 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadText-1K: Text Detection & Recognition Dataset for Driving Videos
May 19, 2020



Perceiving text is crucial to understand semantics of outdoor scenes and hence is a critical requirement to build intelligent systems for driver assistance and self-driving. Most of the existing datasets for text detection and recognition comprise still images and are mostly compiled keeping text in mind. This paper introduces a new "RoadText-1K" dataset for text in driving videos. The dataset is 20 times larger than the existing largest dataset for text in videos. Our dataset comprises 1000 video clips of driving without any bias towards text and with annotations for text bounding boxes and transcriptions in every frame. State of the art methods for text detection, recognition and tracking are evaluated on the new dataset and the results signify the challenges in unconstrained driving videos compared to existing datasets. This suggests that RoadText-1K is suited for research and development of reading systems, robust enough to be incorporated into more complex downstream tasks like driver assistance and self-driving. The dataset can be found at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtext-1k
Fine-grained Image Classification and Retrieval by Combining Visual and Locally Pooled Textual Features
Jan 14, 2020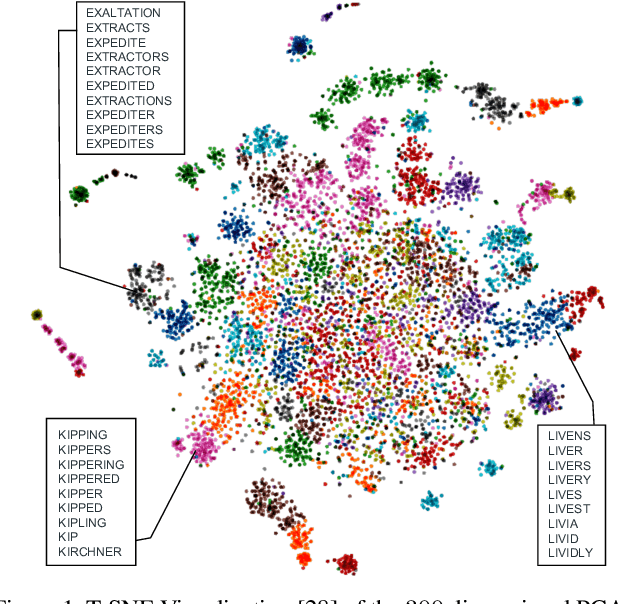
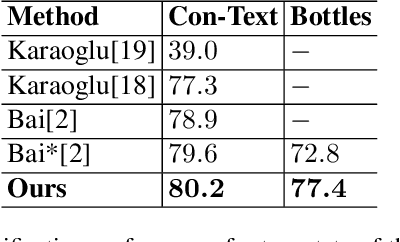
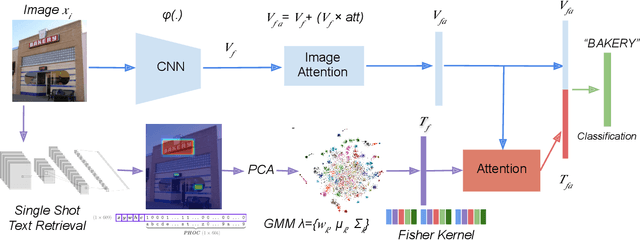
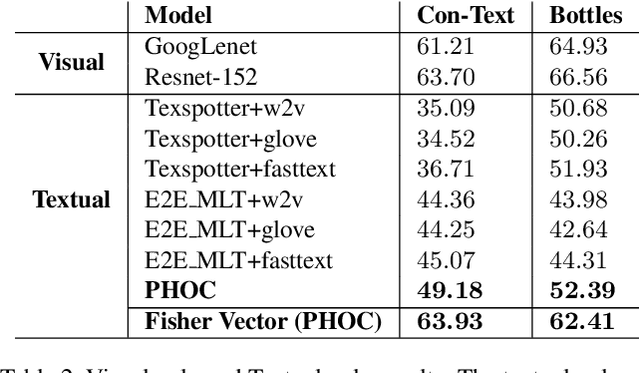
Text contained in an image carries high-level semantics that can be exploited to achieve richer image understanding. In particular, the mere presence of text provides strong guiding content that should be employed to tackle a diversity of computer vision tasks such as image retrieval, fine-grained classification, and visual question answering. In this paper, we address the problem of fine-grained classification and image retrieval by leveraging textual information along with visual cues to comprehend the existing intrinsic relation between the two modalities. The novelty of the proposed model consists of the usage of a PHOC descriptor to construct a bag of textual words along with a Fisher Vector Encoding that captures the morphology of text. This approach provides a stronger multimodal representation for this task and as our experiments demonstrate, it achieves state-of-the-art results on two different tasks, fine-grained classification and image retrieval.
