 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn from Web Data through Deep Semantic Embeddings
Aug 20, 2018
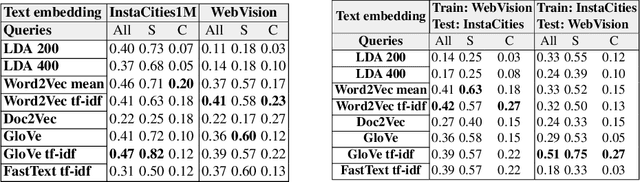
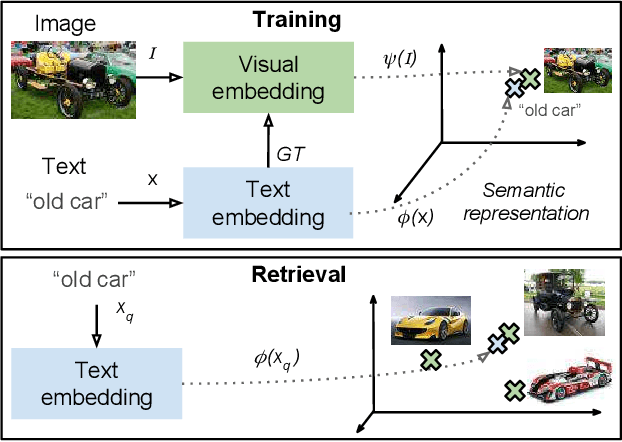

In this paper we propose to learn a multimodal image and text embedding from Web and Social Media data, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the pipeline can learn from images with associated text without supervision and perform a thourough analysis of five different text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.
TextTopicNet - Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
Jul 04, 2018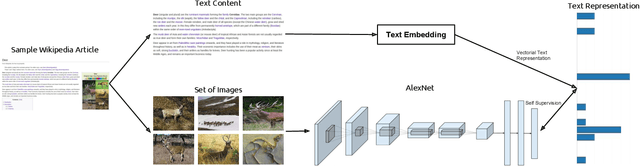
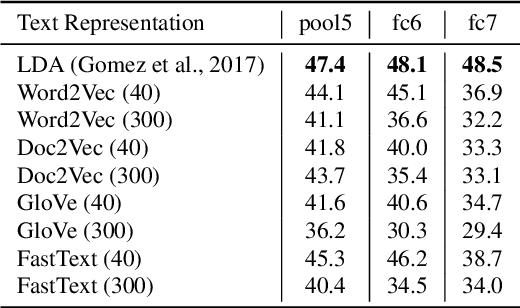

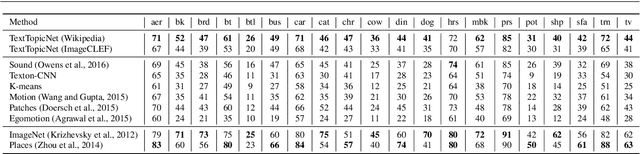
The immense success of deep learning based methods in computer vision heavily relies on large scale training datasets. These richly annotated datasets help the network learn discriminative visual features. Collecting and annotating such datasets requires a tremendous amount of human effort and annotations are limited to popular set of classes. As an alternative, learning visual features by designing auxiliary tasks which make use of freely available self-supervision has become increasingly popular in the computer vision community. In this paper, we put forward an idea to take advantage of multi-modal context to provide self-supervision for the training of computer vision algorithms. We show that adequate visual features can be learned efficiently by training a CNN to predict the semantic textual context in which a particular image is more probable to appear as an illustration. More specifically we use popular text embedding techniques to provide the self-supervision for the training of deep CNN. Our experiments demonstrate state-of-the-art performance in image classification, object detection, and multi-modal retrieval compared to recent self-supervised or naturally-supervised approaches.
