 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Collective, Probabilistic Approach to Schema Mapping: Appendix
Feb 11, 2017
In this appendix we provide additional supplementary material to "A Collective, Probabilistic Approach to Schema Mapping." We include an additional extended example, supplementary experiment details, and proof for the complexity result stated in the main paper.
Generic Statistical Relational Entity Resolution in Knowledge Graphs
Jul 04, 2016
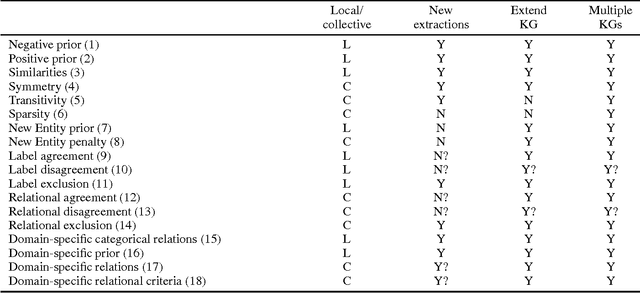


Entity resolution, the problem of identifying the underlying entity of references found in data, has been researched for many decades in many communities. A common theme in this research has been the importance of incorporating relational features into the resolution process. Relational entity resolution is particularly important in knowledge graphs (KGs), which have a regular structure capturing entities and their interrelationships. We identify three major problems in KG entity resolution: (1) intra-KG reference ambiguity; (2) inter-KG reference ambiguity; and (3) ambiguity when extending KGs with new facts. We implement a framework that generalizes across these three settings and exploits this regular structure of KGs. Our framework has many advantages over custom solutions widely deployed in industry, including collective inference, scalability, and interpretability. We apply our framework to two real-world KG entity resolution problems, ambiguity in NELL and merging data from Freebase and MusicBrainz, demonstrating the importance of relational features.
Adaptive Neighborhood Graph Construction for Inference in Multi-Relational Networks
Jul 02, 2016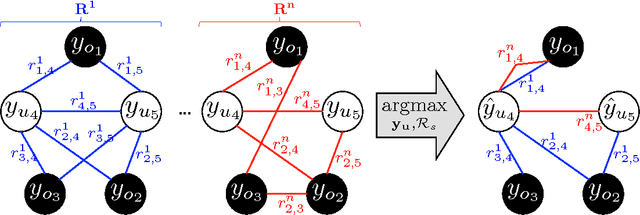
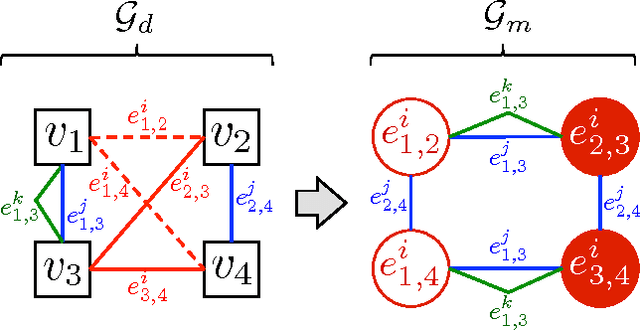
A neighborhood graph, which represents the instances as vertices and their relations as weighted edges, is the basis of many semi-supervised and relational models for node labeling and link prediction. Most methods employ a sequential process to construct the neighborhood graph. This process often consists of generating a candidate graph, pruning the candidate graph to make a neighborhood graph, and then performing inference on the variables (i.e., nodes) in the neighborhood graph. In this paper, we propose a framework that can dynamically adapt the neighborhood graph based on the states of variables from intermediate inference results, as well as structural properties of the relations connecting them. A key strength of our framework is its ability to handle multi-relational data and employ varying amounts of relations for each instance based on the intermediate inference results. We formulate the link prediction task as inference on neighborhood graphs, and include preliminary results illustrating the effects of different strategies in our proposed framework.
