 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Voice Conditioning for Denoising Diffusion TTS Models
Jun 05, 2022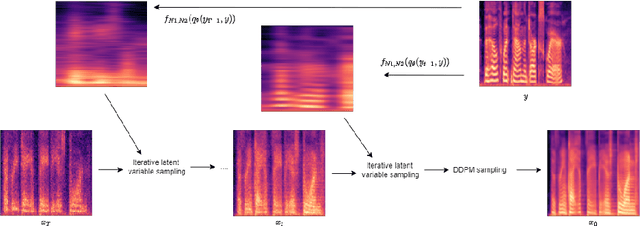
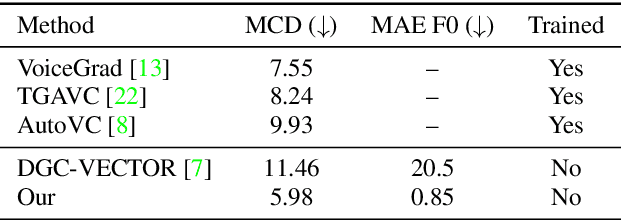
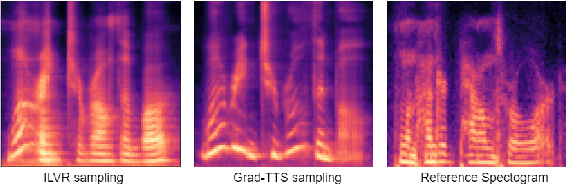
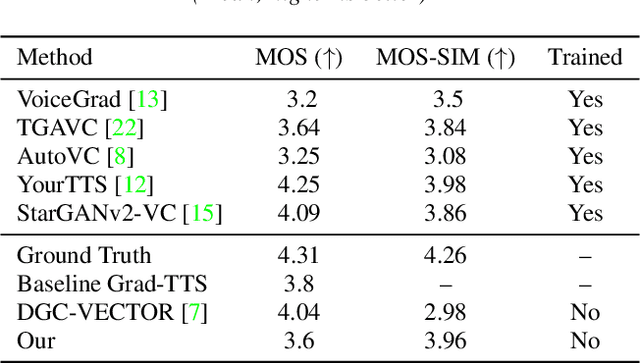
We present a novel way of conditioning a pretrained denoising diffusion speech model to produce speech in the voice of a novel person unseen during training. The method requires a short (~3 seconds) sample from the target person, and generation is steered at inference time, without any training steps. At the heart of the method lies a sampling process that combines the estimation of the denoising model with a low-pass version of the new speaker's sample. The objective and subjective evaluations show that our sampling method can generate a voice similar to that of the target speaker in terms of frequency, with an accuracy comparable to state-of-the-art methods, and without training.
Optimizing Relevance Maps of Vision Transformers Improves Robustness
Jun 02, 2022
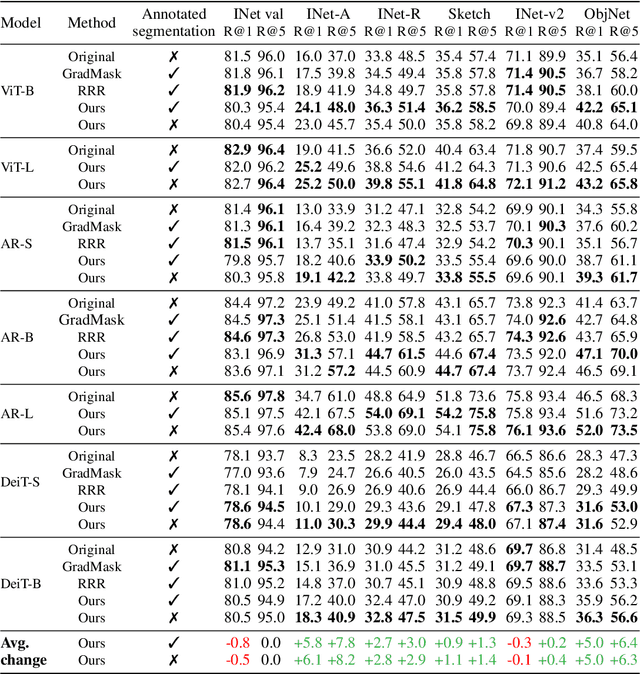
