 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated Fact Checking Using External Sources
Oct 01, 2017
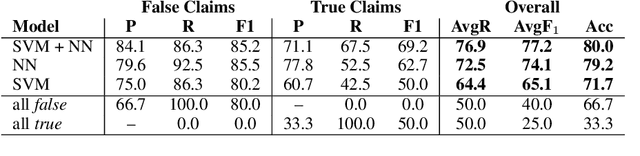
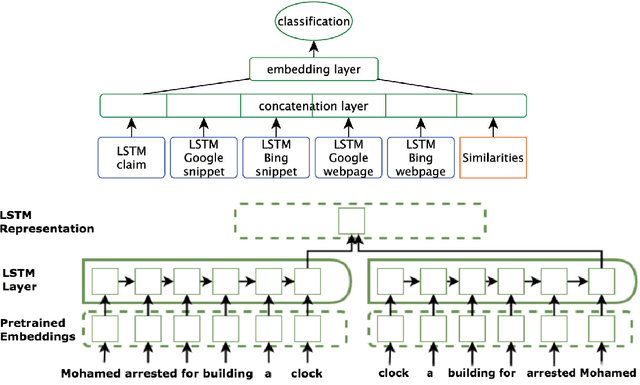
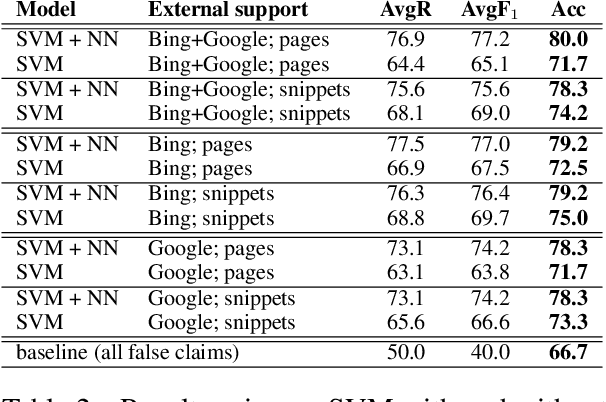
Given the constantly growing proliferation of false claims online in recent years, there has been also a growing research interest in automatically distinguishing false rumors from factually true claims. Here, we propose a general-purpose framework for fully-automatic fact checking using external sources, tapping the potential of the entire Web as a knowledge source to confirm or reject a claim. Our framework uses a deep neural network with LSTM text encoding to combine semantic kernels with task-specific embeddings that encode a claim together with pieces of potentially-relevant text fragments from the Web, taking the source reliability into account. The evaluation results show good performance on two different tasks and datasets: (i) rumor detection and (ii) fact checking of the answers to a question in community question answering forums.
Semi-supervised Question Retrieval with Gated Convolutions
Apr 04, 2016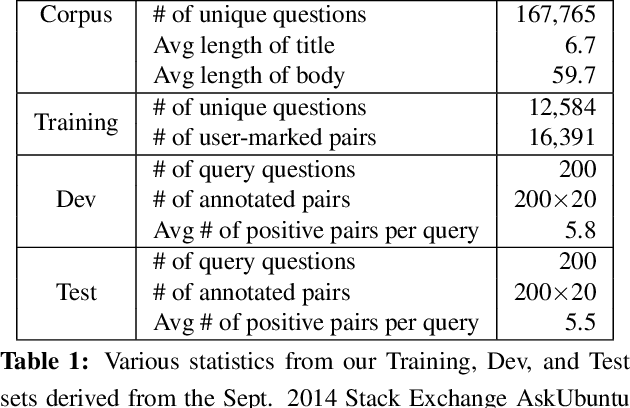
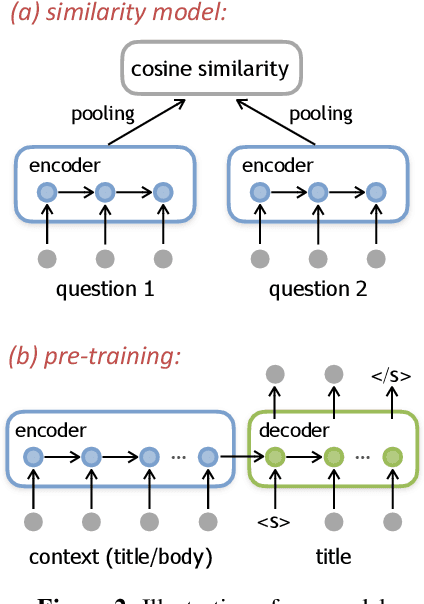
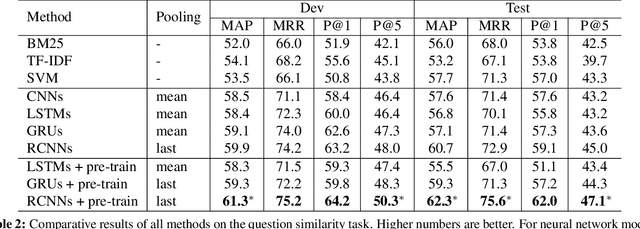
Question answering forums are rapidly growing in size with no effective automated ability to refer to and reuse answers already available for previous posted questions. In this paper, we develop a methodology for finding semantically related questions. The task is difficult since 1) key pieces of information are often buried in extraneous details in the question body and 2) available annotations on similar questions are scarce and fragmented. We design a recurrent and convolutional model (gated convolution) to effectively map questions to their semantic representations. The models are pre-trained within an encoder-decoder framework (from body to title) on the basis of the entire raw corpus, and fine-tuned discriminatively from limited annotations. Our evaluation demonstrates that our model yields substantial gains over a standard IR baseline and various neural network architectures (including CNNs, LSTMs and GRUs).