Value of Information Lattice: Exploiting Probabilistic Independence for Effective Feature Subset Acquisition
Jan 16, 2014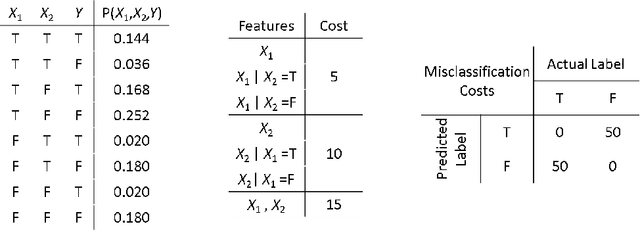
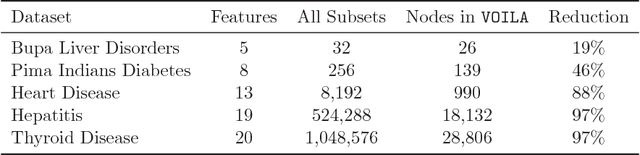
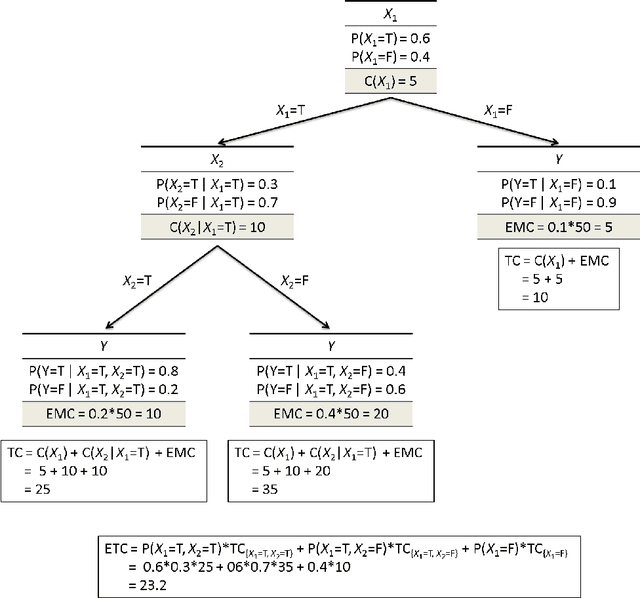
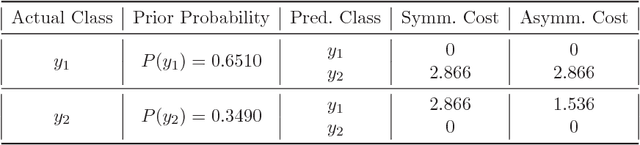
We address the cost-sensitive feature acquisition problem, where misclassifying an instance is costly but the expected misclassification cost can be reduced by acquiring the values of the missing features. Because acquiring the features is costly as well, the objective is to acquire the right set of features so that the sum of the feature acquisition cost and misclassification cost is minimized. We describe the Value of Information Lattice (VOILA), an optimal and efficient feature subset acquisition framework. Unlike the common practice, which is to acquire features greedily, VOILA can reason with subsets of features. VOILA efficiently searches the space of possible feature subsets by discovering and exploiting conditional independence properties between the features and it reuses probabilistic inference computations to further speed up the process. Through empirical evaluation on five medical datasets, we show that the greedy strategy is often reluctant to acquire features, as it cannot forecast the benefit of acquiring multiple features in combination.