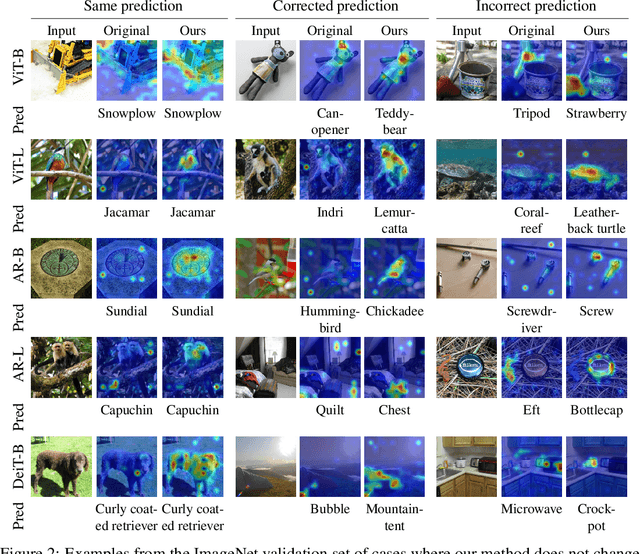
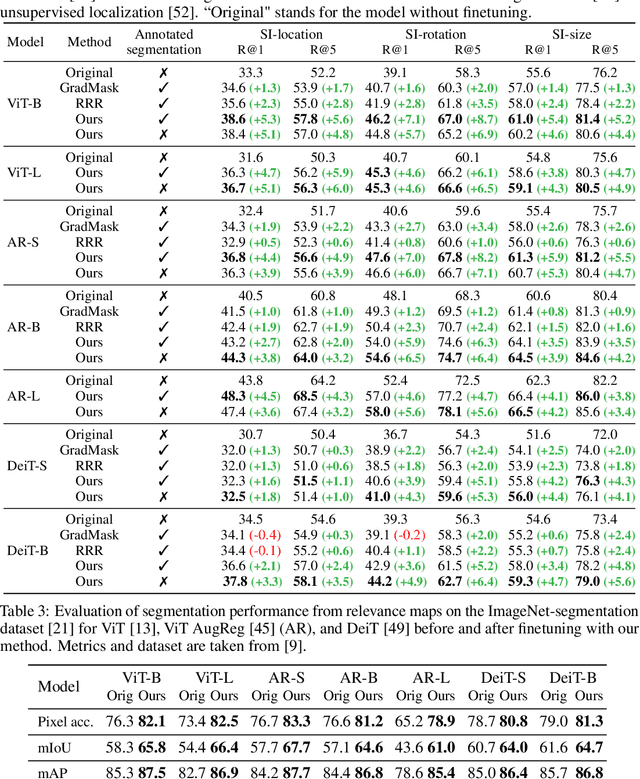
It has been observed that visual classification models often rely mostly on the image background, neglecting the foreground, which hurts their robustness to distribution changes. To alleviate this shortcoming, we propose to monitor the model's relevancy signal and manipulate it such that the model is focused on the foreground object. This is done as a finetuning step, involving relatively few samples consisting of pairs of images and their associated foreground masks. Specifically, we encourage the model's relevancy map (i) to assign lower relevance to background regions, (ii) to consider as much information as possible from the foreground, and (iii) we encourage the decisions to have high confidence. When applied to Vision Transformer (ViT) models, a marked improvement in robustness to domain shifts is observed. Moreover, the foreground masks can be obtained automatically, from a self-supervised variant of the ViT model itself; therefore no additional supervision is required.