Self-supervised learning of visual features through embedding images into text topic spaces
May 24, 2017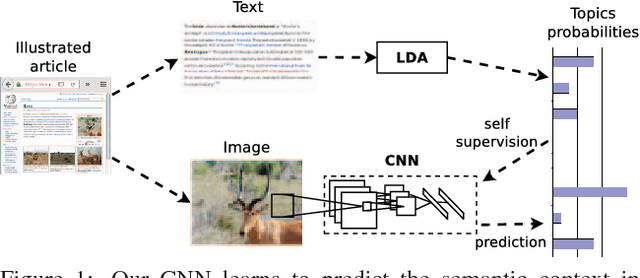
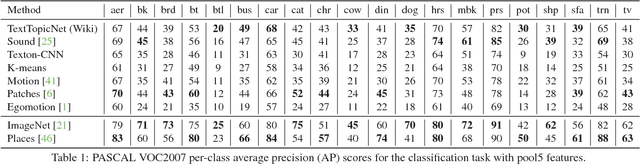
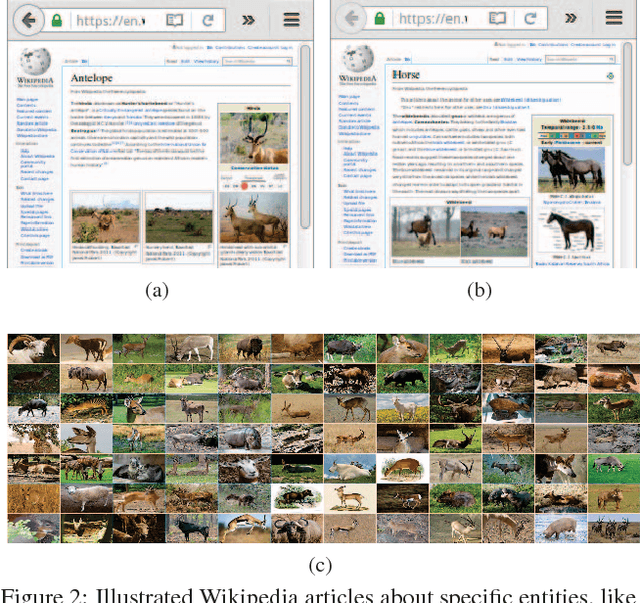
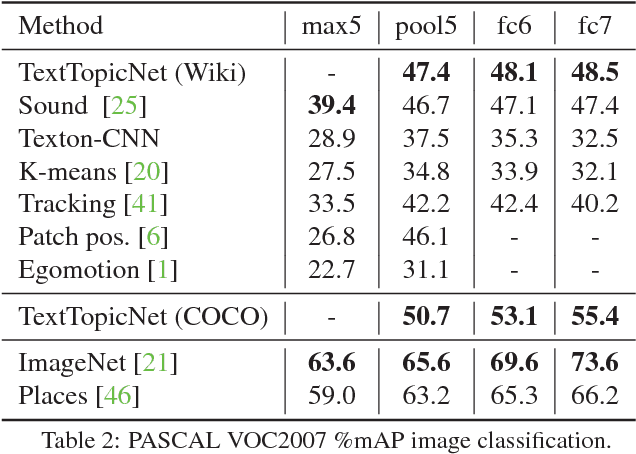
End-to-end training from scratch of current deep architectures for new computer vision problems would require Imagenet-scale datasets, and this is not always possible. In this paper we present a method that is able to take advantage of freely available multi-modal content to train computer vision algorithms without human supervision. We put forward the idea of performing self-supervised learning of visual features by mining a large scale corpus of multi-modal (text and image) documents. We show that discriminative visual features can be learnt efficiently by training a CNN to predict the semantic context in which a particular image is more probable to appear as an illustration. For this we leverage the hidden semantic structures discovered in the text corpus with a well-known topic modeling technique. Our experiments demonstrate state of the art performance in image classification, object detection, and multi-modal retrieval compared to recent self-supervised or natural-supervised approaches.
Improving Text Proposals for Scene Images with Fully Convolutional Networks
Feb 16, 2017



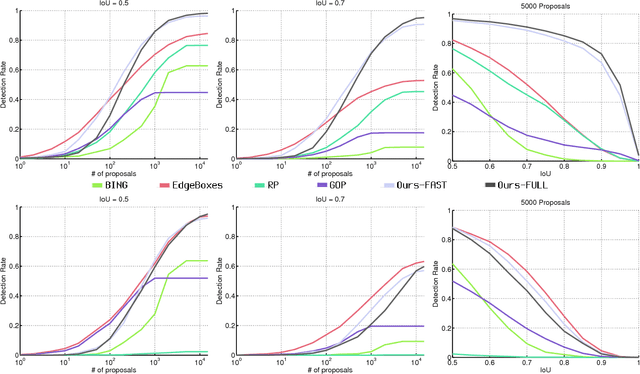
Text Proposals have emerged as a class-dependent version of object proposals - efficient approaches to reduce the search space of possible text object locations in an image. Combined with strong word classifiers, text proposals currently yield top state of the art results in end-to-end scene text recognition. In this paper we propose an improvement over the original Text Proposals algorithm of Gomez and Karatzas (2016), combining it with Fully Convolutional Networks to improve the ranking of proposals. Results on the ICDAR RRC and the COCO-text datasets show superior performance over current state-of-the-art.
