 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Nov 16, 2019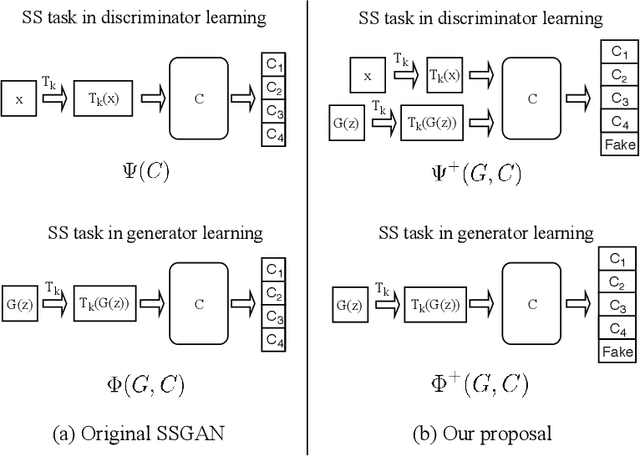
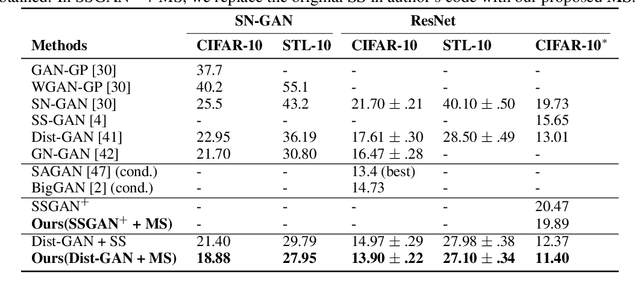


Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. In this work, we perform an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, we identify issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, we propose new SS tasks based on a multi-class minimax game. The competition between our proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. We provide both theoretical and empirical analysis to support that our proposed SS tasks have better convergence property. We conduct experiments to incorporate our proposed SS tasks into two different GAN baseline models. Our approach establishes state-of-the-art FID scores on CIFAR-10, CIFAR-100, STL-10, CelebA, Imagenet $32\times32$ and Stacked-MNIST datasets, outperforming existing works by considerable margins in some cases. Our unconditional GAN model approaches performance of conditional GAN without using labeled data. Our code: \url{https://github.com/tntrung/msgan}
Low-Rank Phase Retrieval via Variational Bayesian Learning
Nov 05, 2018



In this paper, we consider the problem of low-rank phase retrieval whose objective is to estimate a complex low-rank matrix from magnitude-only measurements. We propose a hierarchical prior model for low-rank phase retrieval, in which a Gaussian-Wishart hierarchical prior is placed on the underlying low-rank matrix to promote the low-rankness of the matrix. Based on the proposed hierarchical model, a variational expectation-maximization (EM) algorithm is developed. The proposed method is less sensitive to the choice of the initialization point and works well with random initialization. Simulation results are provided to illustrate the effectiveness of the proposed algorithm.