SepIt: Approaching a Single Channel Speech Separation Bound
May 25, 2022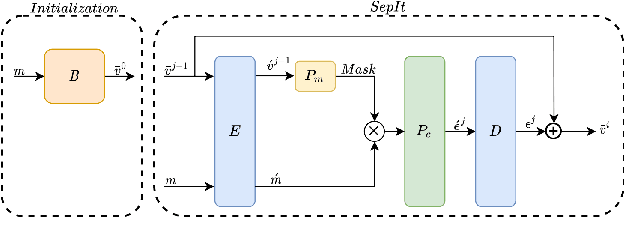
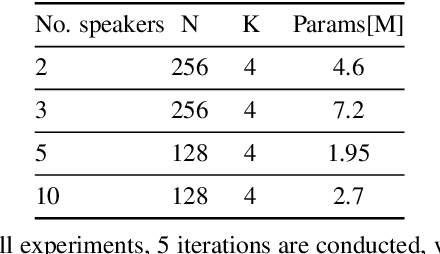
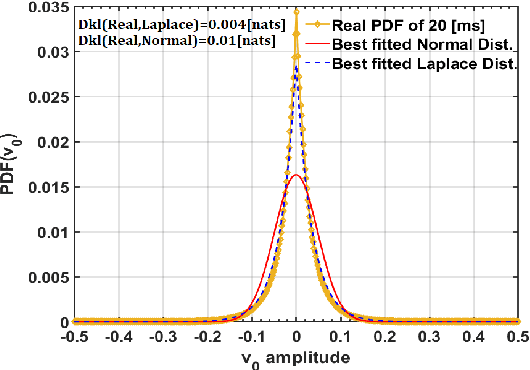
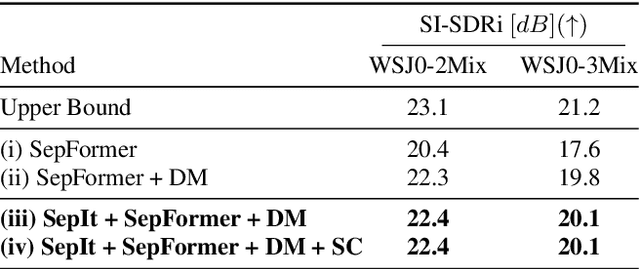
We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Neural Inverse Kinematics
May 22, 2022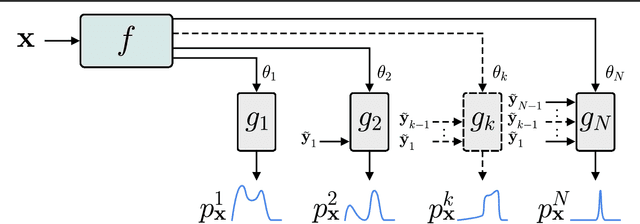

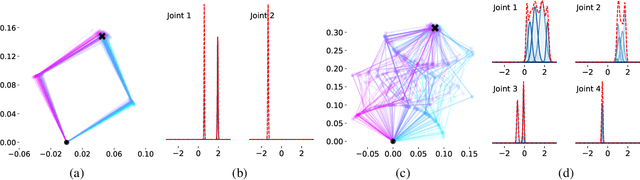
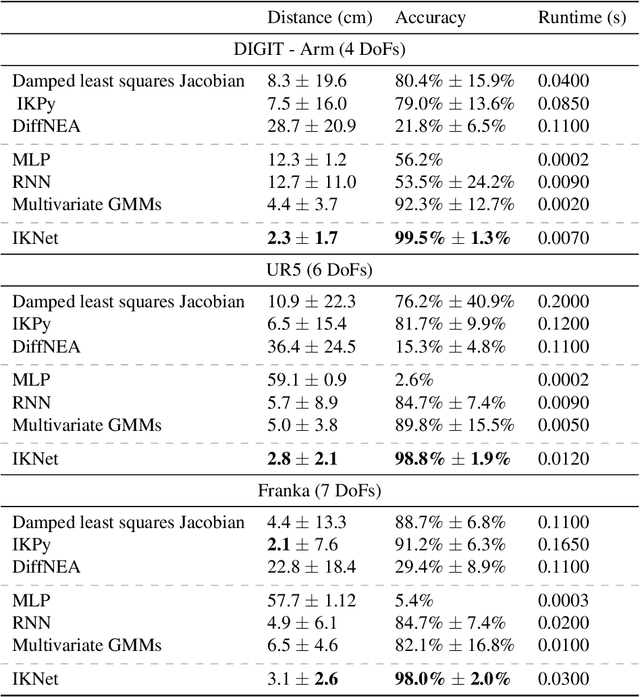
Inverse kinematic (IK) methods recover the parameters of the joints, given the desired position of selected elements in the kinematic chain. While the problem is well-defined and low-dimensional, it has to be solved rapidly, accounting for multiple possible solutions. In this work, we propose a neural IK method that employs the hierarchical structure of the problem to sequentially sample valid joint angles conditioned on the desired position and on the preceding joints along the chain. In our solution, a hypernetwork $f$ recovers the parameters of multiple primary networks {$g_1,g_2,\dots,g_N$, where $N$ is the number of joints}, such that each $g_i$ outputs a distribution of possible joint angles, and is conditioned on the sampled values obtained from the previous primary networks $g_j, j<i$. The hypernetwork can be trained on readily available pairs of matching joint angles and positions, without observing multiple solutions. At test time, a high-variance joint distribution is presented, by sampling sequentially from the primary networks. We demonstrate the advantage of the proposed method both in comparison to other IK methods for isolated instances of IK and with regard to following the path of the end effector in Cartesian space.
