 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conversational Paradigm for Program Synthesis
Mar 30, 2022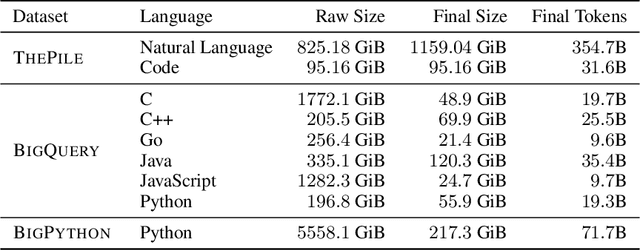
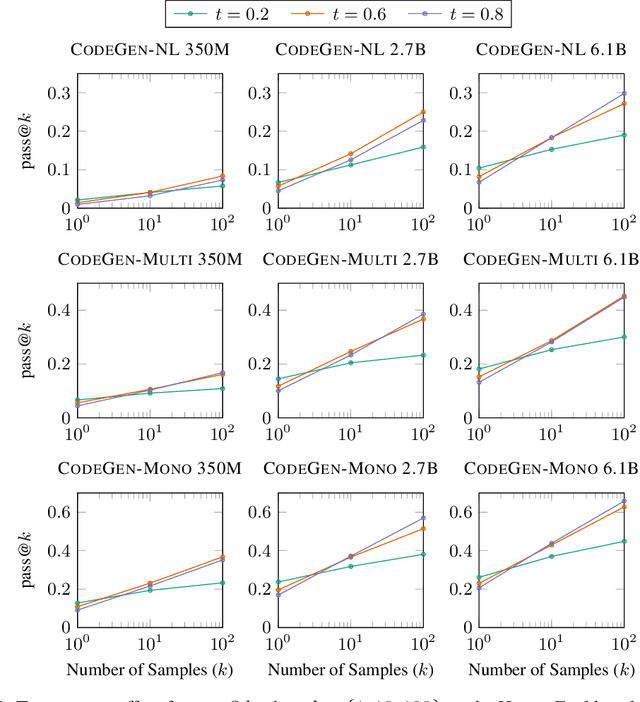
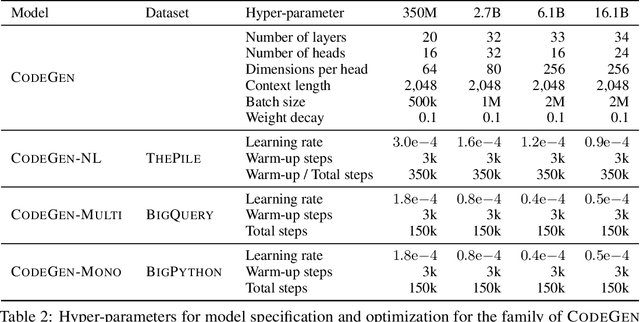
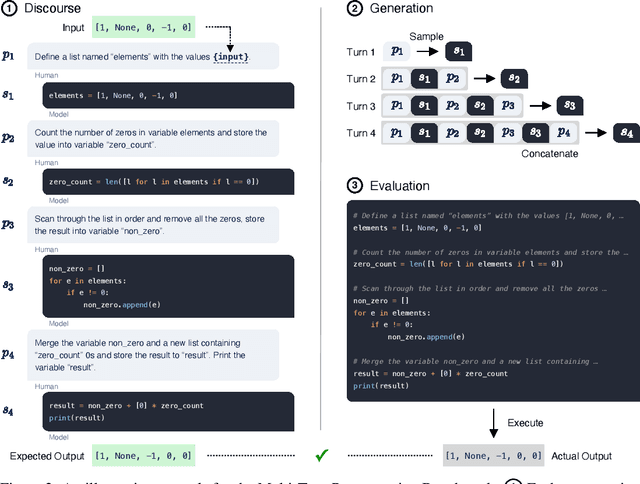
Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: https://github.com/salesforce/CodeGen.
