 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikibook-Bot - Automatic Generation of a Wikipedia Book
Dec 28, 2018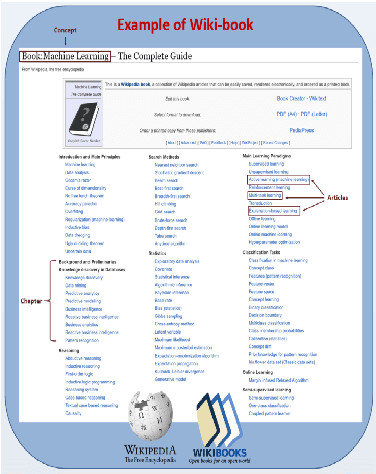

A Wikipedia book (known as Wikibook) is a collection of Wikipedia articles on a particular theme that is organized as a book. We propose Wikibook-Bot, a machine-learning based technique for automatically generating high quality Wikibooks based on a concept provided by the user. In order to create the Wikibook we apply machine learning algorithms to the different steps of the proposed technique. Firs, we need to decide whether an article belongs to a specific Wikibook - a classification task. Then, we need to divide the chosen articles into chapters - a clustering task - and finally, we deal with the ordering task which includes two subtasks: order articles within each chapter and order the chapters themselves. We propose a set of structural, text-based and unique Wikipedia features, and we show that by using these features, a machine learning classifier can successfully address the above challenges. The predictive performance of the proposed method is evaluated by comparing the auto-generated books to existing 407 Wikibooks which were manually generated by humans. For all the tasks we were able to obtain high and statistically significant results when comparing the Wikibook-bot books to books that were manually generated by Wikipedia contributors
Query-Efficient GAN Based Black-Box Attack Against Sequence Based Machine and Deep Learning Classifiers
Sep 22, 2018
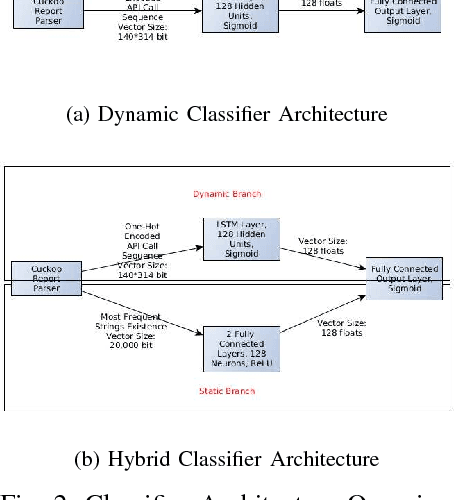

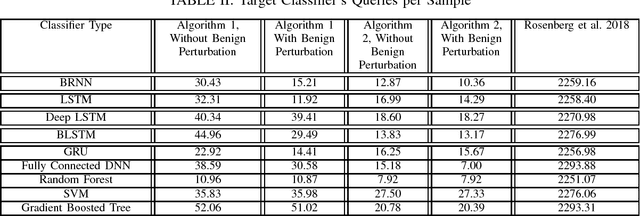
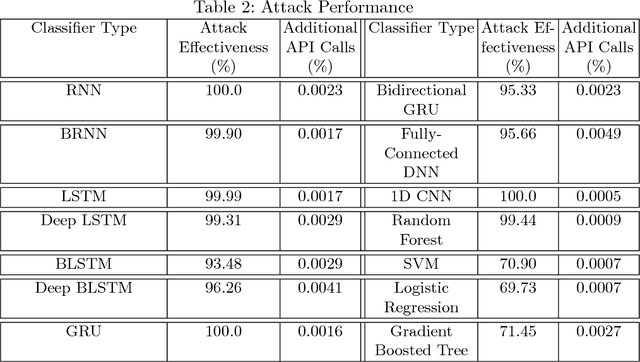
In this paper, we present a generic black-box attack, demonstrated against API call based machine learning malware classifiers. We generate adversarial examples combining sequences (API call sequences) and other features (e.g., printable strings) that will be misclassified by the classifier without affecting the malware functionality. Our attack minimizes the number of target classifier queries and only requires access to the predicted label of the attacked model (without the confidence level). We evaluate the attack's effectiveness against many classifiers such as RNN variants, DNN, SVM, GBDT, etc. We show that the attack requires fewer queries and less knowledge about the attacked model's architecture than other existing black-box attacks, making it optimal to attack cloud based models at a minimal cost. Finally, we discuss the robustness of this attack to existing defense mechanisms.