Simultaneous Block-Sparse Signal Recovery Using Pattern-Coupled Sparse Bayesian Learning
Nov 06, 2017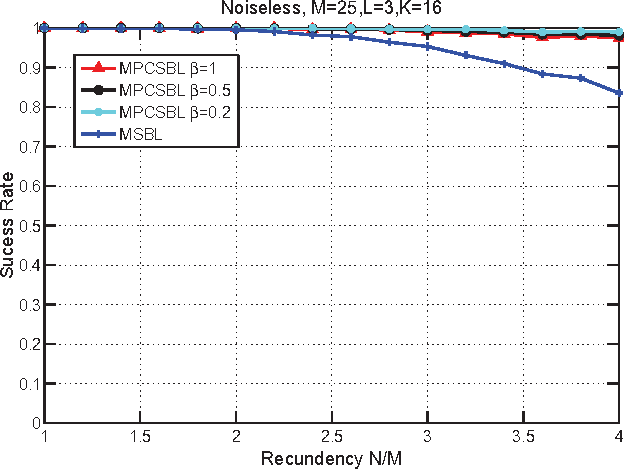
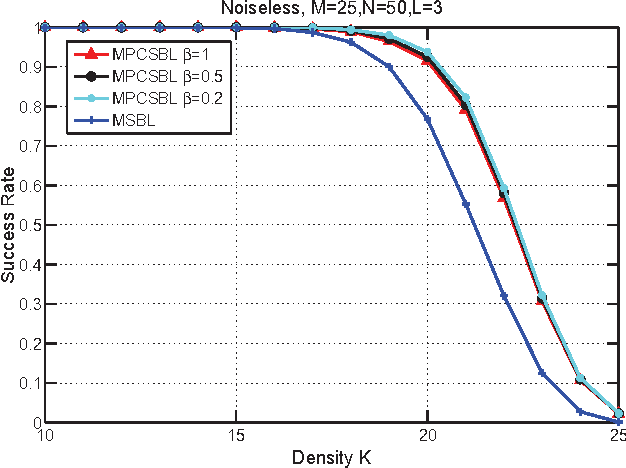
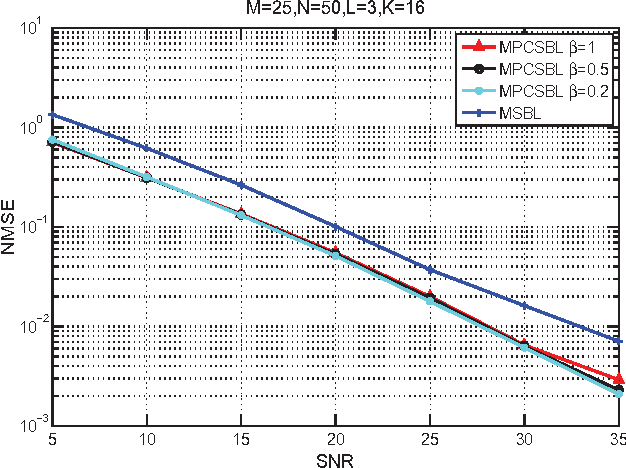
In this paper, we consider the block-sparse signals recovery problem in the context of multiple measurement vectors (MMV) with common row sparsity patterns. We develop a new method for recovery of common row sparsity MMV signals, where a pattern-coupled hierarchical Gaussian prior model is introduced to characterize both the block-sparsity of the coefficients and the statistical dependency between neighboring coefficients of the common row sparsity MMV signals. Unlike many other methods, the proposed method is able to automatically capture the block sparse structure of the unknown signal. Our method is developed using an expectation-maximization (EM) framework. Simulation results show that our proposed method offers competitive performance in recovering block-sparse common row sparsity pattern MMV signals.
Fast Low-Rank Bayesian Matrix Completion with Hierarchical Gaussian Prior Models
Aug 26, 2017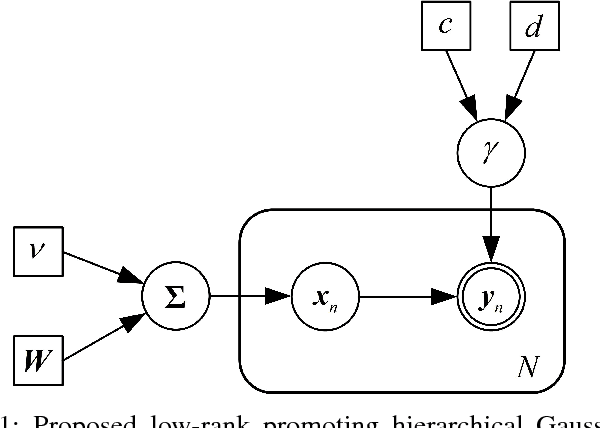
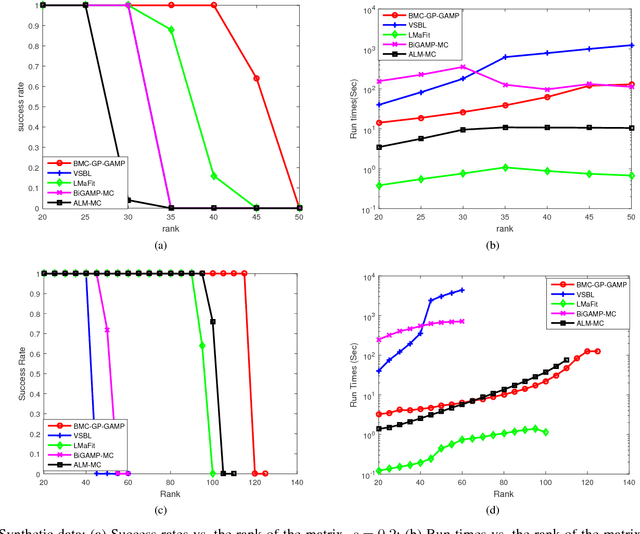


The problem of low rank matrix completion is considered in this paper. To exploit the underlying low-rank structure of the data matrix, we propose a hierarchical Gaussian prior model, where columns of the low-rank matrix are assumed to follow a Gaussian distribution with zero mean and a common precision matrix, and a Wishart distribution is specified as a hyperprior over the precision matrix. We show that such a hierarchical Gaussian prior has the potential to encourage a low-rank solution. Based on the proposed hierarchical prior model, a variational Bayesian method is developed for matrix completion, where the generalized approximate massage passing (GAMP) technique is embedded into the variational Bayesian inference in order to circumvent cumbersome matrix inverse operations. Simulation results show that our proposed method demonstrates superiority over existing state-of-the-art matrix completion methods.
