 with dense 3D annotation, along with occupancy and height maps for 3 vegetation layers: ground vegetation, understory, and overstory. We propose a 3D deep network architecture predicting for the first time both 3D point-wise labels and high-resolution layer occupancy rasters simultaneously. This allows us to produce a precise estimation of the thickness of each vegetation layer as well as the corresponding watertight meshes, therefore meeting most forestry purposes. Both the dataset and the model are released in open access: https://github.com/ekalinicheva/multi_layer_vegetation.
Learning Multi-View Aggregation In the Wild for Large-Scale 3D Semantic Segmentation
Apr 15, 2022
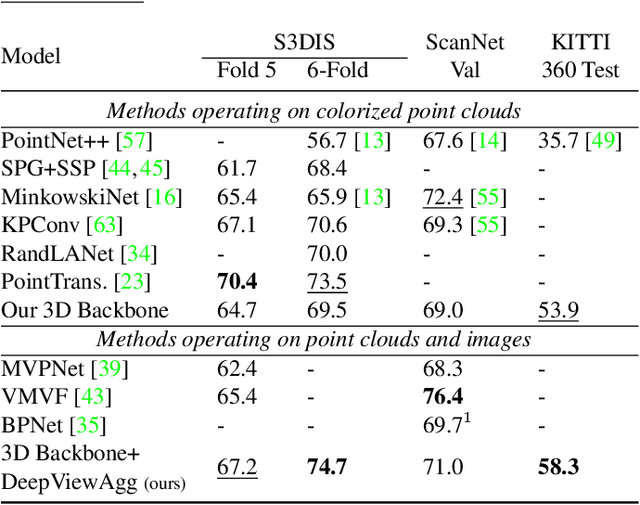
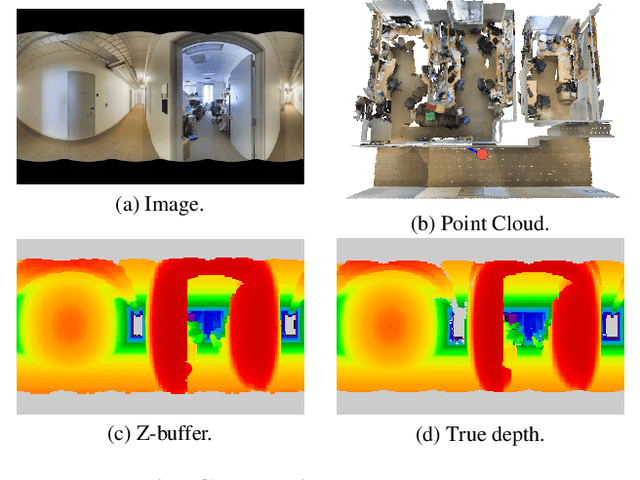
Recent works on 3D semantic segmentation propose to exploit the synergy between images and point clouds by processing each modality with a dedicated network and projecting learned 2D features onto 3D points. Merging large-scale point clouds and images raises several challenges, such as constructing a mapping between points and pixels, and aggregating features between multiple views. Current methods require mesh reconstruction or specialized sensors to recover occlusions, and use heuristics to select and aggregate available images. In contrast, we propose an end-to-end trainable multi-view aggregation model leveraging the viewing conditions of 3D points to merge features from images taken at arbitrary positions. Our method can combine standard 2D and 3D networks and outperforms both 3D models operating on colorized point clouds and hybrid 2D/3D networks without requiring colorization, meshing, or true depth maps. We set a new state-of-the-art for large-scale indoor/outdoor semantic segmentation on S3DIS (74.7 mIoU 6-Fold) and on KITTI-360 (58.3 mIoU). Our full pipeline is accessible at https://github.com/drprojects/DeepViewAgg, and only requires raw 3D scans and a set of images and poses.