Generic Black-Box End-to-End Attack Against State of the Art API Call Based Malware Classifiers
Jun 24, 2018

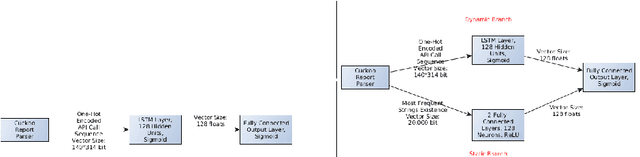
In this paper, we present a black-box attack against API call based machine learning malware classifiers, focusing on generating adversarial sequences combining API calls and static features (e.g., printable strings) that will be misclassified by the classifier without affecting the malware functionality. We show that this attack is effective against many classifiers due to the transferability principle between RNN variants, feed forward DNNs, and traditional machine learning classifiers such as SVM. We also implement GADGET, a software framework to convert any malware binary to a binary undetected by malware classifiers, using the proposed attack, without access to the malware source code.
Sampling High Throughput Data for Anomaly Detection of Data-Base Activity
Aug 14, 2017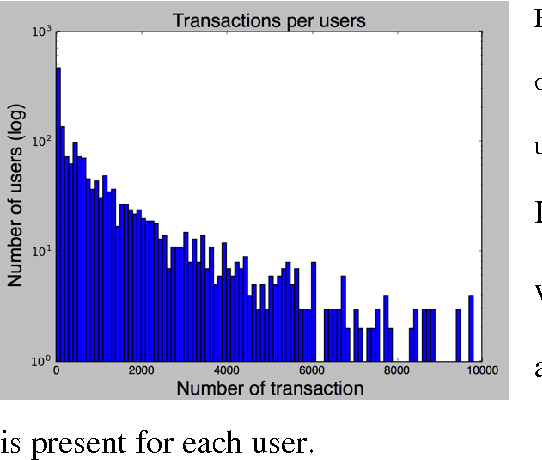
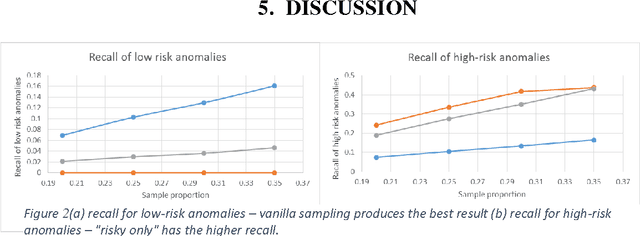
Data leakage and theft from databases is a dangerous threat to organizations. Data Security and Data Privacy protection systems (DSDP) monitor data access and usage to identify leakage or suspicious activities that should be investigated. Because of the high velocity nature of database systems, such systems audit only a portion of the vast number of transactions that take place. Anomalies are investigated by a Security Officer (SO) in order to choose the proper response. In this paper we investigate the effect of sampling methods based on the risk the transaction poses and propose a new method for "combined sampling" for capturing a more varied sample.
Language Models with Pre-Trained (GloVe) Word Embeddings
Feb 05, 2017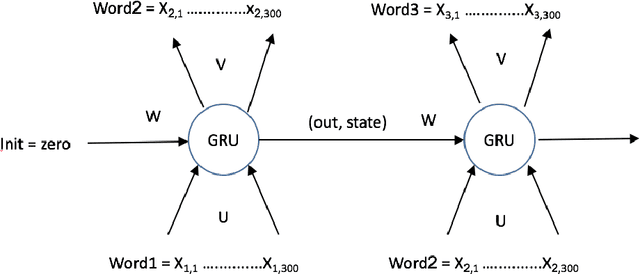
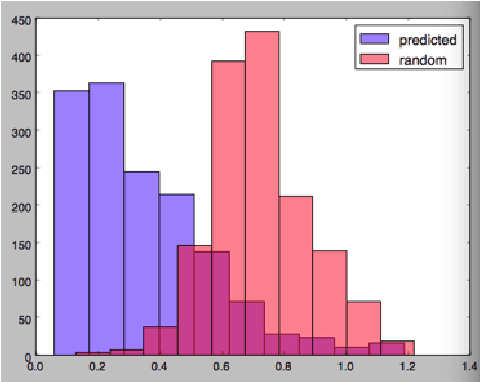
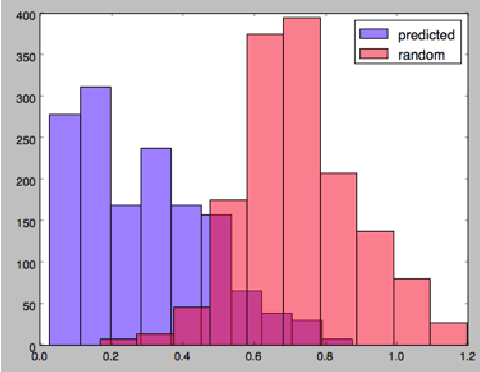
In this work we implement a training of a Language Model (LM), using Recurrent Neural Network (RNN) and GloVe word embeddings, introduced by Pennigton et al. in [1]. The implementation is following the general idea of training RNNs for LM tasks presented in [2], but is rather using Gated Recurrent Unit (GRU) [3] for a memory cell, and not the more commonly used LSTM [4].