Hinge-loss Markov Random Fields: Convex Inference for Structured Prediction
Sep 26, 2013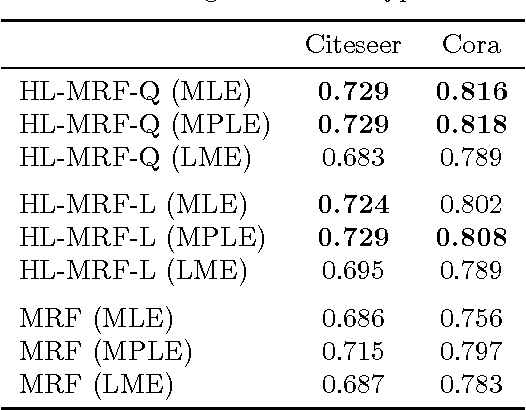

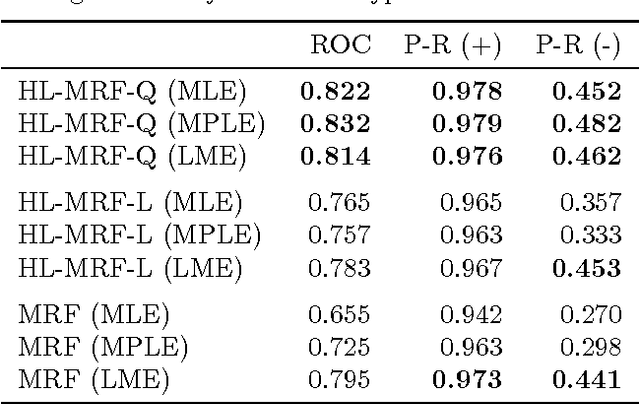
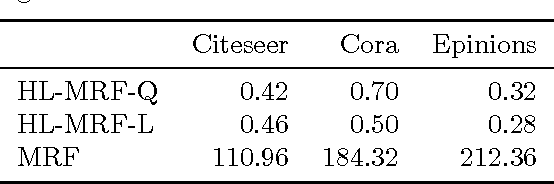
Graphical models for structured domains are powerful tools, but the computational complexities of combinatorial prediction spaces can force restrictions on models, or require approximate inference in order to be tractable. Instead of working in a combinatorial space, we use hinge-loss Markov random fields (HL-MRFs), an expressive class of graphical models with log-concave density functions over continuous variables, which can represent confidences in discrete predictions. This paper demonstrates that HL-MRFs are general tools for fast and accurate structured prediction. We introduce the first inference algorithm that is both scalable and applicable to the full class of HL-MRFs, and show how to train HL-MRFs with several learning algorithms. Our experiments show that HL-MRFs match or surpass the predictive performance of state-of-the-art methods, including discrete models, in four application domains.
A Hypergraph-Partitioned Vertex Programming Approach for Large-scale Consensus Optimization
Aug 30, 2013


In modern data science problems, techniques for extracting value from big data require performing large-scale optimization over heterogenous, irregularly structured data. Much of this data is best represented as multi-relational graphs, making vertex programming abstractions such as those of Pregel and GraphLab ideal fits for modern large-scale data analysis. In this paper, we describe a vertex-programming implementation of a popular consensus optimization technique known as the alternating direction of multipliers (ADMM). ADMM consensus optimization allows elegant solution of complex objectives such as inference in rich probabilistic models. We also introduce a novel hypergraph partitioning technique that improves over state-of-the-art partitioning techniques for vertex programming and significantly reduces the communication cost by reducing the number of replicated nodes up to an order of magnitude. We implemented our algorithm in GraphLab and measure scaling performance on a variety of realistic bipartite graph distributions and a large synthetic voter-opinion analysis application. In our experiments, we are able to achieve a 50% improvement in runtime over the current state-of-the-art GraphLab partitioning scheme.
Graph-based Generalization Bounds for Learning Binary Relations
May 31, 2013We investigate the generalizability of learned binary relations: functions that map pairs of instances to a logical indicator. This problem has application in numerous areas of machine learning, such as ranking, entity resolution and link prediction. Our learning framework incorporates an example labeler that, given a sequence $X$ of $n$ instances and a desired training size $m$, subsamples $m$ pairs from $X \times X$ without replacement. The challenge in analyzing this learning scenario is that pairwise combinations of random variables are inherently dependent, which prevents us from using traditional learning-theoretic arguments. We present a unified, graph-based analysis, which allows us to analyze this dependence using well-known graph identities. We are then able to bound the generalization error of learned binary relations using Rademacher complexity and algorithmic stability. The rate of uniform convergence is partially determined by the labeler's subsampling process. We thus examine how various assumptions about subsampling affect generalization; under a natural random subsampling process, our bounds guarantee $\tilde{O}(1/\sqrt{n})$ uniform convergence.