Learning Energy-Based Approximate Inference Networks for Structured Applications in NLP
Aug 27, 2021
Structured prediction in natural language processing (NLP) has a long history. The complex models of structured application come at the difficulty of learning and inference. These difficulties lead researchers to focus more on models with simple structure components (e.g., local classifier). Deep representation learning has become increasingly popular in recent years. The structure components of their method, on the other hand, are usually relatively simple. We concentrate on complex structured models in this dissertation. We provide a learning framework for complicated structured models as well as an inference method with a better speed/accuracy/search error trade-off. The dissertation begins with a general introduction to energy-based models. In NLP and other applications, an energy function is comparable to the concept of a scoring function. In this dissertation, we discuss the concept of the energy function and structured models with different energy functions. Then, we propose a method in which we train a neural network to do argmax inference under a structured energy function, referring to the trained networks as "inference networks" or "energy-based inference networks". We then develop ways of jointly learning energy functions and inference networks using an adversarial learning framework. Despite the inference and learning difficulties of energy-based models, we present approaches in this thesis that enable energy-based models more easily to be applied in structured NLP applications.
An Exploration of Arbitrary-Order Sequence Labeling via Energy-Based Inference Networks
Oct 06, 2020
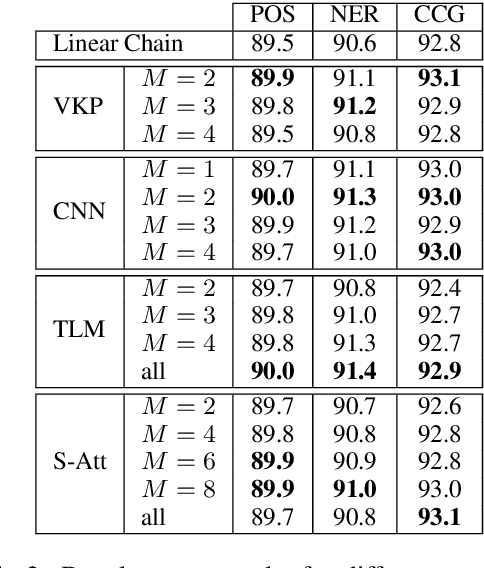
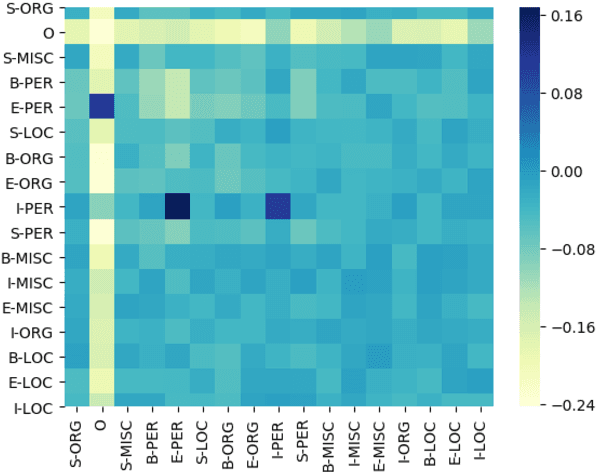
Many tasks in natural language processing involve predicting structured outputs, e.g., sequence labeling, semantic role labeling, parsing, and machine translation. Researchers are increasingly applying deep representation learning to these problems, but the structured component of these approaches is usually quite simplistic. In this work, we propose several high-order energy terms to capture complex dependencies among labels in sequence labeling, including several that consider the entire label sequence. We use neural parameterizations for these energy terms, drawing from convolutional, recurrent, and self-attention networks. We use the framework of learning energy-based inference networks (Tu and Gimpel, 2018) for dealing with the difficulties of training and inference with such models. We empirically demonstrate that this approach achieves substantial improvement using a variety of high-order energy terms on four sequence labeling tasks, while having the same decoding speed as simple, local classifiers. We also find high-order energies to help in noisy data conditions.