Wikiometrics: A Wikipedia Based Ranking System
Jan 08, 2016
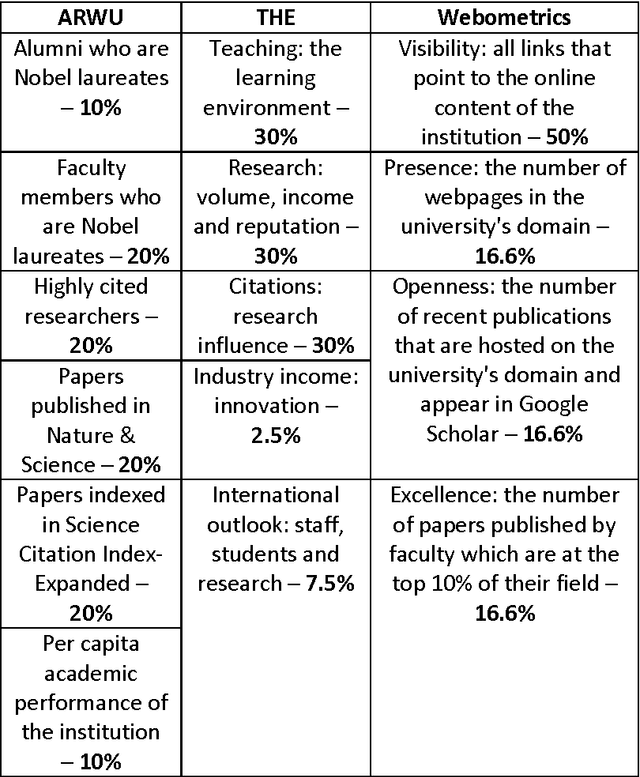
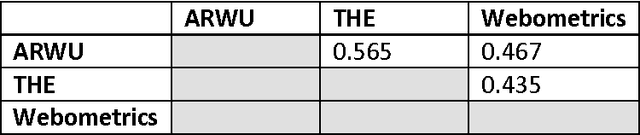
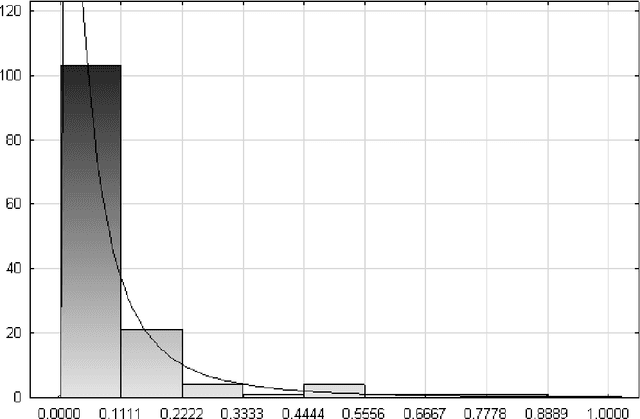
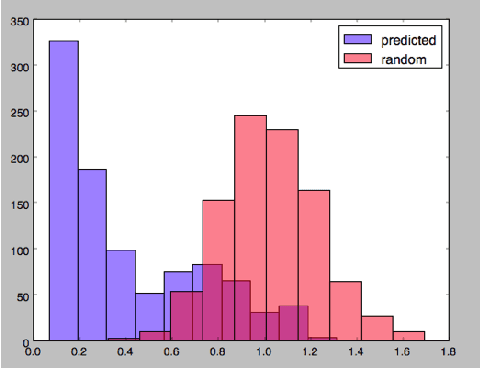
We present a new concept - Wikiometrics - the derivation of metrics and indicators from Wikipedia. Wikipedia provides an accurate representation of the real world due to its size, structure, editing policy and popularity. We demonstrate an innovative mining methodology, where different elements of Wikipedia - content, structure, editorial actions and reader reviews - are used to rank items in a manner which is by no means inferior to rankings produced by experts or other methods. We test our proposed method by applying it to two real-world ranking problems: top world universities and academic journals. Our proposed ranking methods were compared to leading and widely accepted benchmarks, and were found to be extremely correlative but with the advantage of the data being publically available.
