 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLPGuard: A Framework for Mitigating the Use of Protected Attributes by NLP Classifiers
Jul 01, 2024



AI regulations are expected to prohibit machine learning models from using sensitive attributes during training. However, the latest Natural Language Processing (NLP) classifiers, which rely on deep learning, operate as black-box systems, complicating the detection and remediation of such misuse. Traditional bias mitigation methods in NLP aim for comparable performance across different groups based on attributes like gender or race but fail to address the underlying issue of reliance on protected attributes. To partly fix that, we introduce NLPGuard, a framework for mitigating the reliance on protected attributes in NLP classifiers. NLPGuard takes an unlabeled dataset, an existing NLP classifier, and its training data as input, producing a modified training dataset that significantly reduces dependence on protected attributes without compromising accuracy. NLPGuard is applied to three classification tasks: identifying toxic language, sentiment analysis, and occupation classification. Our evaluation shows that current NLP classifiers heavily depend on protected attributes, with up to $23\%$ of the most predictive words associated with these attributes. However, NLPGuard effectively reduces this reliance by up to $79\%$, while slightly improving accuracy.
Social Interactions or Business Transactions? What customer reviews disclose about Airbnb marketplace
Apr 24, 2020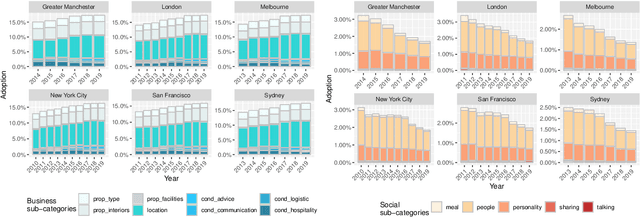
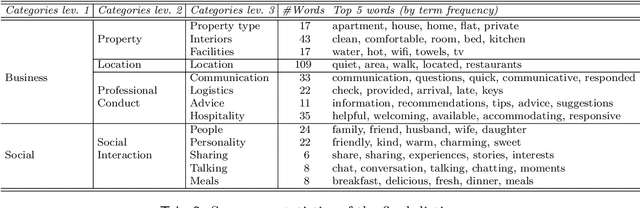
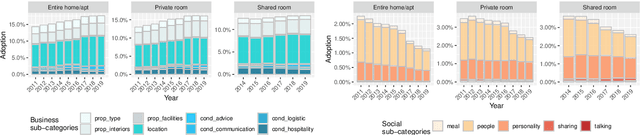
Airbnb is one of the most successful examples of sharing economy marketplaces. With rapid and global market penetration, understanding its attractiveness and evolving growth opportunities is key to plan business decision making. There is an ongoing debate, for example, about whether Airbnb is a hospitality service that fosters social exchanges between hosts and guests, as the sharing economy manifesto originally stated, or whether it is (or is evolving into being) a purely business transaction platform, the way hotels have traditionally operated. To answer these questions, we propose a novel market analysis approach that exploits customers' reviews. Key to the approach is a method that combines thematic analysis and machine learning to inductively develop a custom dictionary for guests' reviews. Based on this dictionary, we then use quantitative linguistic analysis on a corpus of 3.2 million reviews collected in 6 different cities, and illustrate how to answer a variety of market research questions, at fine levels of temporal, thematic, user and spatial granularity, such as (i) how the business vs social dichotomy is evolving over the years, (ii) what exact words within such top-level categories are evolving, (iii) whether such trends vary across different user segments and (iv) in different neighbourhoods.
Community Question Answering Platforms vs. Twitter for Predicting Characteristics of Urban Neighbourhoods
Jan 17, 2017
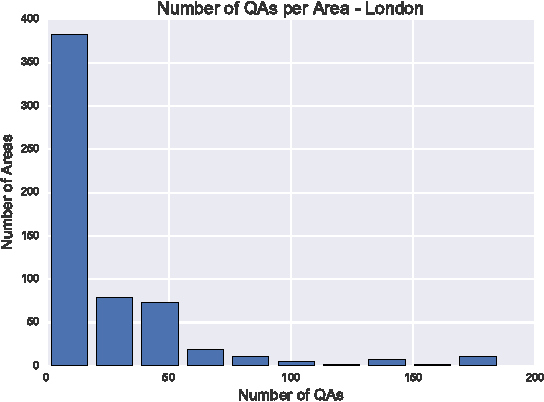
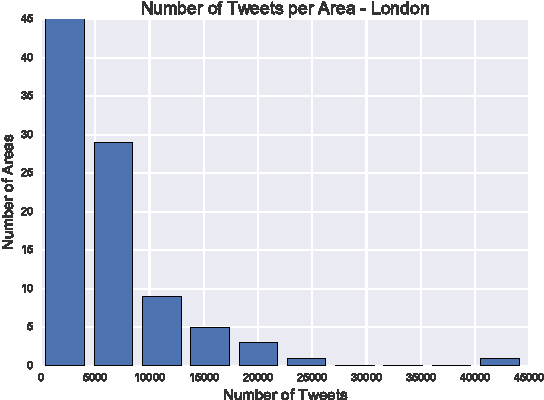
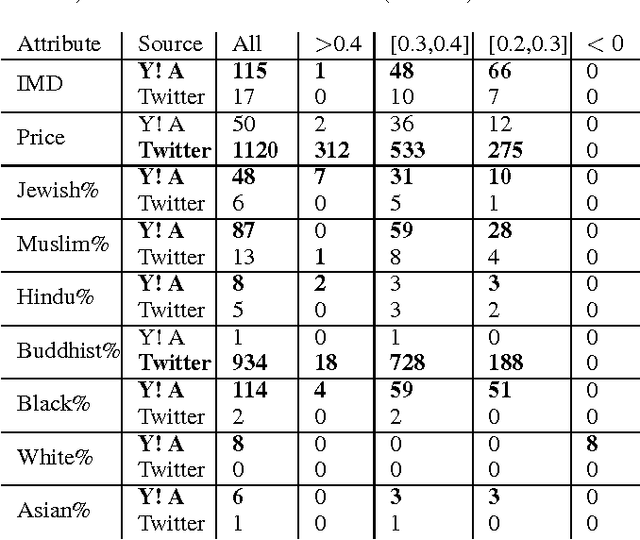
In this paper, we investigate whether text from a Community Question Answering (QA) platform can be used to predict and describe real-world attributes. We experiment with predicting a wide range of 62 demographic attributes for neighbourhoods of London. We use the text from QA platform of Yahoo! Answers and compare our results to the ones obtained from Twitter microblogs. Outcomes show that the correlation between the predicted demographic attributes using text from Yahoo! Answers discussions and the observed demographic attributes can reach an average Pearson correlation coefficient of \r{ho} = 0.54, slightly higher than the predictions obtained using Twitter data. Our qualitative analysis indicates that there is semantic relatedness between the highest correlated terms extracted from both datasets and their relative demographic attributes. Furthermore, the correlations highlight the different natures of the information contained in Yahoo! Answers and Twitter. While the former seems to offer a more encyclopedic content, the latter provides information related to the current sociocultural aspects or phenomena.