An Iterative Reweighted Method for Tucker Decomposition of Incomplete Multiway Tensors
Nov 15, 2015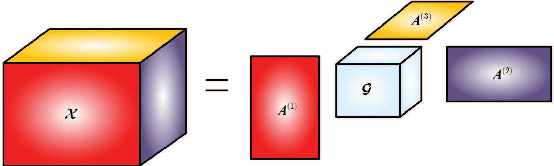
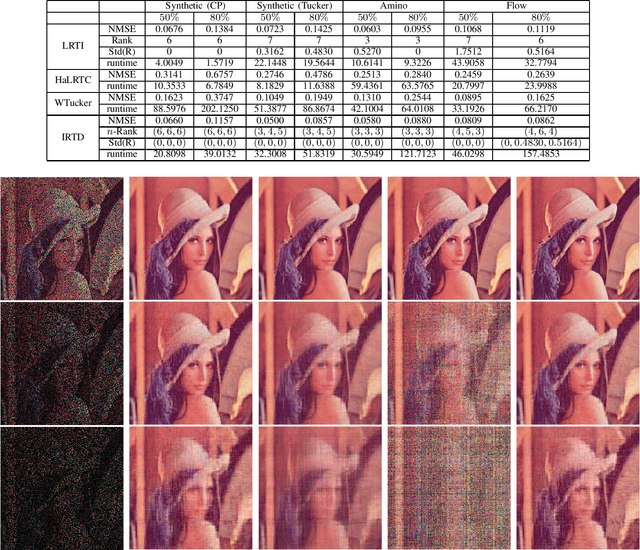
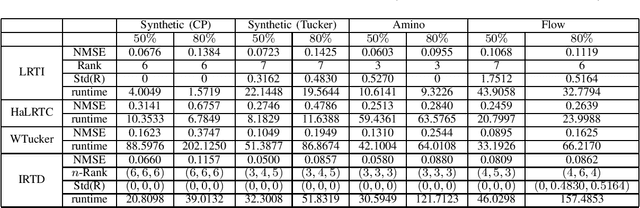
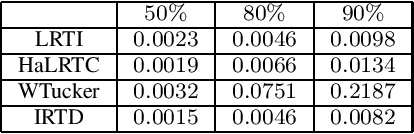
We consider the problem of low-rank decomposition of incomplete multiway tensors. Since many real-world data lie on an intrinsically low dimensional subspace, tensor low-rank decomposition with missing entries has applications in many data analysis problems such as recommender systems and image inpainting. In this paper, we focus on Tucker decomposition which represents an Nth-order tensor in terms of N factor matrices and a core tensor via multilinear operations. To exploit the underlying multilinear low-rank structure in high-dimensional datasets, we propose a group-based log-sum penalty functional to place structural sparsity over the core tensor, which leads to a compact representation with smallest core tensor. The method for Tucker decomposition is developed by iteratively minimizing a surrogate function that majorizes the original objective function, which results in an iterative reweighted process. In addition, to reduce the computational complexity, an over-relaxed monotone fast iterative shrinkage-thresholding technique is adapted and embedded in the iterative reweighted process. The proposed method is able to determine the model complexity (i.e. multilinear rank) in an automatic way. Simulation results show that the proposed algorithm offers competitive performance compared with other existing algorithms.