Combining One-Class Classifiers via Meta-Learning
Jul 21, 2013
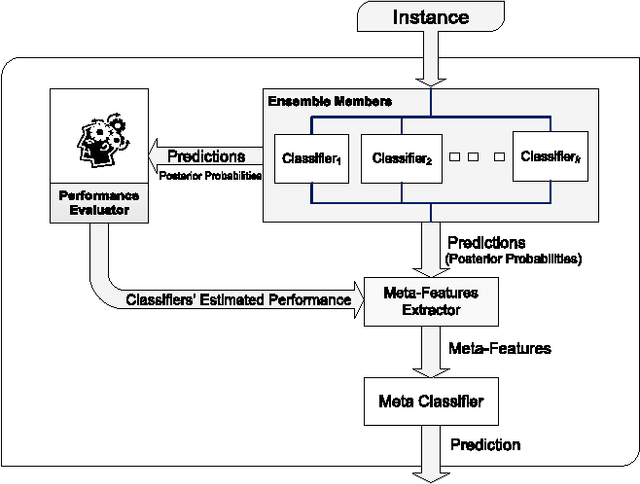
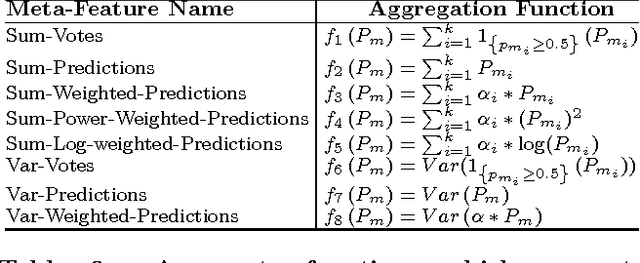
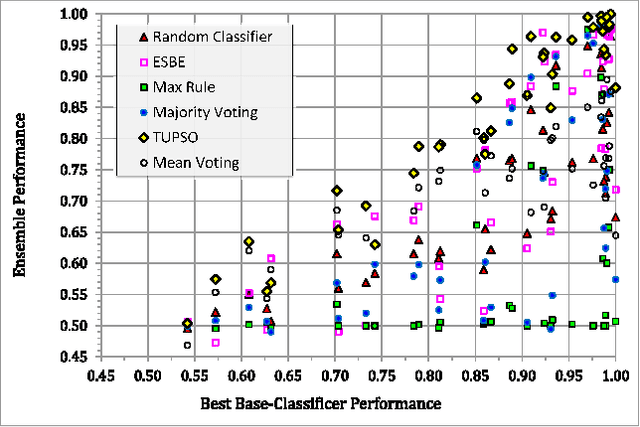
Selecting the best classifier among the available ones is a difficult task, especially when only instances of one class exist. In this work we examine the notion of combining one-class classifiers as an alternative for selecting the best classifier. In particular, we propose two new one-class classification performance measures to weigh classifiers and show that a simple ensemble that implements these measures can outperform the most popular one-class ensembles. Furthermore, we propose a new one-class ensemble scheme, TUPSO, which uses meta-learning to combine one-class classifiers. Our experiments demonstrate the superiority of TUPSO over all other tested ensembles and show that the TUPSO performance is statistically indistinguishable from that of the hypothetical best classifier.