An Empirical Study on Robustness to Spurious Correlations using Pre-trained Language Models
Aug 11, 2020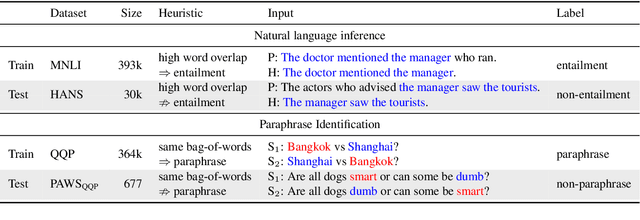
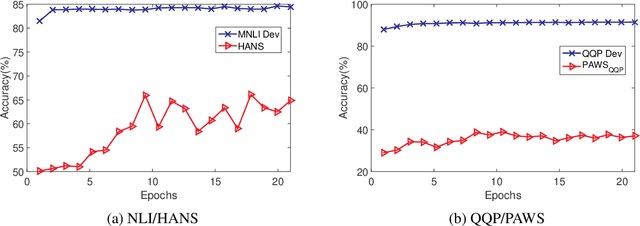
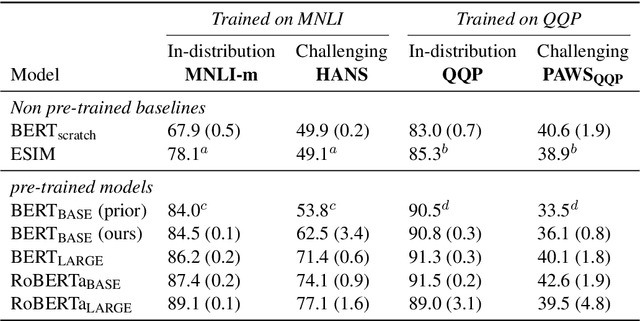
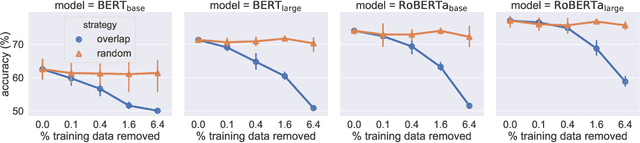
Recent work has shown that pre-trained language models such as BERT improve robustness to spurious correlations in the dataset. Intrigued by these results, we find that the key to their success is generalization from a small amount of counterexamples where the spurious correlations do not hold. When such minority examples are scarce, pre-trained models perform as poorly as models trained from scratch. In the case of extreme minority, we propose to use multi-task learning (MTL) to improve generalization. Our experiments on natural language inference and paraphrase identification show that MTL with the right auxiliary tasks significantly improves performance on challenging examples without hurting the in-distribution performance. Further, we show that the gain from MTL mainly comes from improved generalization from the minority examples. Our results highlight the importance of data diversity for overcoming spurious correlations.