Exploring Hate Speech Detection in Multimodal Publications
Oct 09, 2019
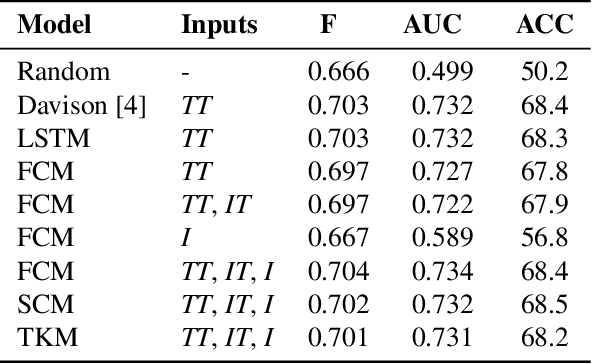
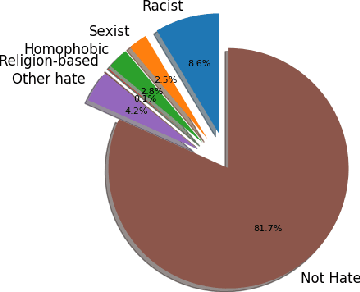
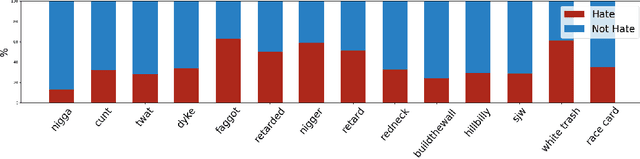
In this work we target the problem of hate speech detection in multimodal publications formed by a text and an image. We gather and annotate a large scale dataset from Twitter, MMHS150K, and propose different models that jointly analyze textual and visual information for hate speech detection, comparing them with unimodal detection. We provide quantitative and qualitative results and analyze the challenges of the proposed task. We find that, even though images are useful for the hate speech detection task, current multimodal models cannot outperform models analyzing only text. We discuss why and open the field and the dataset for further research.
ICDAR 2019 Competition on Scene Text Visual Question Answering
Jun 30, 2019
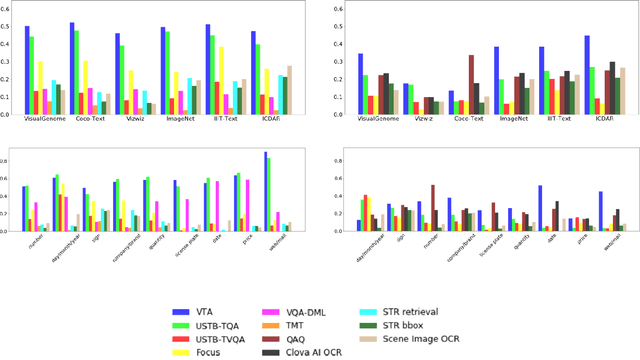
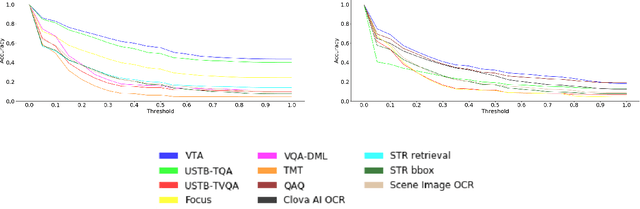
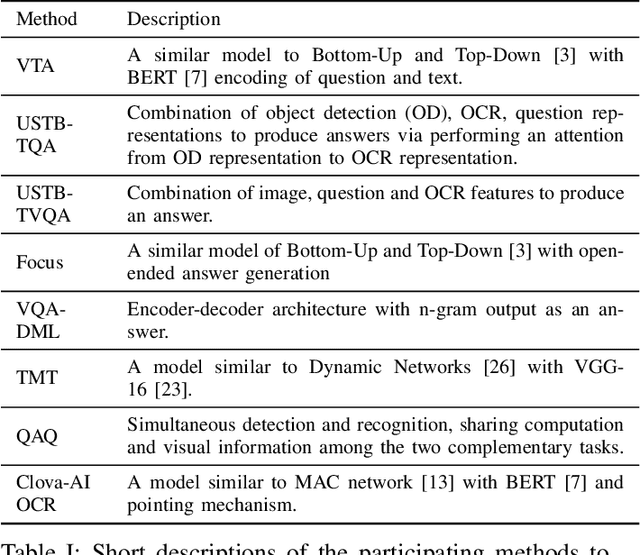
This paper presents final results of ICDAR 2019 Scene Text Visual Question Answering competition (ST-VQA). ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image. The competition introduces a new dataset comprising 23,038 images annotated with 31,791 question/answer pairs where the answer is always grounded on text instances present in the image. The images are taken from 7 different public computer vision datasets, covering a wide range of scenarios. The competition was