 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments
Mar 14, 2021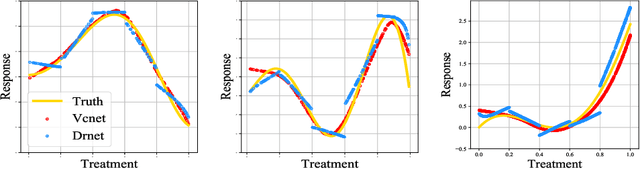
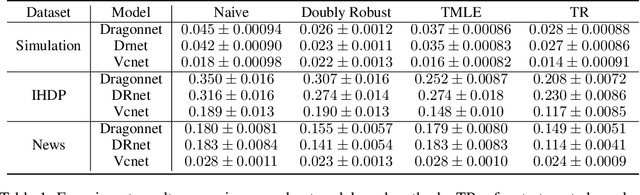
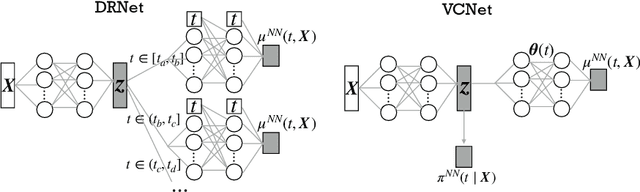
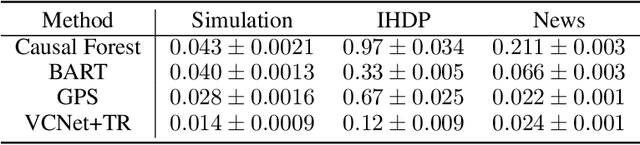
Motivated by the rising abundance of observational data with continuous treatments, we investigate the problem of estimating the average dose-response curve (ADRF). Available parametric methods are limited in their model space, and previous attempts in leveraging neural network to enhance model expressiveness relied on partitioning continuous treatment into blocks and using separate heads for each block; this however produces in practice discontinuous ADRFs. Therefore, the question of how to adapt the structure and training of neural network to estimate ADRFs remains open. This paper makes two important contributions. First, we propose a novel varying coefficient neural network (VCNet) that improves model expressiveness while preserving continuity of the estimated ADRF. Second, to improve finite sample performance, we generalize targeted regularization to obtain a doubly robust estimator of the whole ADRF curve.
Good Subnetworks Provably Exist: Pruning via Greedy Forward Selection
Mar 03, 2020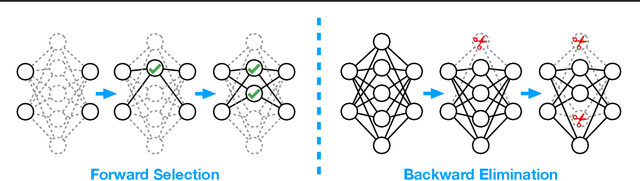
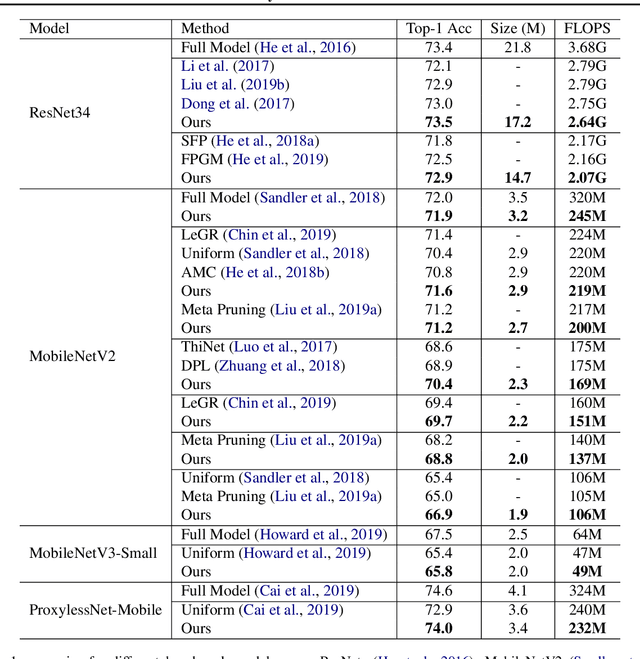
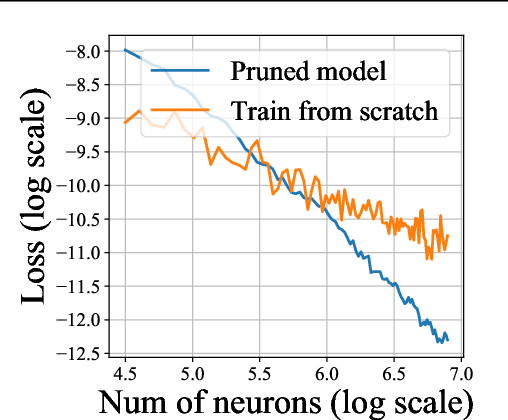
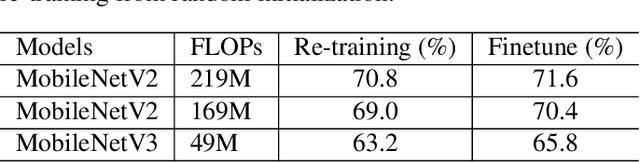
Recent empirical works show that large deep neural networks are often highly redundant and one can find much smaller subnetworks without a significant drop of accuracy. However, most existing methods of network pruning are empirical and heuristic, leaving it open whether good subnetworks provably exist, how to find them efficiently, and if network pruning can be provably better than direct training using gradient descent. We answer these problems positively by proposing a simple greedy selection approach for finding good subnetworks, which starts from an empty network and greedily adds important neurons from the large network. This differs from the existing methods based on backward elimination, which remove redundant neurons from the large network. Theoretically, applying our greedy selection strategy on sufficiently large pre-trained networks guarantees to find small subnetworks with lower loss than networks directly trained with gradient descent. Practically, we improve prior arts of network pruning on learning compact neural architectures on ImageNet, including ResNet, MobilenetV2/V3, and ProxylessNet. Our theory and empirical results on MobileNet suggest that we should fine-tune the pruned subnetworks to leverage the information from the large model, instead of re-training from new random initialization as suggested in \citet{liu2018rethinking}.