Multi-relational Learning Using Weighted Tensor Decomposition with Modular Loss
May 31, 2013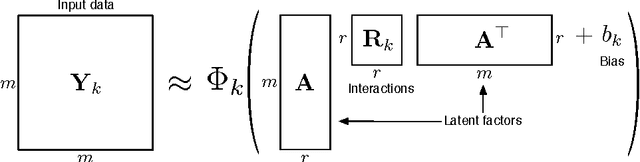
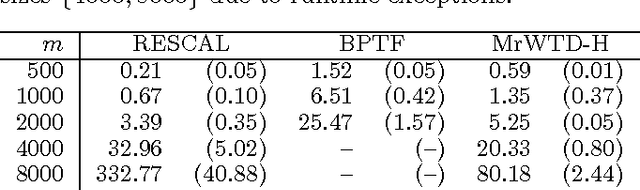
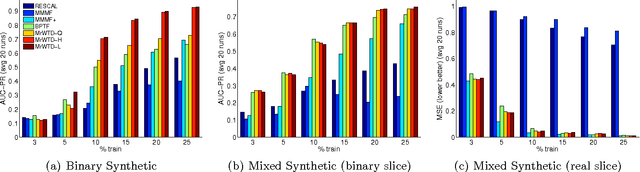
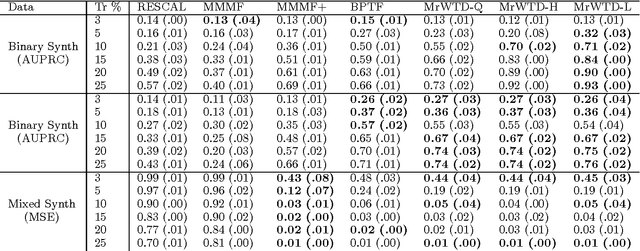
We propose a modular framework for multi-relational learning via tensor decomposition. In our learning setting, the training data contains multiple types of relationships among a set of objects, which we represent by a sparse three-mode tensor. The goal is to predict the values of the missing entries. To do so, we model each relationship as a function of a linear combination of latent factors. We learn this latent representation by computing a low-rank tensor decomposition, using quasi-Newton optimization of a weighted objective function. Sparsity in the observed data is captured by the weighted objective, leading to improved accuracy when training data is limited. Exploiting sparsity also improves efficiency, potentially up to an order of magnitude over unweighted approaches. In addition, our framework accommodates arbitrary combinations of smooth, task-specific loss functions, making it better suited for learning different types of relations. For the typical cases of real-valued functions and binary relations, we propose several loss functions and derive the associated parameter gradients. We evaluate our method on synthetic and real data, showing significant improvements in both accuracy and scalability over related factorization techniques.
Scalable Text and Link Analysis with Mixed-Topic Link Models
Mar 28, 2013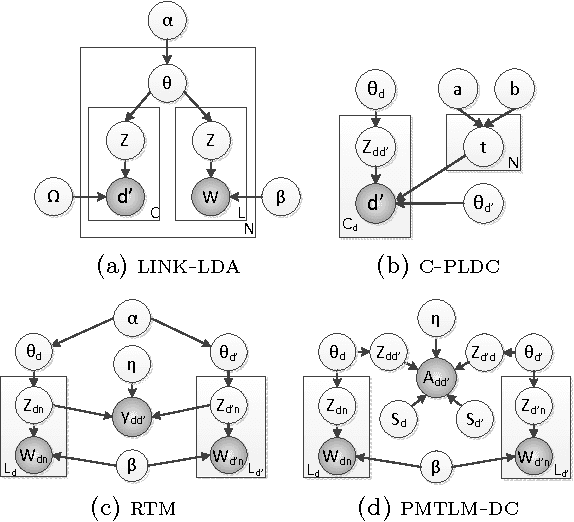
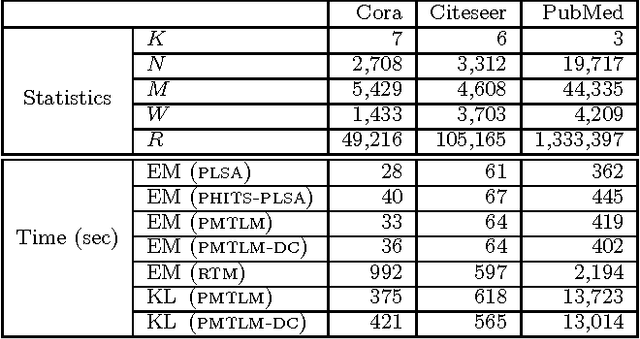
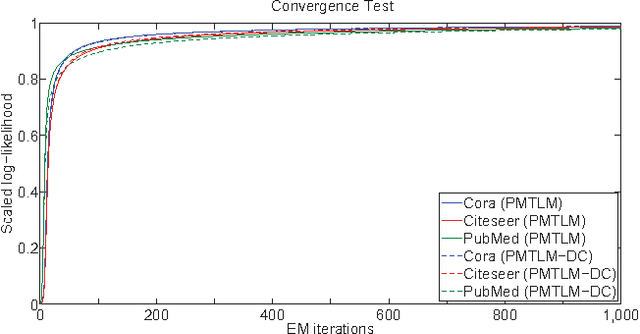
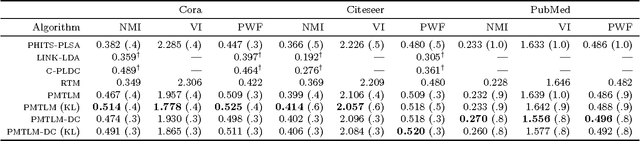
Many data sets contain rich information about objects, as well as pairwise relations between them. For instance, in networks of websites, scientific papers, and other documents, each node has content consisting of a collection of words, as well as hyperlinks or citations to other nodes. In order to perform inference on such data sets, and make predictions and recommendations, it is useful to have models that are able to capture the processes which generate the text at each node and the links