structured in three tasks of increasing difficulty, that require reading the text in a scene and understanding it in the context of the scene, to correctly answer a given question. A novel evaluation metric is presented, which elegantly assesses both key capabilities expected from an optimal model: text recognition and image understanding. A detailed analysis of results from different participants is showcased, which provides insight into the current capabilities of VQA systems that can read. We firmly believe the dataset proposed in this challenge will be an important milestone to consider towards a path of more robust and general models that can exploit scene text to achieve holistic image understanding.
Selective Style Transfer for Text
Jun 04, 2019

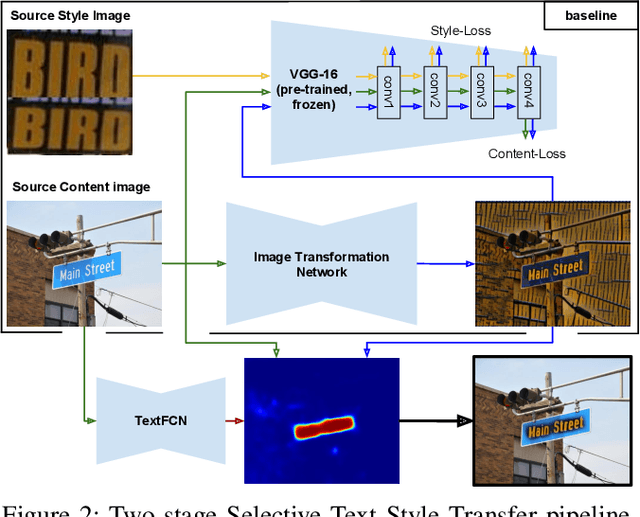
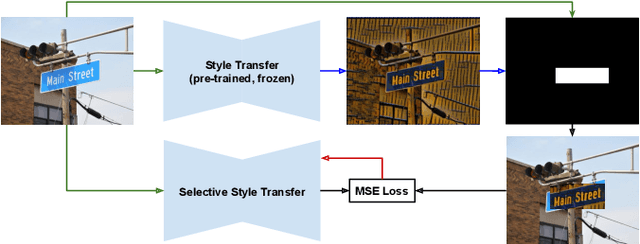
This paper explores the possibilities of image style transfer applied to text maintaining the original transcriptions. Results on different text domains (scene text, machine printed text and handwritten text) and cross modal results demonstrate that this is feasible, and open different research lines. Furthermore, two architectures for selective style transfer, which means transferring style to only desired image pixels, are proposed. Finally, scene text selective style transfer is evaluated as a data augmentation technique to expand scene text detection datasets, resulting in a boost of text detectors performance. Our implementation of the described models is publicly available.