Boosting Trees for Anti-Spam Email Filtering
Sep 13, 2001
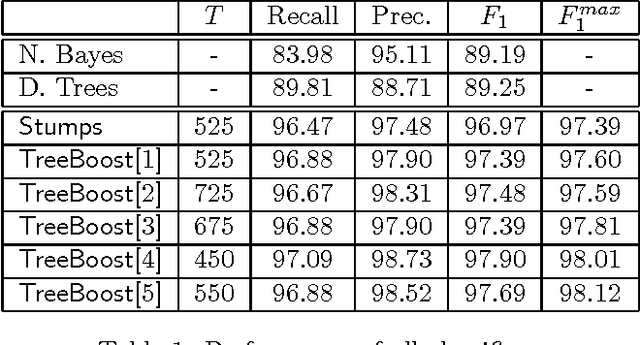
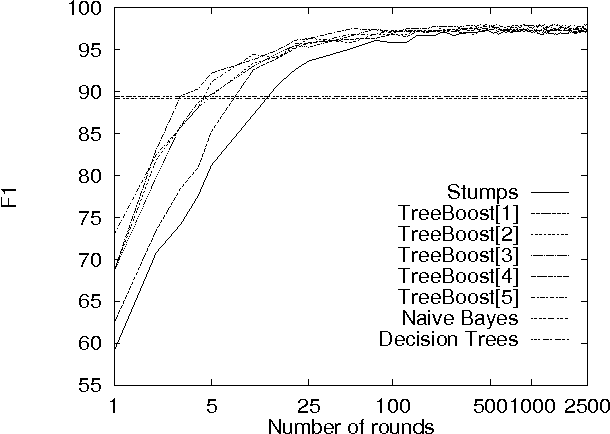
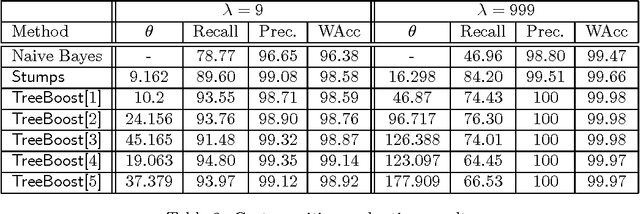
This paper describes a set of comparative experiments for the problem of automatically filtering unwanted electronic mail messages. Several variants of the AdaBoost algorithm with confidence-rated predictions [Schapire & Singer, 99] have been applied, which differ in the complexity of the base learners considered. Two main conclusions can be drawn from our experiments: a) The boosting-based methods clearly outperform the baseline learning algorithms (Naive Bayes and Induction of Decision Trees) on the PU1 corpus, achieving very high levels of the F1 measure; b) Increasing the complexity of the base learners allows to obtain better ``high-precision'' classifiers, which is a very important issue when misclassification costs are considered.