Sparse Bayesian Dictionary Learning with a Gaussian Hierarchical Model
Mar 07, 2015
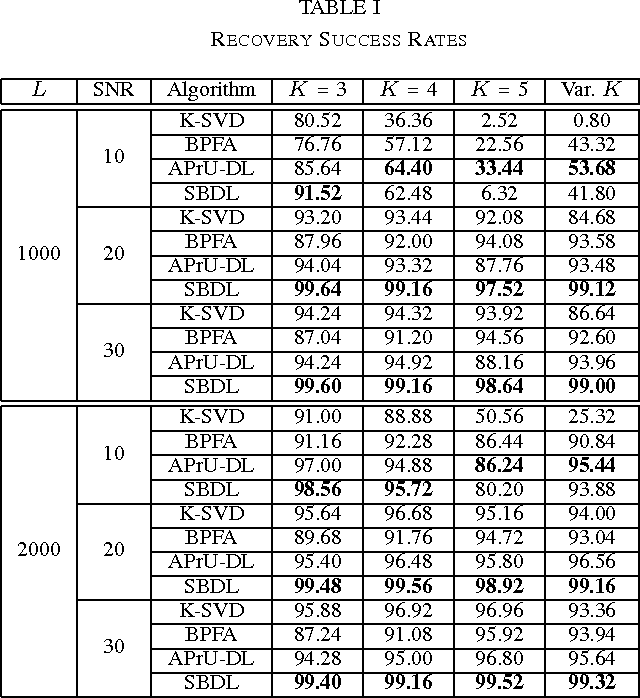
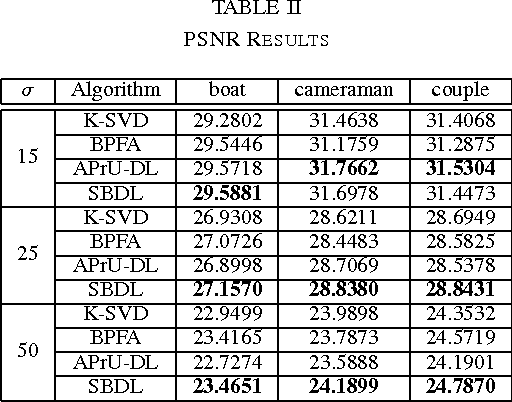
We consider a dictionary learning problem whose objective is to design a dictionary such that the signals admits a sparse or an approximate sparse representation over the learned dictionary. Such a problem finds a variety of applications such as image denoising, feature extraction, etc. In this paper, we propose a new hierarchical Bayesian model for dictionary learning, in which a Gaussian-inverse Gamma hierarchical prior is used to promote the sparsity of the representation. Suitable priors are also placed on the dictionary and the noise variance such that they can be reasonably inferred from the data. Based on the hierarchical model, a variational Bayesian method and a Gibbs sampling method are developed for Bayesian inference. The proposed methods have the advantage that they do not require the knowledge of the noise variance \emph{a priori}. Numerical results show that the proposed methods are able to learn the dictionary with an accuracy better than existing methods, particularly for the case where there is a limited number of training signals.