Scene Text Visual Question Answering
May 31, 2019
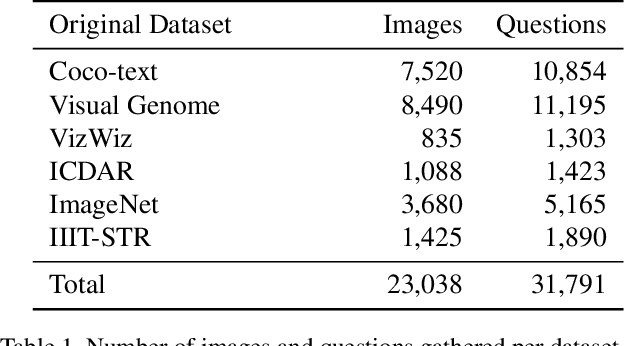
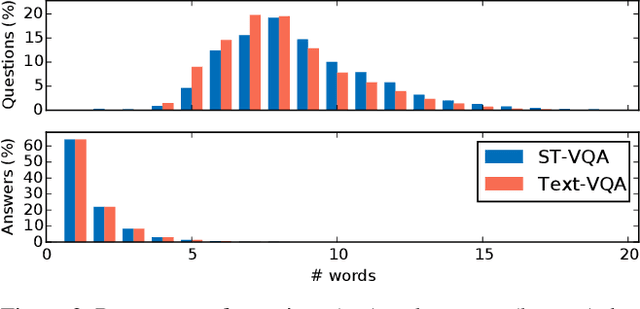
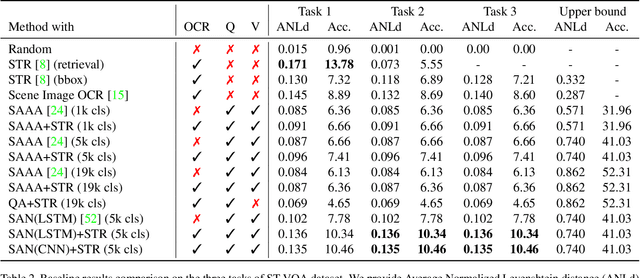
Current visual question answering datasets do not consider the rich semantic information conveyed by text within an image. In this work, we present a new dataset, ST-VQA, that aims to highlight the importance of exploiting high-level semantic information present in images as textual cues in the VQA process. We use this dataset to define a series of tasks of increasing difficulty for which reading the scene text in the context provided by the visual information is necessary to reason and generate an appropriate answer. We propose a new evaluation metric for these tasks to account both for reasoning errors as well as shortcomings of the text recognition module. In addition we put forward a series of baseline methods, which provide further insight to the newly released dataset, and set the scene for further research.
Good News, Everyone! Context driven entity-aware captioning for news images
Apr 02, 2019
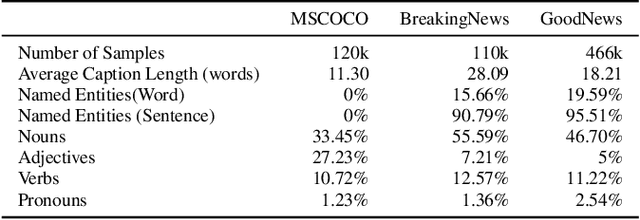
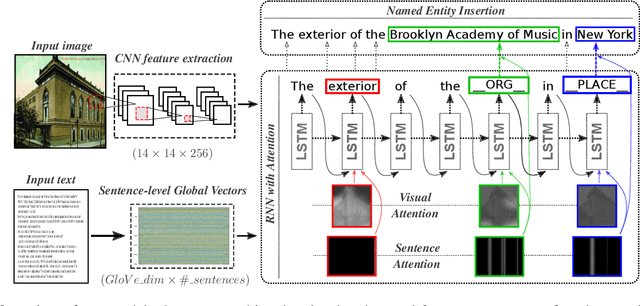
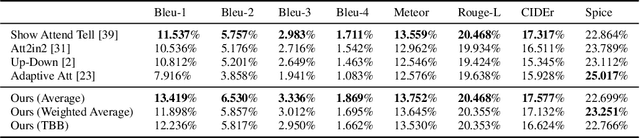
Current image captioning systems perform at a merely descriptive level, essentially enumerating the objects in the scene and their relations. Humans, on the contrary, interpret images by integrating several sources of prior knowledge of the world. In this work, we aim to take a step closer to producing captions that offer a plausible interpretation of the scene, by integrating such contextual information into the captioning pipeline. For this we focus on the captioning of images used to illustrate news articles. We propose a novel captioning method that is able to leverage contextual information provided by the text of news articles associated with an image. Our model is able to selectively draw information from the article guided by visual cues, and to dynamically extend the output dictionary to out-of-vocabulary named entities that appear in the context source. Furthermore we introduce `GoodNews', the largest news image captioning dataset in the literature and demonstrate state-of-the-art results.