ENGINE: Energy-Based Inference Networks for Non-Autoregressive Machine Translation
May 12, 2020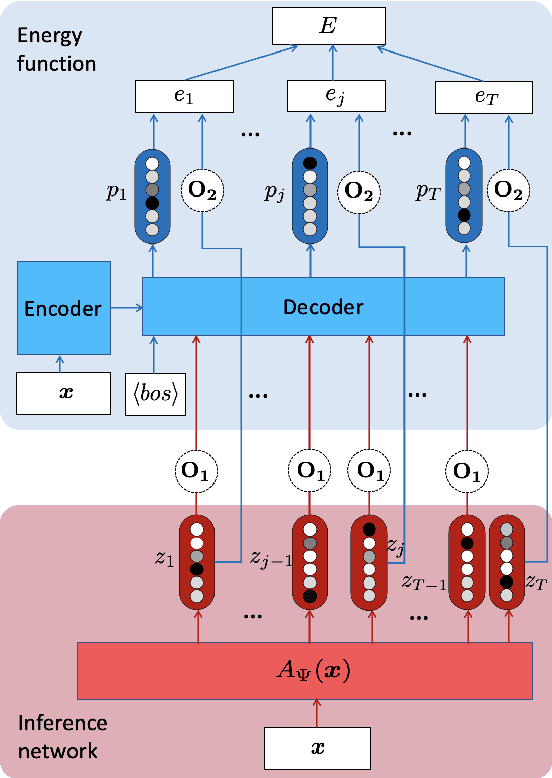
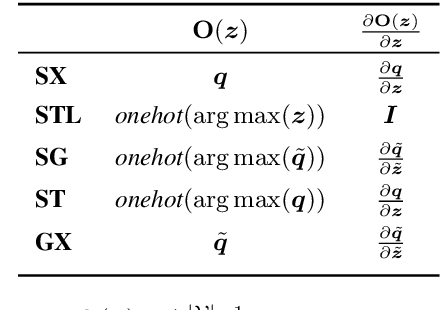

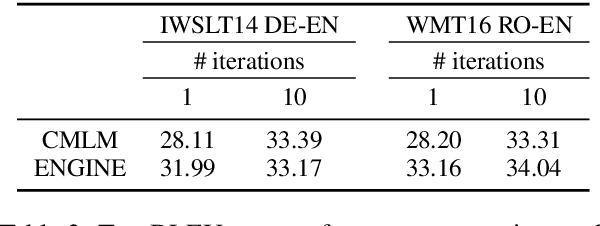
We propose to train a non-autoregressive machine translation model to minimize the energy defined by a pretrained autoregressive model. In particular, we view our non-autoregressive translation system as an inference network (Tu and Gimpel, 2018) trained to minimize the autoregressive teacher energy. This contrasts with the popular approach of training a non-autoregressive model on a distilled corpus consisting of the beam-searched outputs of such a teacher model. Our approach, which we call ENGINE (ENerGy-based Inference NEtworks), achieves state-of-the-art non-autoregressive results on the IWSLT 2014 DE-EN and WMT 2016 RO-EN datasets, approaching the performance of autoregressive models.
Improving Joint Training of Inference Networks and Structured Prediction Energy Networks
Nov 07, 2019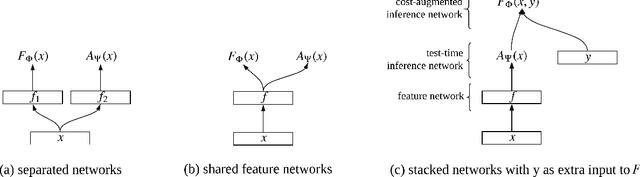
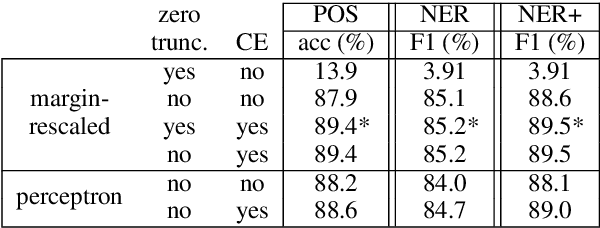
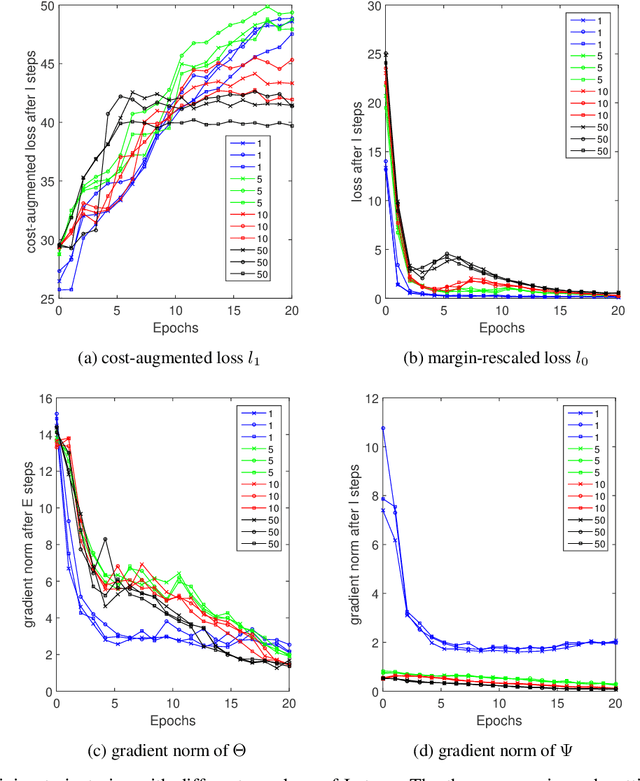