Improving patch-based scene text script identification with ensembles of conjoined networks
Feb 01, 2017
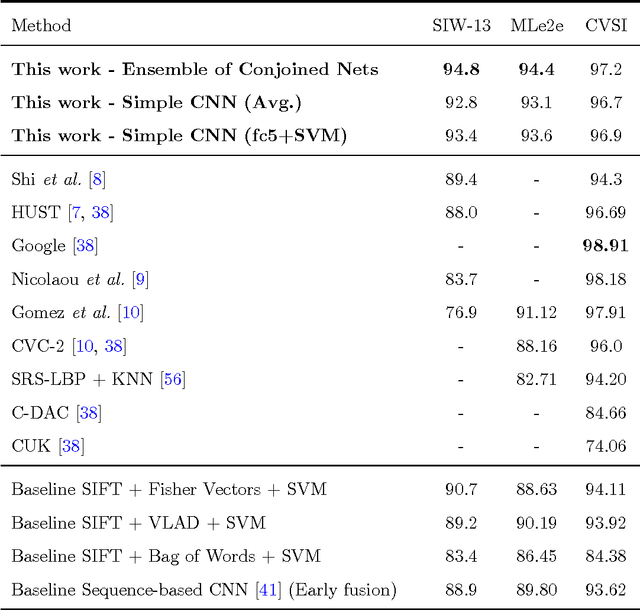

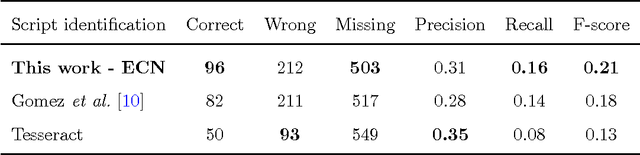
This paper focuses on the problem of script identification in scene text images. Facing this problem with state of the art CNN classifiers is not straightforward, as they fail to address a key characteristic of scene text instances: their extremely variable aspect ratio. Instead of resizing input images to a fixed aspect ratio as in the typical use of holistic CNN classifiers, we propose here a patch-based classification framework in order to preserve discriminative parts of the image that are characteristic of its class. We describe a novel method based on the use of ensembles of conjoined networks to jointly learn discriminative stroke-parts representations and their relative importance in a patch-based classification scheme. Our experiments with this learning procedure demonstrate state-of-the-art results in two public script identification datasets. In addition, we propose a new public benchmark dataset for the evaluation of multi-lingual scene text end-to-end reading systems. Experiments done in this dataset demonstrate the key role of script identification in a complete end-to-end system that combines our script identification method with a previously published text detector and an off-the-shelf OCR engine.
A fine-grained approach to scene text script identification
Feb 24, 2016



This paper focuses on the problem of script identification in unconstrained scenarios. Script identification is an important prerequisite to recognition, and an indispensable condition for automatic text understanding systems designed for multi-language environments. Although widely studied for document images and handwritten documents, it remains an almost unexplored territory for scene text images. We detail a novel method for script identification in natural images that combines convolutional features and the Naive-Bayes Nearest Neighbor classifier. The proposed framework efficiently exploits the discriminative power of small stroke-parts, in a fine-grained classification framework. In addition, we propose a new public benchmark dataset for the evaluation of joint text detection and script identification in natural scenes. Experiments done in this new dataset demonstrate that the proposed method yields state of the art results, while it generalizes well to different datasets and variable number of scripts. The evidence provided shows that multi-lingual scene text recognition in the wild is a viable proposition. Source code of the proposed method is made available online.