On Disentangled and Locally Fair Representations
May 05, 2022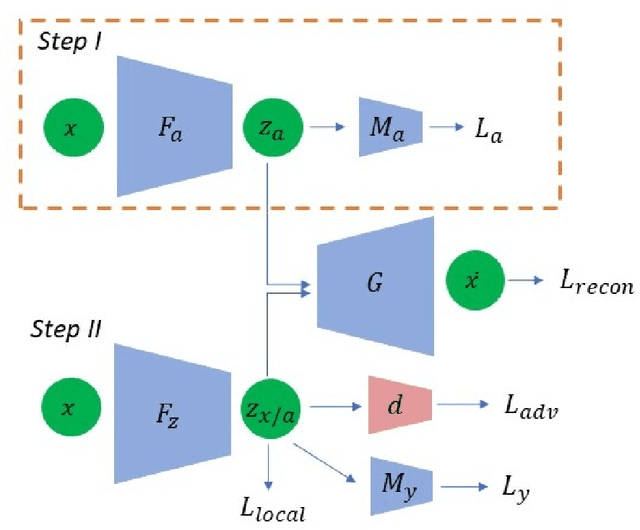
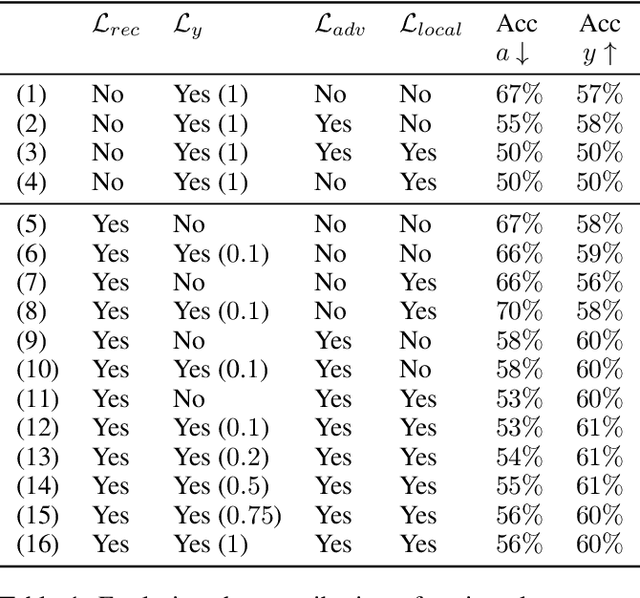
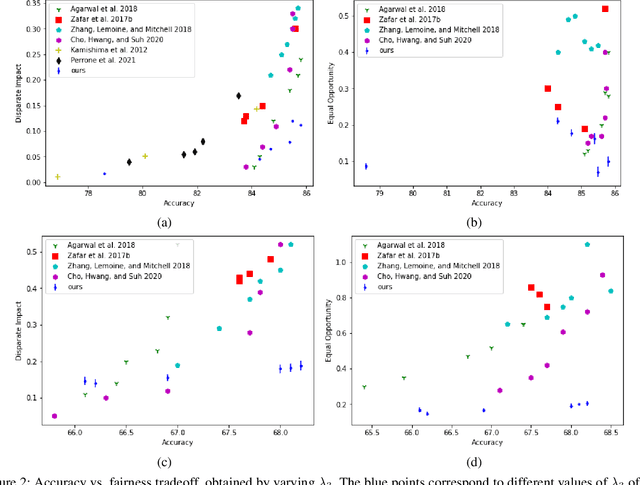
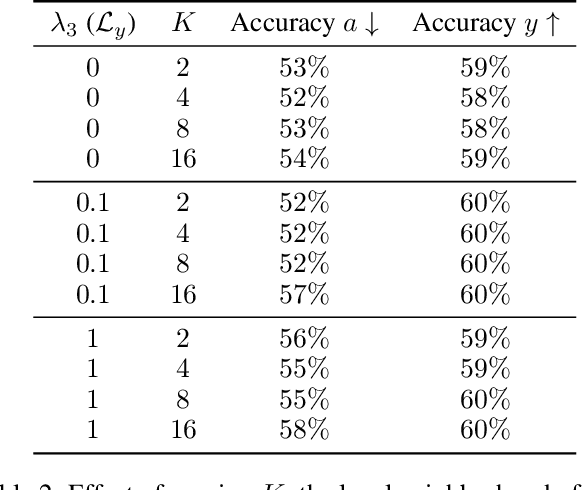
We study the problem of performing classification in a manner that is fair for sensitive groups, such as race and gender. This problem is tackled through the lens of disentangled and locally fair representations. We learn a locally fair representation, such that, under the learned representation, the neighborhood of each sample is balanced in terms of the sensitive attribute. For instance, when a decision is made to hire an individual, we ensure that the $K$ most similar hired individuals are racially balanced. Crucially, we ensure that similar individuals are found based on attributes not correlated to their race. To this end, we disentangle the embedding space into two representations. The first of which is correlated with the sensitive attribute while the second is not. We apply our local fairness objective only to the second, uncorrelated, representation. Through a set of experiments, we demonstrate the necessity of both disentangled and local fairness for obtaining fair and accurate representations. We evaluate our method on real-world settings such as predicting income and re-incarceration rate and demonstrate the advantage of our method.