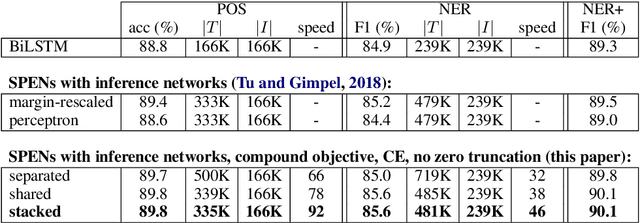
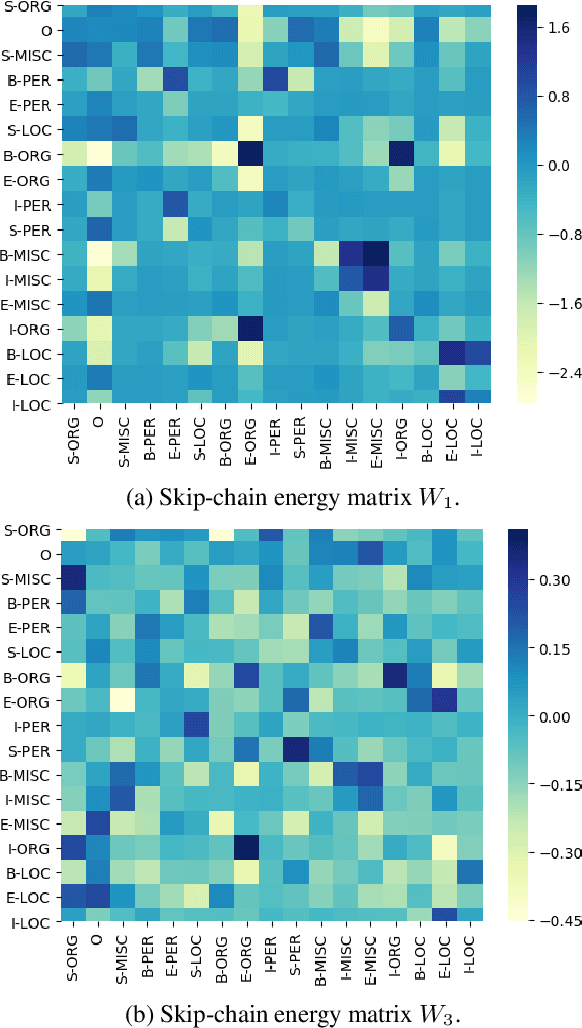
Deep energy-based models are powerful, but pose challenges for learning and inference (Belanger and McCallum, 2016). Tu and Gimpel (2018) developed an efficient framework for energy-based models by training "inference networks" to approximate structured inference instead of using gradient descent. However, their alternating optimization approach suffers from instabilities during training, requiring additional loss terms and careful hyperparameter tuning. In this paper, we contribute several strategies to stabilize and improve this joint training of energy functions and inference networks for structured prediction. We design a compound objective to jointly train both cost-augmented and test-time inference networks along with the energy function. We propose joint parameterizations for the inference networks that encourage them to capture complementary functionality during learning. We empirically validate our strategies on two sequence labeling tasks, showing easier paths to strong performance than prior work, as well as further improvements with global energy terms.
