 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Box Anomaly Scoring for simple and efficient Out-of-Distribution detection
Mar 24, 2026Out-of-distribution (OOD) detection aims to identify inputs that differ from the training distribution in order to reduce unreliable predictions by deep neural networks. Among post-hoc feature-space approaches, OOD detection is commonly performed by approximating the in-distribution support in the representation space of a pretrained network. Existing methods often reflect a trade-off between compact parametric models, such as Mahalanobis-based scores, and more flexible but reference-based methods, such as k-nearest neighbors. Bounding-box abstraction provides an attractive intermediate perspective by representing in-distribution support through compact axis-aligned summaries of hidden activations. In this paper, we introduce Bounding Box Anomaly Scoring (BBAS), a post-hoc OOD detection method that leverages bounding-box abstraction. BBAS combines graded anomaly scores based on interval exceedances, monitoring variables adapted to convolutional layers, and decoupled clustering and box construction for richer and multi-layer representations. Experiments on image-classification benchmarks show that BBAS provides robust separation between in-distribution and out-of-distribution samples while preserving the simplicity, compactness, and updateability of the bounding-box approach.
Conditional Latent Block Model: a Multivariate Time Series Clustering Approach for Autonomous Driving Validation
Aug 03, 2020

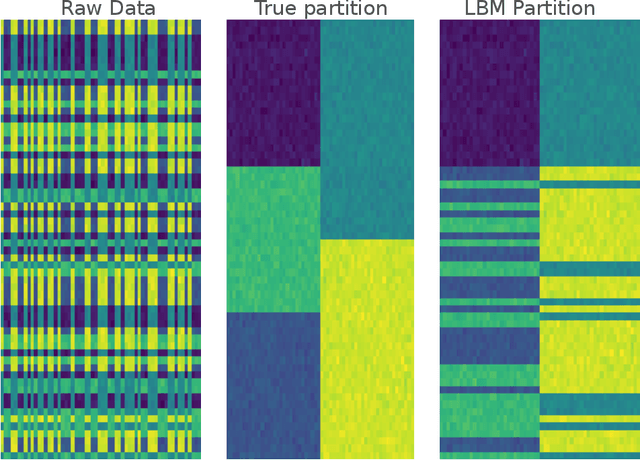
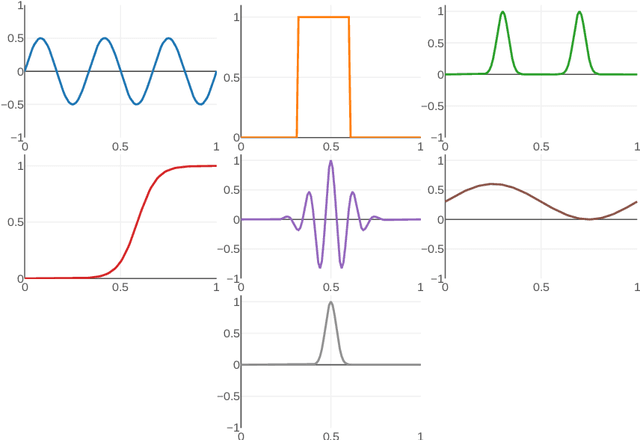
Autonomous driving systems validation remains one of the biggest challenges car manufacturers must tackle in order to provide safe driverless cars. The high complexity stems from several factors: the multiplicity of vehicles, embedded systems, use cases, and the very high required level of reliability for the driving system to be at least as safe as a human driver. In order to circumvent these issues, large scale simulations reproducing this huge variety of physical conditions are intensively used to test driverless cars. Therefore, the validation step produces a massive amount of data, including many time-indexed ones, to be processed. In this context, building a structure in the feature space is mandatory to interpret the various scenarios. In this work, we propose a new co-clustering approach adapted to high-dimensional time series analysis, that extends the standard model-based co-clustering. The FunCLBM model extends the recently proposed Functional Latent Block Model and allows to create a dependency structure between row and column clusters. This structured partition acts as a feature selection method, that provides several clustering views of a dataset, while discriminating irrelevant features. In this workflow, times series are projected onto a common interpolated low-dimensional frequency space, which allows to optimize the projection basis. In addition, FunCLBM refines the definition of each latent block by performing block-wise dimension reduction and feature selection. We propose a SEM-Gibbs algorithm to infer this model, as well as a dedicated criterion to select the optimal nested partition. Experiments on both simulated and real-case Renault datasets shows the effectiveness of the proposed tools and the adequacy to our use case.