Object Proposals for Text Extraction in the Wild
Sep 08, 2015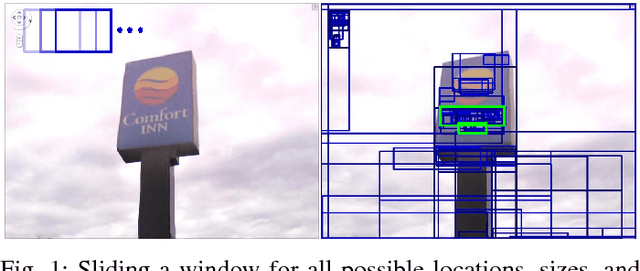
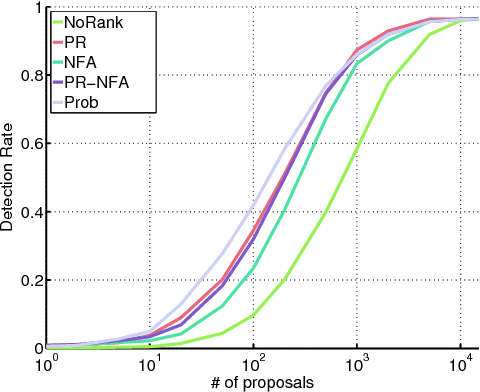
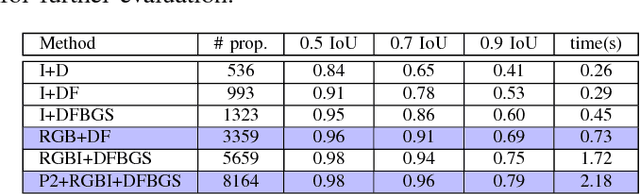
Object Proposals is a recent computer vision technique receiving increasing interest from the research community. Its main objective is to generate a relatively small set of bounding box proposals that are most likely to contain objects of interest. The use of Object Proposals techniques in the scene text understanding field is innovative. Motivated by the success of powerful while expensive techniques to recognize words in a holistic way, Object Proposals techniques emerge as an alternative to the traditional text detectors. In this paper we study to what extent the existing generic Object Proposals methods may be useful for scene text understanding. Also, we propose a new Object Proposals algorithm that is specifically designed for text and compare it with other generic methods in the state of the art. Experiments show that our proposal is superior in its ability of producing good quality word proposals in an efficient way. The source code of our method is made publicly available.
A Fast Hierarchical Method for Multi-script and Arbitrary Oriented Scene Text Extraction
Jul 28, 2014
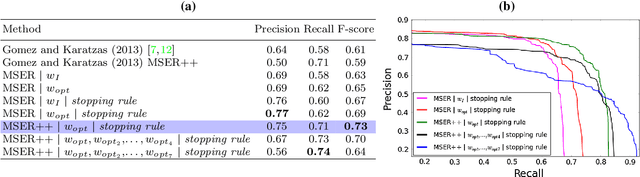

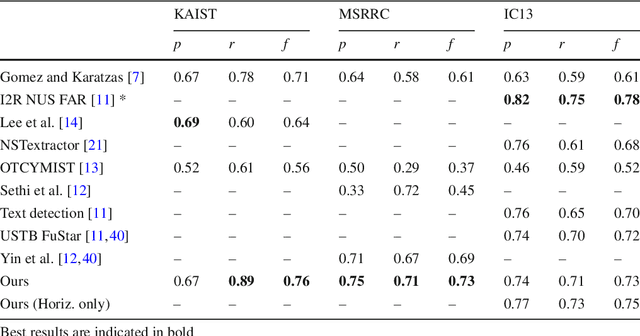
Typography and layout lead to the hierarchical organisation of text in words, text lines, paragraphs. This inherent structure is a key property of text in any script and language, which has nonetheless been minimally leveraged by existing text detection methods. This paper addresses the problem of text segmentation in natural scenes from a hierarchical perspective. Contrary to existing methods, we make explicit use of text structure, aiming directly to the detection of region groupings corresponding to text within a hierarchy produced by an agglomerative similarity clustering process over individual regions. We propose an optimal way to construct such an hierarchy introducing a feature space designed to produce text group hypotheses with high recall and a novel stopping rule combining a discriminative classifier and a probabilistic measure of group meaningfulness based in perceptual organization. Results obtained over four standard datasets, covering text in variable orientations and different languages, demonstrate that our algorithm, while being trained in a single mixed dataset, outperforms state of the art methods in unconstrained scenarios.