Generating Diverse Story Continuations with Controllable Semantics
Sep 30, 2019
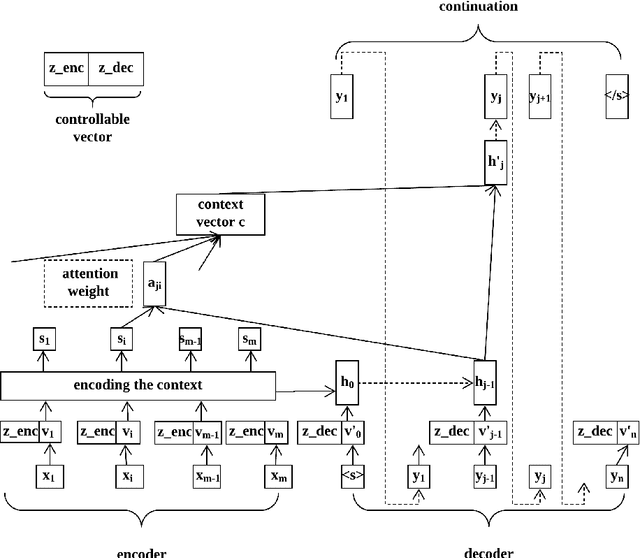
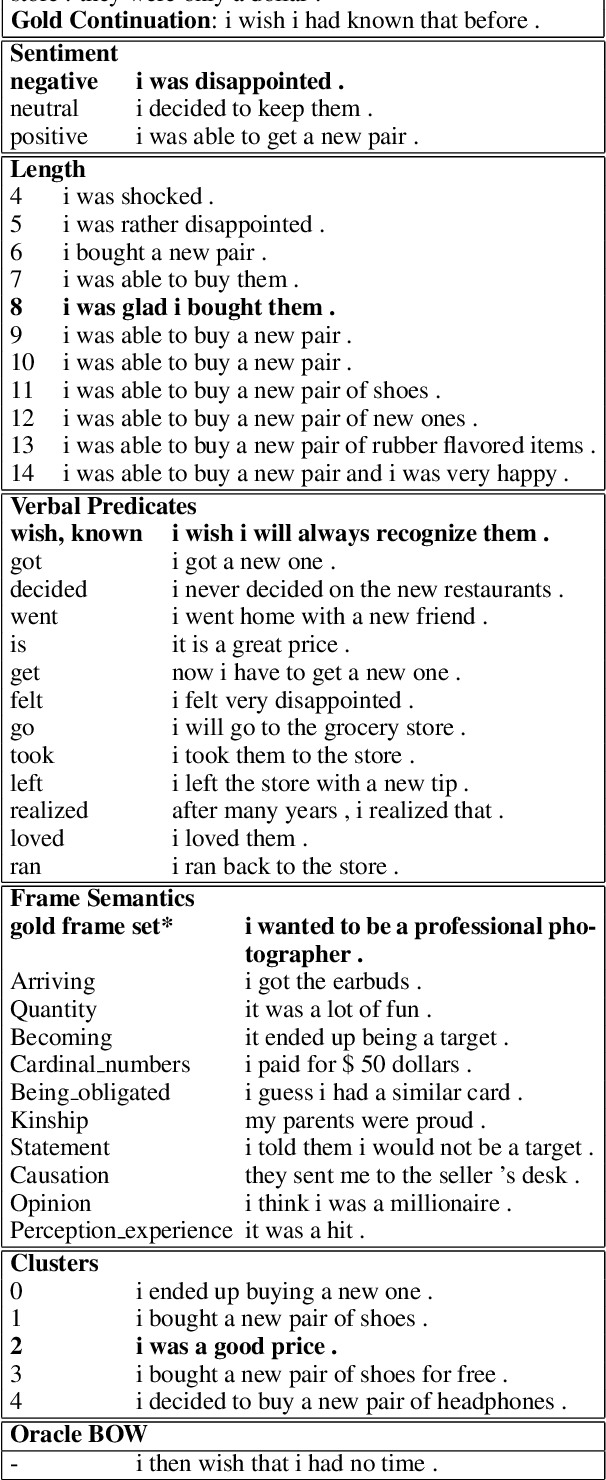
We propose a simple and effective modeling framework for controlled generation of multiple, diverse outputs. We focus on the setting of generating the next sentence of a story given its context. As controllable dimensions, we consider several sentence attributes, including sentiment, length, predicates, frames, and automatically-induced clusters. Our empirical results demonstrate: (1) our framework is accurate in terms of generating outputs that match the target control values; (2) our model yields increased maximum metric scores compared to standard n-best list generation via beam search; (3) controlling generation with semantic frames leads to a stronger combination of diversity and quality than other control variables as measured by automatic metrics. We also conduct a human evaluation to assess the utility of providing multiple suggestions for creative writing, demonstrating promising results for the potential of controllable, diverse generation in a collaborative writing system.