Ensemble Methods for Multi-label Classification
Jul 06, 2013
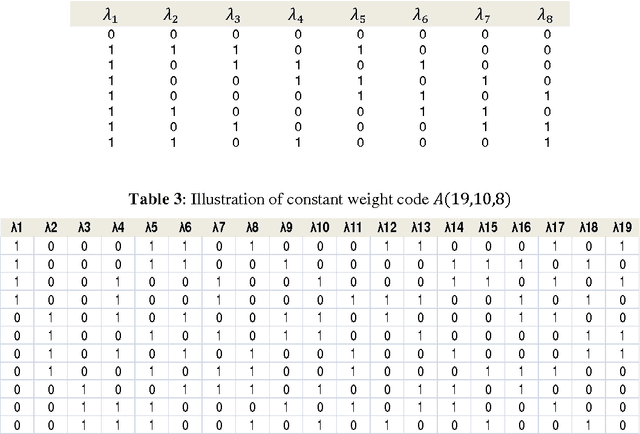

Ensemble methods have been shown to be an effective tool for solving multi-label classification tasks. In the RAndom k-labELsets (RAKEL) algorithm, each member of the ensemble is associated with a small randomly-selected subset of k labels. Then, a single label classifier is trained according to each combination of elements in the subset. In this paper we adopt a similar approach, however, instead of randomly choosing subsets, we select the minimum required subsets of k labels that cover all labels and meet additional constraints such as coverage of inter-label correlations. Construction of the cover is achieved by formulating the subset selection as a minimum set covering problem (SCP) and solving it by using approximation algorithms. Every cover needs only to be prepared once by offline algorithms. Once prepared, a cover may be applied to the classification of any given multi-label dataset whose properties conform with those of the cover. The contribution of this paper is two-fold. First, we introduce SCP as a general framework for constructing label covers while allowing the user to incorporate cover construction constraints. We demonstrate the effectiveness of this framework by proposing two construction constraints whose enforcement produces covers that improve the prediction performance of random selection. Second, we provide theoretical bounds that quantify the probabilities of random selection to produce covers that meet the proposed construction criteria. The experimental results indicate that the proposed methods improve multi-label classification accuracy and stability compared with the RAKEL algorithm and to other state-of-the-art algorithms.
Securing Your Transactions: Detecting Anomalous Patterns In XML Documents
Jun 05, 2013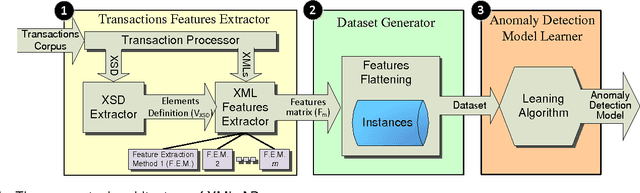
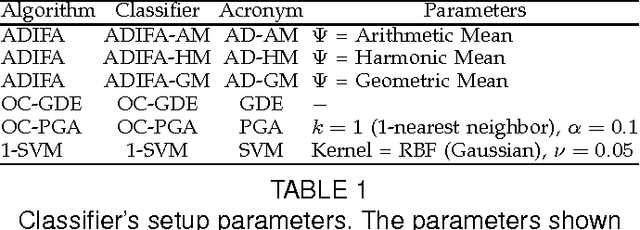

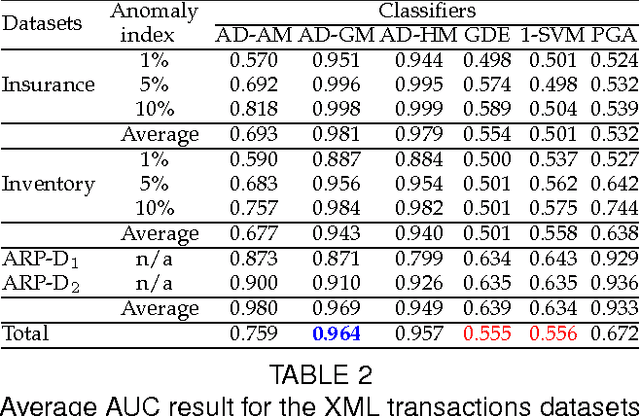
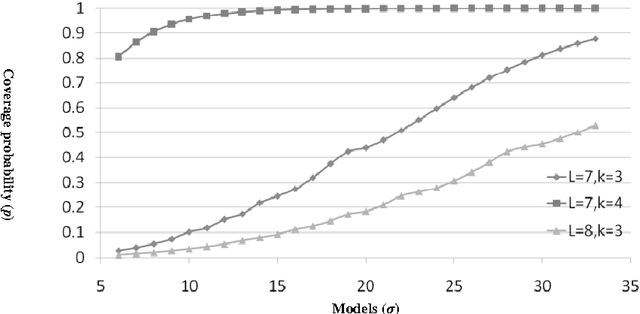
XML transactions are used in many information systems to store data and interact with other systems. Abnormal transactions, the result of either an on-going cyber attack or the actions of a benign user, can potentially harm the interacting systems and therefore they are regarded as a threat. In this paper we address the problem of anomaly detection and localization in XML transactions using machine learning techniques. We present a new XML anomaly detection framework, XML-AD. Within this framework, an automatic method for extracting features from XML transactions was developed as well as a practical method for transforming XML features into vectors of fixed dimensionality. With these two methods in place, the XML-AD framework makes it possible to utilize general learning algorithms for anomaly detection. Central to the functioning of the framework is a novel multi-univariate anomaly detection algorithm, ADIFA. The framework was evaluated on four XML transactions datasets, captured from real information systems, in which it achieved over 89% true positive detection rate with less than a 0.2% false positive rate.