No Token Left Behind: Explainability-Aided Image Classification and Generation
Apr 11, 2022
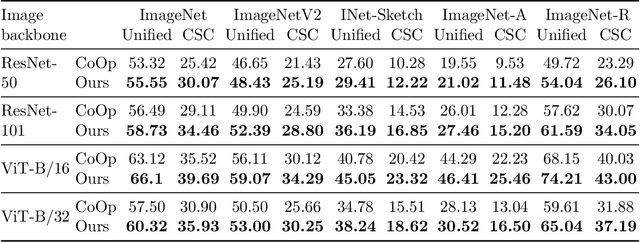


The application of zero-shot learning in computer vision has been revolutionized by the use of image-text matching models. The most notable example, CLIP, has been widely used for both zero-shot classification and guiding generative models with a text prompt. However, the zero-shot use of CLIP is unstable with respect to the phrasing of the input text, making it necessary to carefully engineer the prompts used. We find that this instability stems from a selective similarity score, which is based only on a subset of the semantically meaningful input tokens. To mitigate it, we present a novel explainability-based approach, which adds a loss term to ensure that CLIP focuses on all relevant semantic parts of the input, in addition to employing the CLIP similarity loss used in previous works. When applied to one-shot classification through prompt engineering, our method yields an improvement in the recognition rate, without additional training or fine-tuning. Additionally, we show that CLIP guidance of generative models using our method significantly improves the generated images. Finally, we demonstrate a novel use of CLIP guidance for text-based image generation with spatial conditioning on object location, by requiring the image explainability heatmap for each object to be confined to a pre-determined bounding box.
End to End Lip Synchronization with a Temporal AutoEncoder
Mar 30, 2022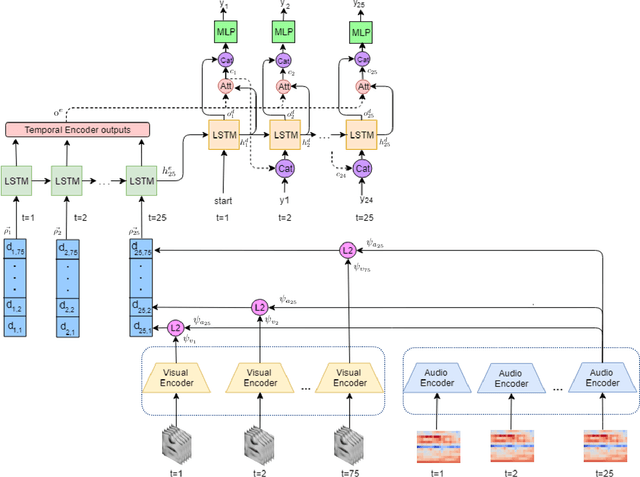
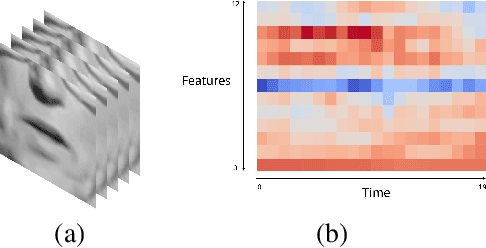
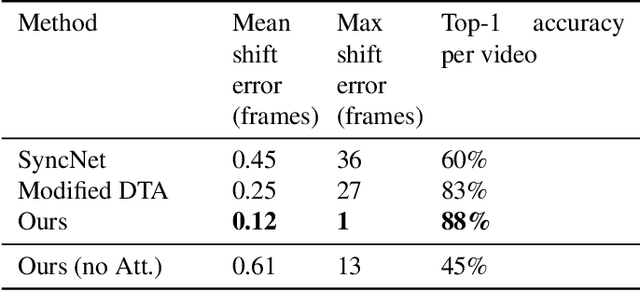
We study the problem of syncing the lip movement in a video with the audio stream. Our solution finds an optimal alignment using a dual-domain recurrent neural network that is trained on synthetic data we generate by dropping and duplicating video frames. Once the alignment is found, we modify the video in order to sync the two sources. Our method is shown to greatly outperform the literature methods on a variety of existing and new benchmarks. As an application, we demonstrate our ability to robustly align text-to-speech generated audio with an existing video stream. Our code and samples are available at https://github.com/itsyoavshalev/End-to-End-Lip-Synchronization-with-a-Temporal-AutoEncoder.