Benchmarking Approximate Inference Methods for Neural Structured Prediction
Apr 01, 2019
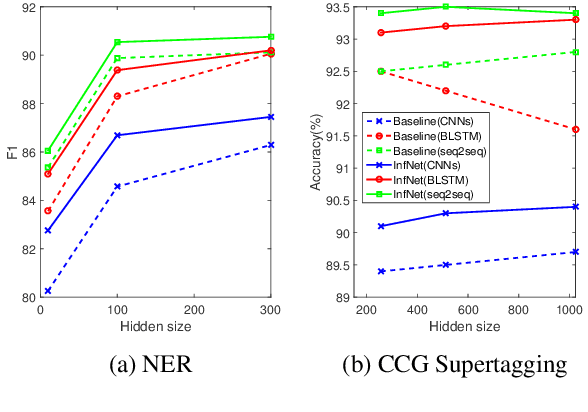
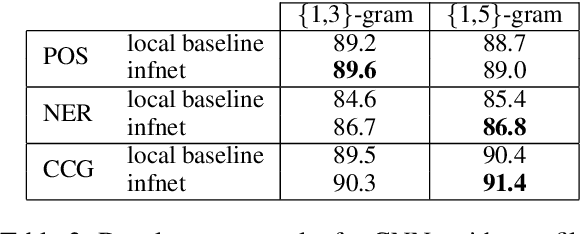
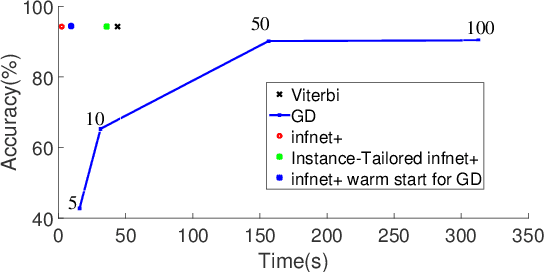
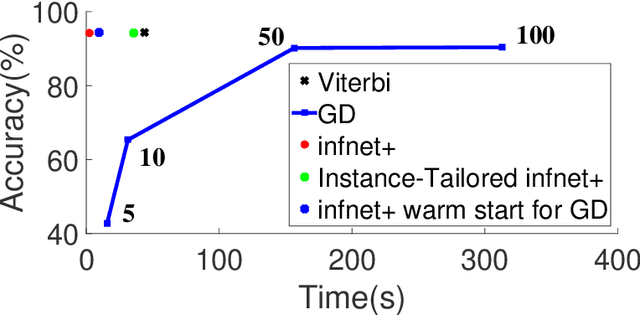
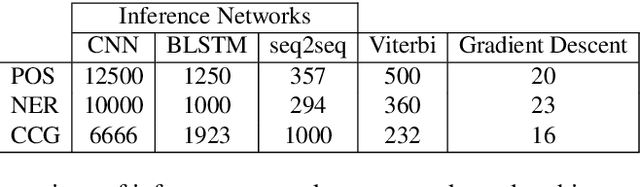
Exact structured inference with neural network scoring functions is computationally challenging but several methods have been proposed for approximating inference. One approach is to perform gradient descent with respect to the output structure directly (Belanger and McCallum, 2016). Another approach, proposed recently, is to train a neural network (an "inference network") to perform inference (Tu and Gimpel, 2018). In this paper, we compare these two families of inference methods on three sequence labeling datasets. We choose sequence labeling because it permits us to use exact inference as a benchmark in terms of speed, accuracy, and search error. Across datasets, we demonstrate that inference networks achieve a better speed/accuracy/search error trade-off than gradient descent, while also being faster than exact inference at similar accuracy levels. We find further benefit by combining inference networks and gradient descent, using the former to provide a warm start for the latter.