Self-Supervised Visual Representations for Cross-Modal Retrieval
Jan 31, 2019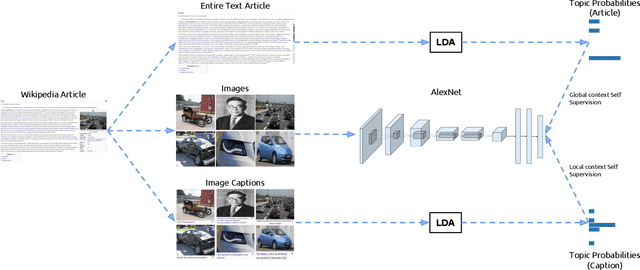
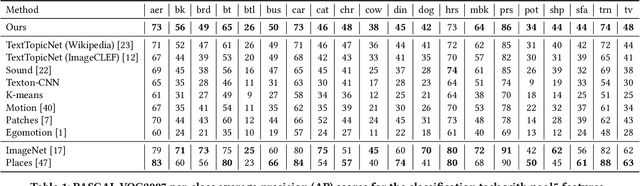

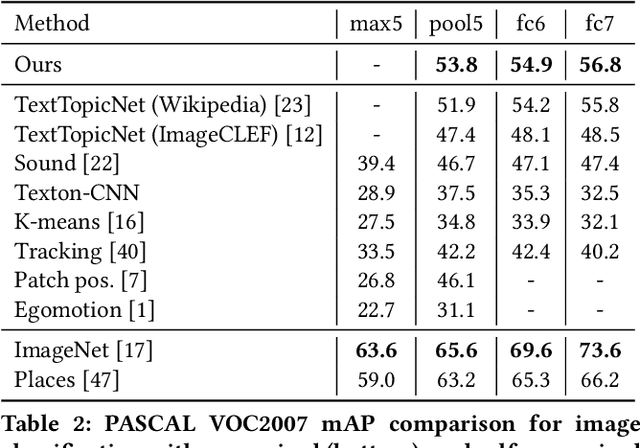
Cross-modal retrieval methods have been significantly improved in last years with the use of deep neural networks and large-scale annotated datasets such as ImageNet and Places. However, collecting and annotating such datasets requires a tremendous amount of human effort and, besides, their annotations are usually limited to discrete sets of popular visual classes that may not be representative of the richer semantics found on large-scale cross-modal retrieval datasets. In this paper, we present a self-supervised cross-modal retrieval framework that leverages as training data the correlations between images and text on the entire set of Wikipedia articles. Our method consists in training a CNN to predict: (1) the semantic context of the article in which an image is more probable to appear as an illustration (global context), and (2) the semantic context of its caption (local context). Our experiments demonstrate that the proposed method is not only capable of learning discriminative visual representations for solving vision tasks like image classification and object detection, but that the learned representations are better for cross-modal retrieval when compared to supervised pre-training of the network on the ImageNet dataset.