* 7 pages, 13 figures
A Comparison between Supervised Learning Algorithms for Word Sense Disambiguation
Sep 22, 2000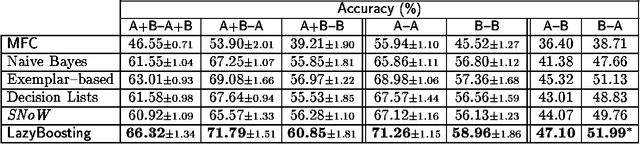
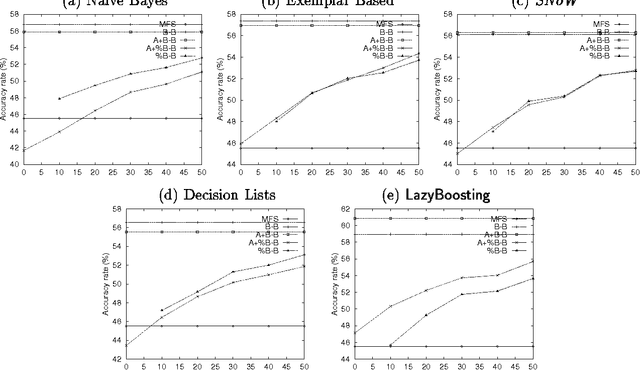
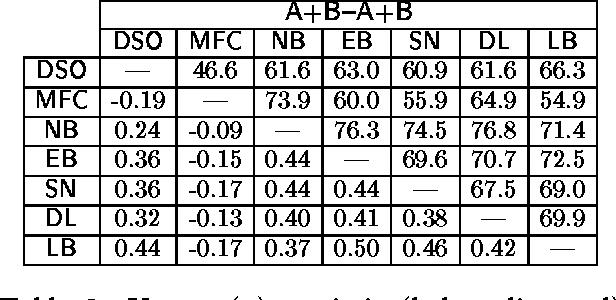
This paper describes a set of comparative experiments, including cross-corpus evaluation, between five alternative algorithms for supervised Word Sense Disambiguation (WSD), namely Naive Bayes, Exemplar-based learning, SNoW, Decision Lists, and Boosting. Two main conclusions can be drawn: 1) The LazyBoosting algorithm outperforms the other four state-of-the-art algorithms in terms of accuracy and ability to tune to new domains; 2) The domain dependence of WSD systems seems very strong and suggests that some kind of adaptation or tuning is required for cross-corpus application.
* 6 pages
Naive Bayes and Exemplar-Based approaches to Word Sense Disambiguation Revisited
Jul 07, 2000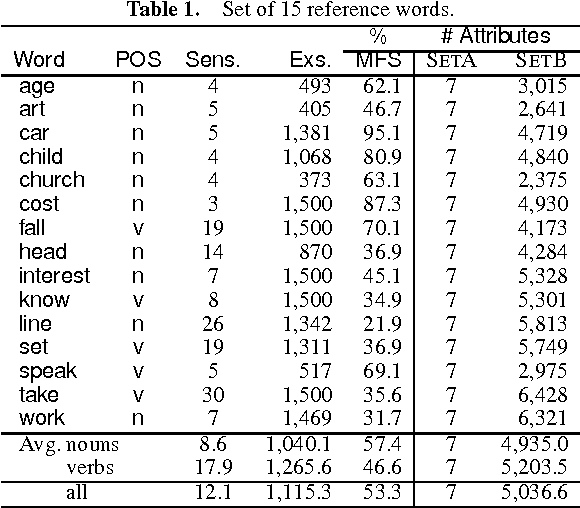
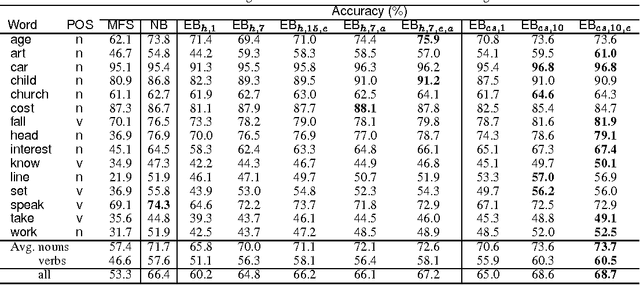


This paper describes an experimental comparison between two standard supervised learning methods, namely Naive Bayes and Exemplar-based classification, on the Word Sense Disambiguation (WSD) problem. The aim of the work is twofold. Firstly, it attempts to contribute to clarify some confusing information about the comparison between both methods appearing in the related literature. In doing so, several directions have been explored, including: testing several modifications of the basic learning algorithms and varying the feature space. Secondly, an improvement of both algorithms is proposed, in order to deal with large attribute sets. This modification, which basically consists in using only the positive information appearing in the examples, allows to improve greatly the efficiency of the methods, with no loss in accuracy. The experiments have been performed on the largest sense-tagged corpus available containing the most frequent and ambiguous English words. Results show that the Exemplar-based approach to WSD is generally superior to the Bayesian approach, especially when a specific metric for dealing with symbolic attributes is used.