Error Correction Code Transformer
Mar 27, 2022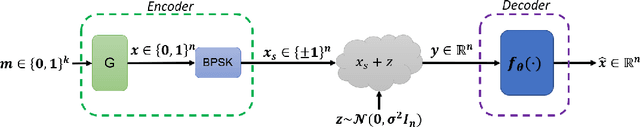
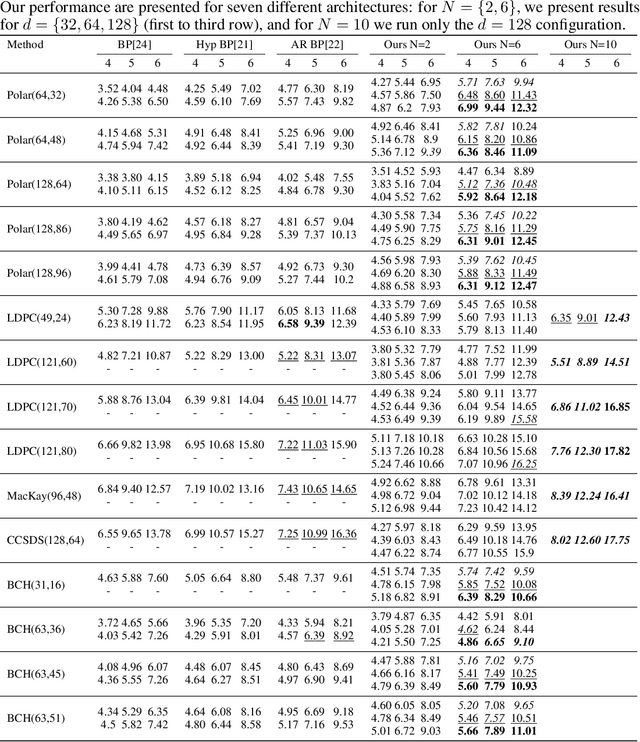

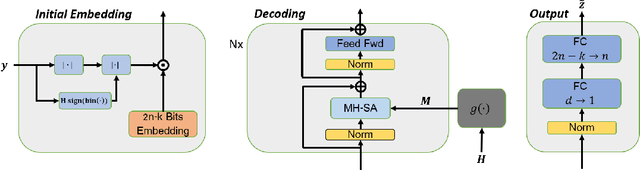
Error correction code is a major part of the communication physical layer, ensuring the reliable transfer of data over noisy channels. Recently, neural decoders were shown to outperform classical decoding techniques. However, the existing neural approaches present strong overfitting due to the exponential training complexity, or a restrictive inductive bias due to reliance on Belief Propagation. Recently, Transformers have become methods of choice in many applications thanks to their ability to represent complex interactions between elements. In this work, we propose to extend for the first time the Transformer architecture to the soft decoding of linear codes at arbitrary block lengths. We encode each channel's output dimension to high dimension for better representation of the bits information to be processed separately. The element-wise processing allows the analysis of the channel output reliability, while the algebraic code and the interaction between the bits are inserted into the model via an adapted masked self-attention module. The proposed approach demonstrates the extreme power and flexibility of Transformers and outperforms existing state-of-the-art neural decoders by large margins at a fraction of their time complexity.