Self-Supervised Learning from Web Data for Multimodal Retrieval
Jan 07, 2019

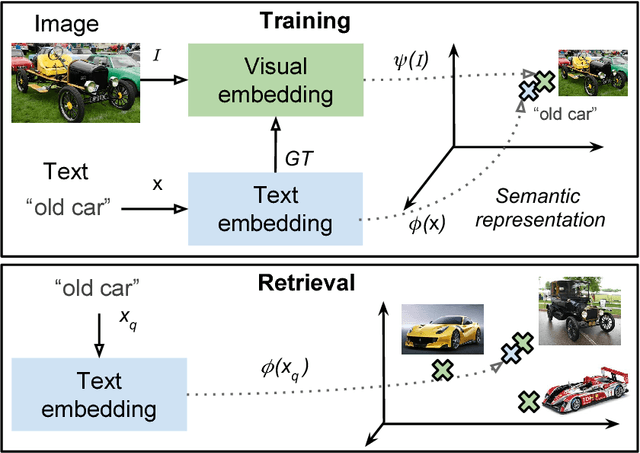
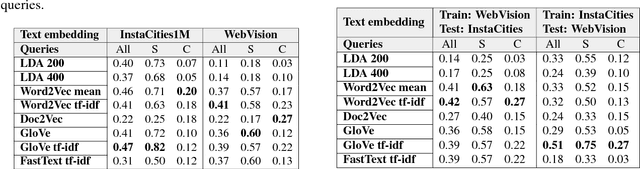
Self-Supervised learning from multimodal image and text data allows deep neural networks to learn powerful features with no need of human annotated data. Web and Social Media platforms provide a virtually unlimited amount of this multimodal data. In this work we propose to exploit this free available data to learn a multimodal image and text embedding, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the proposed pipeline can learn from images with associated textwithout supervision and analyze the semantic structure of the learnt joint image and text embedding space. We perform a thorough analysis and performance comparison of five different state of the art text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further, we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.
Learning from #Barcelona Instagram data what Locals and Tourists post about its Neighbourhoods
Aug 20, 2018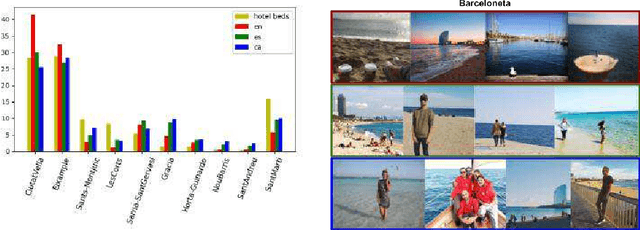

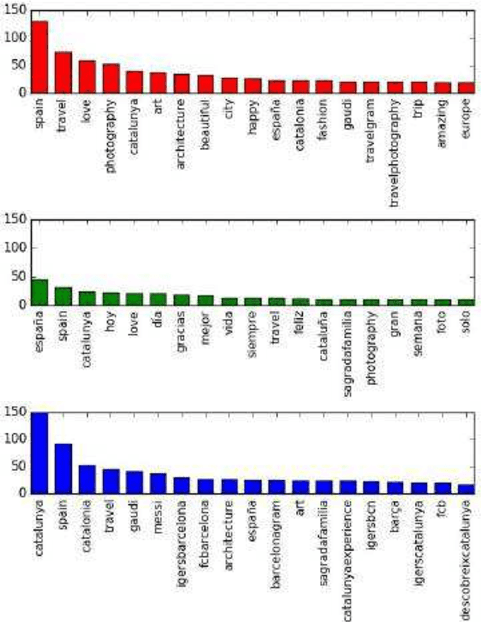
Massive tourism is becoming a big problem for some cities, such as Barcelona, due to its concentration in some neighborhoods. In this work we gather Instagram data related to Barcelona consisting on images-captions pairs and, using the text as a supervisory signal, we learn relations between images, words and neighborhoods. Our goal is to learn which visual elements appear in photos when people is posting about each neighborhood. We perform a language separate treatment of the data and show that it can be extrapolated to a tourists and locals separate analysis, and that tourism is reflected in Social Media at a neighborhood level. The presented pipeline allows analyzing the differences between the images that tourists and locals associate to the different neighborhoods. The proposed method, which can be extended to other cities or subjects, proves that Instagram data can be used to train multi-modal (image and text) machine learning models that are useful to analyze publications about a city at a neighborhood level. We publish the collected dataset, InstaBarcelona and the code used in the analysis.