* 5 pages
Boosting Applied to Word Sense Disambiguation
Jul 07, 2000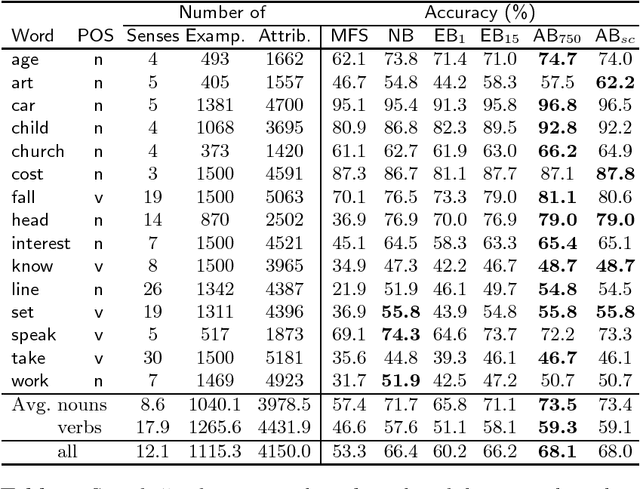
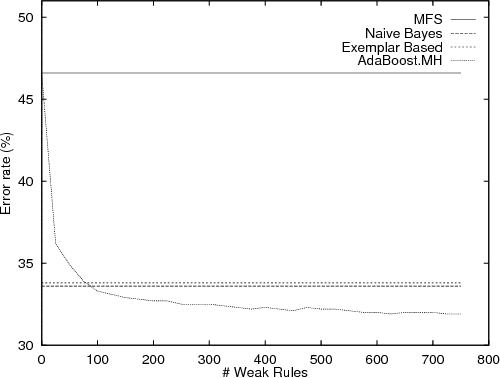
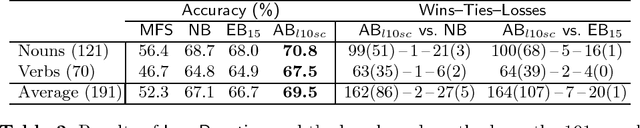
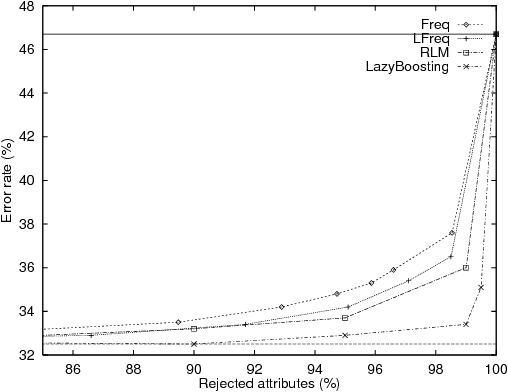
In this paper Schapire and Singer's AdaBoost.MH boosting algorithm is applied to the Word Sense Disambiguation (WSD) problem. Initial experiments on a set of 15 selected polysemous words show that the boosting approach surpasses Naive Bayes and Exemplar-based approaches, which represent state-of-the-art accuracy on supervised WSD. In order to make boosting practical for a real learning domain of thousands of words, several ways of accelerating the algorithm by reducing the feature space are studied. The best variant, which we call LazyBoosting, is tested on the largest sense-tagged corpus available containing 192,800 examples of the 191 most frequent and ambiguous English words. Again, boosting compares favourably to the other benchmark algorithms.
* 12 pages
A Flexible POS tagger Using an Automatically Acquired Language Model
Jul 11, 1997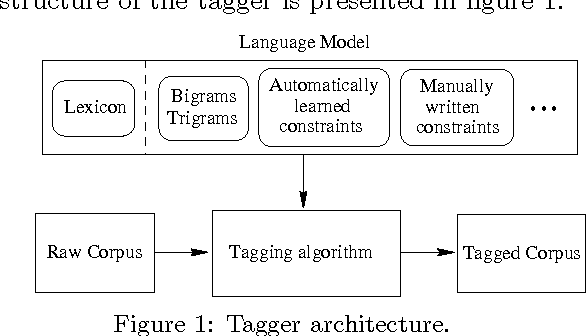
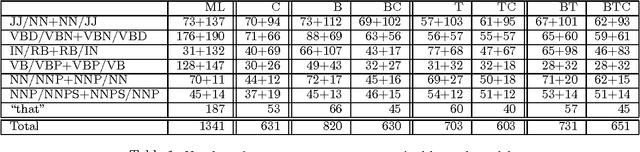
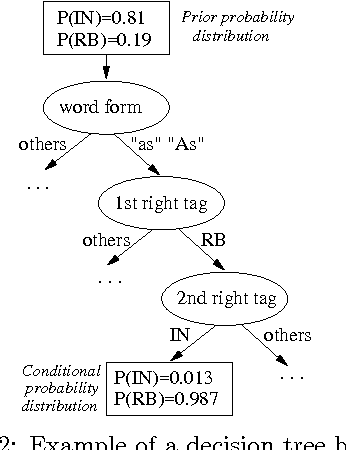

We present an algorithm that automatically learns context constraints using statistical decision trees. We then use the acquired constraints in a flexible POS tagger. The tagger is able to use information of any degree: n-grams, automatically learned context constraints, linguistically motivated manually written constraints, etc. The sources and kinds of constraints are unrestricted, and the language model can be easily extended, improving the results. The tagger has been tested and evaluated on the WSJ corpus.
* 8 pages, aclap.sty, 2 eps figures. Appears in (E)ACL'97