Dynamically-Scaled Deep Canonical Correlation Analysis
Mar 24, 2022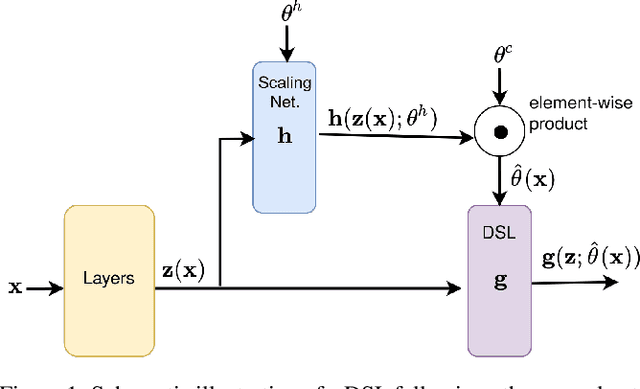
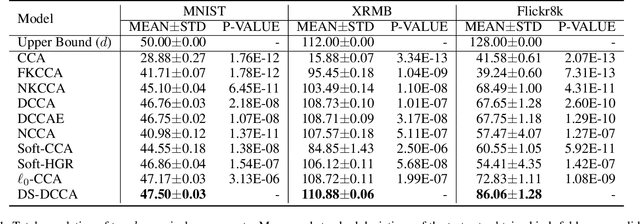
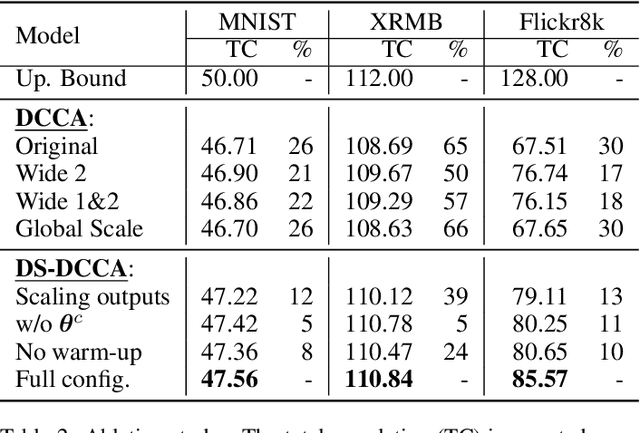
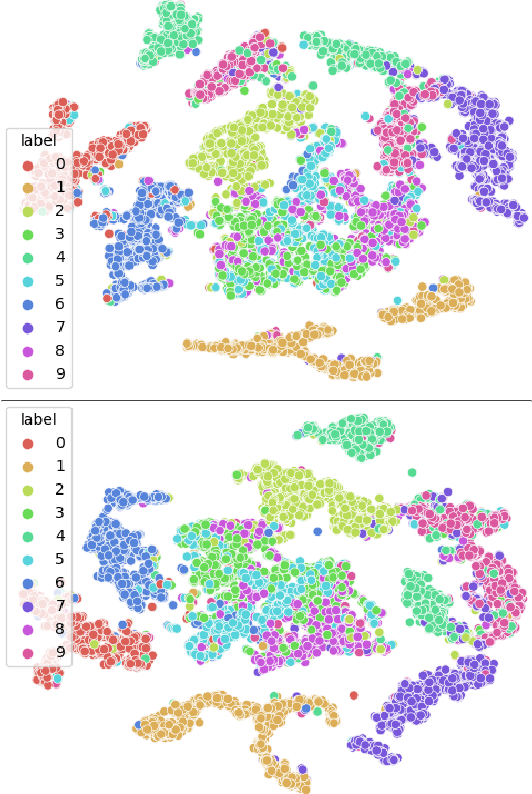
Canonical Correlation Analysis (CCA) is a method for feature extraction of two views by finding maximally correlated linear projections of them. Several variants of CCA have been introduced in the literature, in particular, variants based on deep neural networks for learning highly correlated nonlinear transformations of two views. As these models are parameterized conventionally, their learnable parameters remain independent of the inputs after the training process, which may limit their capacity for learning highly correlated representations. We introduce a novel dynamic scaling method for training an input-dependent canonical correlation model. In our deep-CCA models, the parameters of the last layer are scaled by a second neural network that is conditioned on the model's input, resulting in a parameterization that is dependent on the input samples. We evaluate our model on multiple datasets and demonstrate that the learned representations are more correlated in comparison to the conventionally-parameterized CCA-based models and also obtain preferable retrieval results. Our code is available at https://github.com/tomerfr/DynamicallyScaledDeepCCA.