Ensembles of Classifiers based on Dimensionality Reduction
May 19, 2013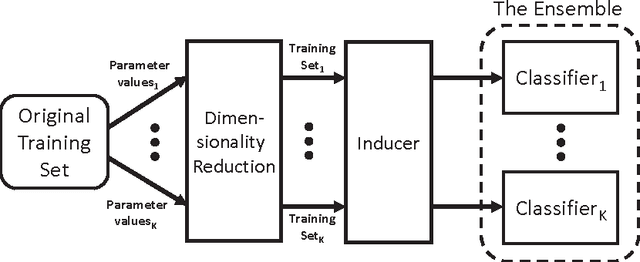
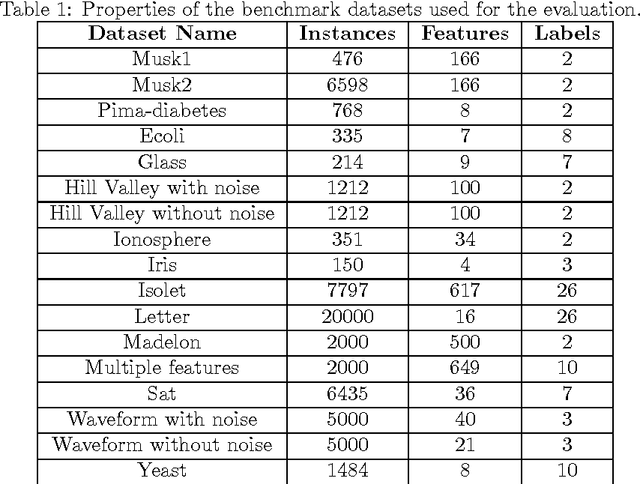
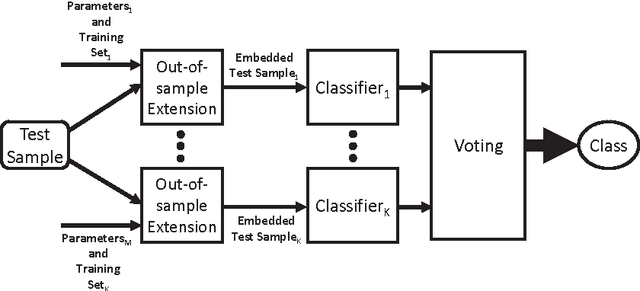
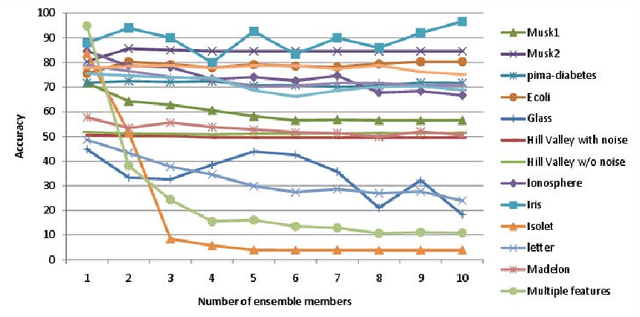
We present a novel approach for the construction of ensemble classifiers based on dimensionality reduction. Dimensionality reduction methods represent datasets using a small number of attributes while preserving the information conveyed by the original dataset. The ensemble members are trained based on dimension-reduced versions of the training set. These versions are obtained by applying dimensionality reduction to the original training set using different values of the input parameters. This construction meets both the diversity and accuracy criteria which are required to construct an ensemble classifier where the former criterion is obtained by the various input parameter values and the latter is achieved due to the decorrelation and noise reduction properties of dimensionality reduction. In order to classify a test sample, it is first embedded into the dimension reduced space of each individual classifier by using an out-of-sample extension algorithm. Each classifier is then applied to the embedded sample and the classification is obtained via a voting scheme. We present three variations of the proposed approach based on the Random Projections, the Diffusion Maps and the Random Subspaces dimensionality reduction algorithms. We also present a multi-strategy ensemble which combines AdaBoost and Diffusion Maps. A comparison is made with the Bagging, AdaBoost, Rotation Forest ensemble classifiers and also with the base classifier which does not incorporate dimensionality reduction. Our experiments used seventeen benchmark datasets from the UCI repository. The results obtained by the proposed algorithms were superior in many cases to other algorithms.