between them. In this paper, we combine classic ideas in topic modeling with a variant of the mixed-membership block model recently developed in the statistical physics community. The resulting model has the advantage that its parameters, including the mixture of topics of each document and the resulting overlapping communities, can be inferred with a simple and scalable expectation-maximization algorithm. We test our model on three data sets, performing unsupervised topic classification and link prediction. For both tasks, our model outperforms several existing state-of-the-art methods, achieving higher accuracy with significantly less computation, analyzing a data set with 1.3 million words and 44 thousand links in a few minutes.
* 11 pages, 4 figures
Utility Elicitation as a Classification Problem
Jan 30, 2013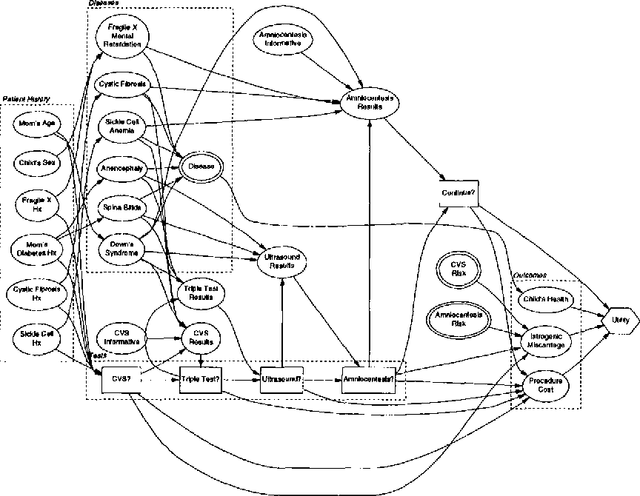
We investigate the application of classification techniques to utility elicitation. In a decision problem, two sets of parameters must generally be elicited: the probabilities and the utilities. While the prior and conditional probabilities in the model do not change from user to user, the utility models do. Thus it is necessary to elicit a utility model separately for each new user. Elicitation is long and tedious, particularly if the outcome space is large and not decomposable. There are two common approaches to utility function elicitation. The first is to base the determination of the users utility function solely ON elicitation OF qualitative preferences.The second makes assumptions about the form AND decomposability OF the utility function.Here we take a different approach: we attempt TO identify the new USERs utility function based on classification relative to a database of previously collected utility functions. We do this by identifying clusters of utility functions that minimize an appropriate distance measure. Having identified the clusters, we develop a classification scheme that requires many fewer and simpler assessments than full utility elicitation and is more robust than utility elicitation based solely on preferences. We have tested our algorithm on a small database of utility functions in a prenatal diagnosis domain and the results are quite promising.