Dynamic Dual-Output Diffusion Models
Mar 15, 2022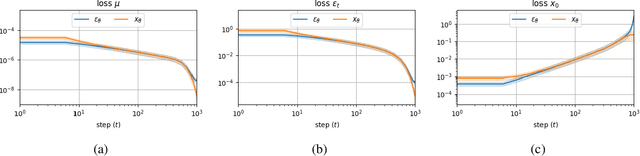
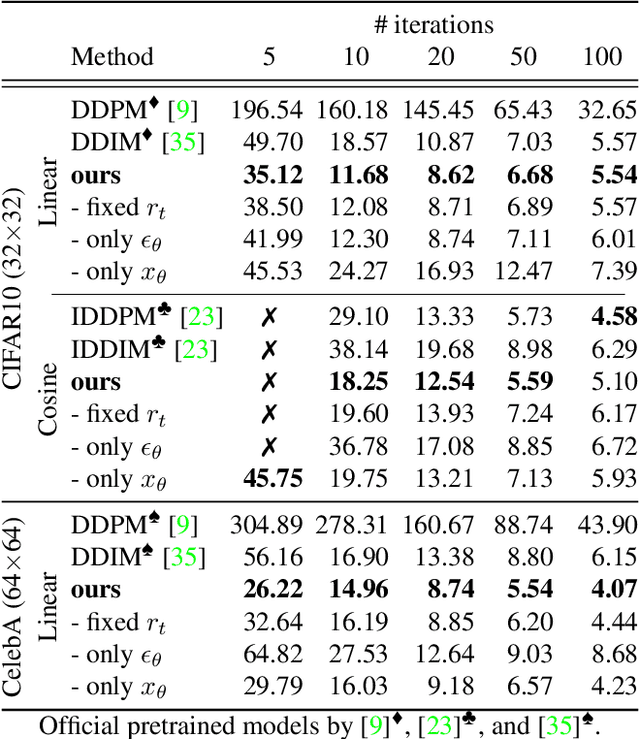
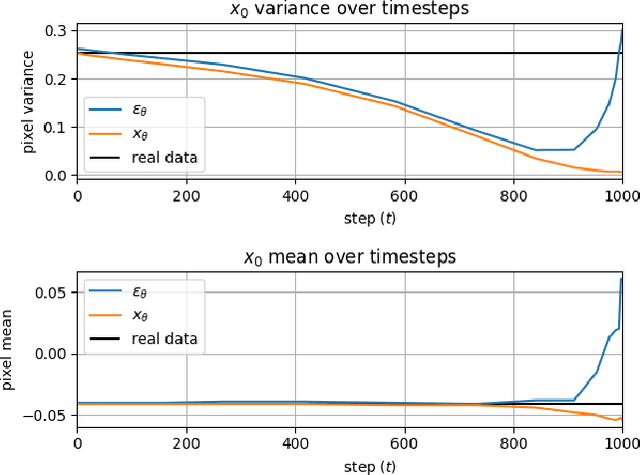
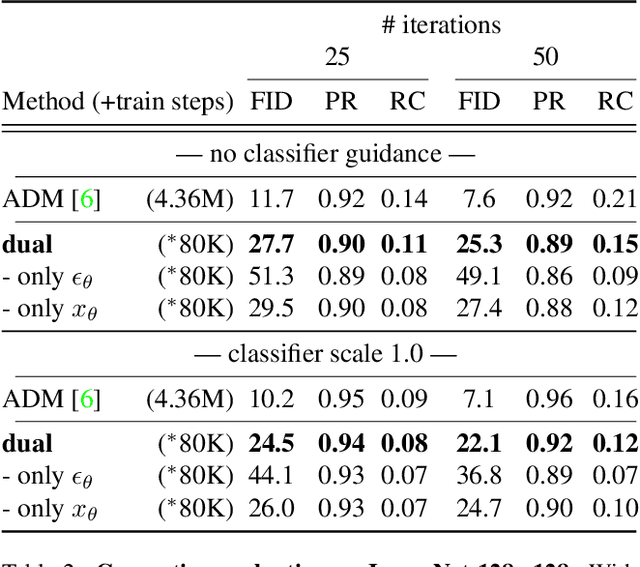
Iterative denoising-based generation, also known as denoising diffusion models, has recently been shown to be comparable in quality to other classes of generative models, and even surpass them. Including, in particular, Generative Adversarial Networks, which are currently the state of the art in many sub-tasks of image generation. However, a major drawback of this method is that it requires hundreds of iterations to produce a competitive result. Recent works have proposed solutions that allow for faster generation with fewer iterations, but the image quality gradually deteriorates with increasingly fewer iterations being applied during generation. In this paper, we reveal some of the causes that affect the generation quality of diffusion models, especially when sampling with few iterations, and come up with a simple, yet effective, solution to mitigate them. We consider two opposite equations for the iterative denoising, the first predicts the applied noise, and the second predicts the image directly. Our solution takes the two options and learns to dynamically alternate between them through the denoising process. Our proposed solution is general and can be applied to any existing diffusion model. As we show, when applied to various SOTA architectures, our solution immediately improves their generation quality, with negligible added complexity and parameters. We experiment on multiple datasets and configurations and run an extensive ablation study to support these findings.