Learning Approximate Inference Networks for Structured Prediction
Mar 09, 2018

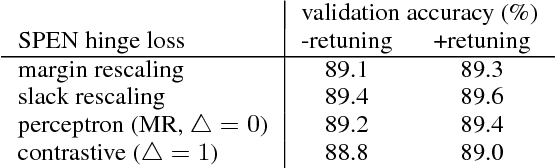

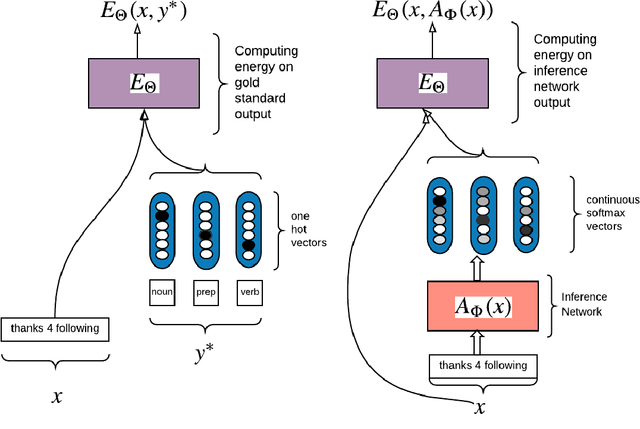
Structured prediction energy networks (SPENs; Belanger & McCallum 2016) use neural network architectures to define energy functions that can capture arbitrary dependencies among parts of structured outputs. Prior work used gradient descent for inference, relaxing the structured output to a set of continuous variables and then optimizing the energy with respect to them. We replace this use of gradient descent with a neural network trained to approximate structured argmax inference. This "inference network" outputs continuous values that we treat as the output structure. We develop large-margin training criteria for joint training of the structured energy function and inference network. On multi-label classification we report speed-ups of 10-60x compared to (Belanger et al, 2017) while also improving accuracy. For sequence labeling with simple structured energies, our approach performs comparably to exact inference while being much faster at test time. We then demonstrate improved accuracy by augmenting the energy with a "label language model" that scores entire output label sequences, showing it can improve handling of long-distance dependencies in part-of-speech tagging. Finally, we show how inference networks can replace dynamic programming for test-time inference in conditional random fields, suggestive for their general use for fast inference in structured settings.
Learning to Embed Words in Context for Syntactic Tasks
Jun 12, 2017


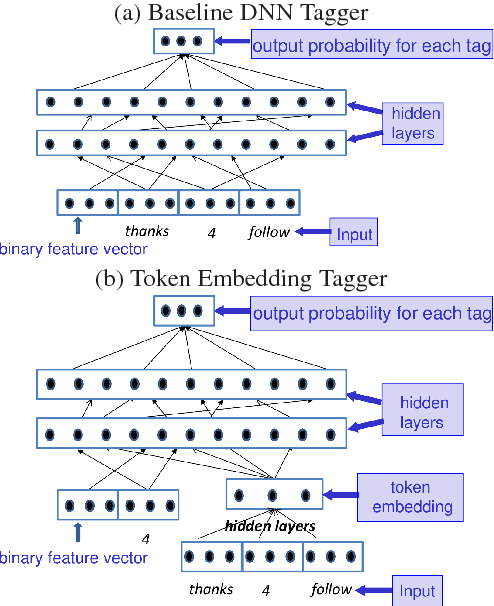
We present models for embedding words in the context of surrounding words. Such models, which we refer to as token embeddings, represent the characteristics of a word that are specific to a given context, such as word sense, syntactic category, and semantic role. We explore simple, efficient token embedding models based on standard neural network architectures. We learn token embeddings on a large amount of unannotated text and evaluate them as features for part-of-speech taggers and dependency parsers trained on much smaller amounts of annotated data. We find that predictors endowed with token embeddings consistently outperform baseline predictors across a range of context window and training set sizes.